深度学习中的计算机视觉
Reference
学习深度学习中的视觉信息表示 计算机视觉四大基本任务(分类、定位、检测、分割) | 包含网络综述DenseNet, UNet等
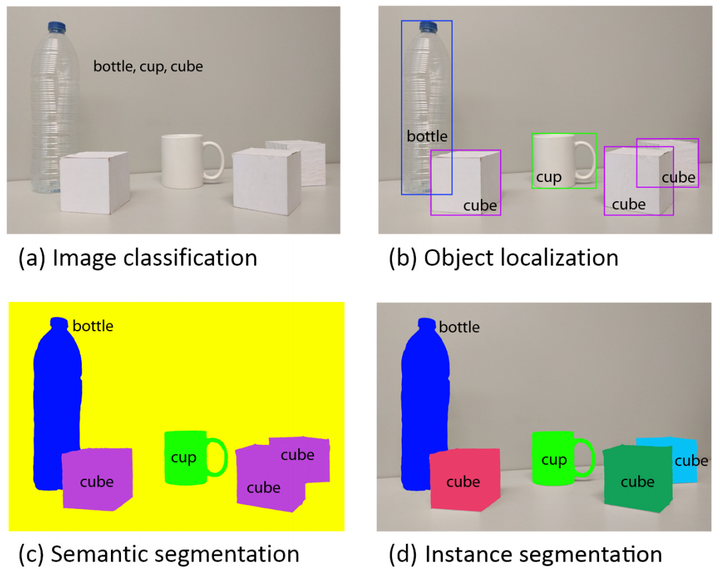
CV的基本任务
如今,互联网上超过70%的数据是图像/视频,全世界的监控摄像头数目已超过人口数,每天有超过八亿小时的监控视频数据生成。如此大的数据量亟待自动化的视觉理解与分析技术。
计算机视觉的难点在于语义鸿沟。
语义鸿沟(semantic gap) 人类可以轻松地从图像中识别出目标,而计算机看到的图像只是一组0到255之间的整数。
计算机视觉任务的其他困难 拍摄视角变化、目标占据图像的比例变化、光照变化、背景融合、目标形变、遮挡等。
计算机视觉的顶级会议和期刊 顶级会议有CVPR、ICCV、和ECCV,此外ICLR也有不少计算机视觉论文。顶级期刊有IJCV和TPAMI。由于计算机视觉领域发展十分迅速,不论身处学术界或产业界,通过阅读顶级会议和期刊论文了解计算机视觉的最近研究成果都十分必要。
为什么要学习计算机视觉?
一个显而易见的答案就是,这个研究领域已经衍生出了一大批快速成长的、有实际作用的应用,例如:
人脸识别: Snapchat 和 Facebook 使用人脸检测算法来识别人脸。
图像检索:Google Images 使用基于内容的查询来搜索相关图片,算法分析查询图像中的内容并根据最佳匹配内容返回结果。
游戏和控制:使用立体视觉较为成功的游戏应用产品是:微软 Kinect。
监测:用于监测可疑行为的监视摄像头遍布于各大公共场所中。
生物识别技术:指纹、虹膜和人脸匹配仍然是生物识别领域的一些常用方法。
智能汽车:计算机视觉仍然是检测交通标志、灯光和其他视觉特征的主要信息来源。
对象检测
在对象检测中,你只有 2 个对象分类类别,即对象边界框和非对象边界框。
如果使用图像分类和定位图像这样的滑动窗口技术,但是这需要很大的计算量!
为了解决这一问题,神经网络研究人员建议使用区域(region)这一概念,这样我们就会找到可能包含对象的“斑点”图像区域,这样运行速度就会大大提高。
R-CNN

第一种模型是基于区域的卷积神经网络( R-CNN ),其算法原理如下:
- 在 R-CNN 中,首先使用选择性搜索算法扫描输入图像,寻找其中的可能对象,从而生成大约 2,000 个区域建议;
- 然后,在这些区域建议上运行一个 卷积神网络;
- 最后,将每个卷积神经网络的输出传给支持向量机( SVM ),使用一个线性回归收紧对象的边界框。
实质上,我们将对象检测转换为一个图像分类问题。但是也存在这些问题:训练速度慢,需要大量的磁盘空间,推理速度也很慢。
Fast R-CNN

R-CNN 的第一个升级版本是 Fast R-CNN,通过使用了 2 次增强,大大提了检测速度:
- 在建议区域之前进行特征提取,因此在整幅图像上只能运行一次卷积神经网络;
- 用一个 softmax 层代替支持向量机,对用于预测的神经网络进行扩展,而不是创建一个新的模型。
但是,择性搜索算法生成区域提议仍然要花费大量时间。
Faster R-CNN
Faster R-CNN 是基于深度学习对象检测的一个典型案例。
该算法用一个快速神经网络代替了运算速度很慢的选择性搜索算法:通过插入区域提议网络( RPN ),来预测来自特征的建议。 RPN 决定查看“哪里”,这样可以减少整个推理过程的计算量。
RPN 快速且高效地扫描每一个位置,来评估在给定的区域内是否需要作进一步处理,其实现方式如下:通过输出 k 个边界框建议,每个边界框建议都有 2 个值——代表每个位置包含目标对象和不包含目标对象的概率。

一旦我们有了区域建议,就直接将它们送入 Fast R-CNN 。 并且,我们还添加了一个池化层、一些全连接层、一个 softmax 分类层以及一个边界框回归器。
总之,Faster R-CNN 的速度和准确度更高。Faster R-CNN 可能不是最简单或最快速的目标检测方法,但仍然是性能最好的方法之一。
近年来,主要的目标检测算法已经转向更快、更高效的检测系统。这种趋势在 You Only Look Once(YOLO),Single Shot MultiBox Detector(SSD)和基于区域的全卷积网络( R-FCN )算法中尤为明显,这三种算法转向在整个图像上共享计算。因此,这三种算法和上述的3种造价较高的R-CNN 技术有所不同。
Visual Representation
深度学习中的表示学习_Representation Learninghttps://blog.csdn.net/u010417185/article/details/83089882
图像特征提取(Feature Extraction)和视觉信息表示(Visual Representation)的区别
图像特征提取(Feature Extraction)和视觉信息表示(Visual Representation)实际上是一回事情,特征提取更多的是指传统的方法,而视觉信息表示是深度学习来临之后的流行说法
深度学习出现后带来了一个新的方法论,就是如何设计一个任务,使得完成这个任务的神经网络有好的识别信息表示,因为深度学习,只要定义好输入(x)和输出(y),也就是定义好任务,并且给出大量的样本,这里每一个样本都是这个任务的一个带有这个任务的标准答案的例子,深度学习就很很容易训练一个把输入(x)转化为输出(y)的神经网络。
基于人工标注的监督学习框架的局限性基于人工标注的监督学习框架的局限性
第1个问题:依赖人工标注的监督学习使得进一步增大数据量非常困难
第2个问题:分类任务和人为的标准本身有很多模棱两可的情况,而且跟最终最终应用不一定相关。
第3个问题:通过静态的图像分类来学习到的视觉信息表示,可能会缺乏一些结构化和动态的信息。
-
Previous
(3dcnn)Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks -
Next
论文学习 20_(hinton|cl)a simple framework for contrastive learning of visual representations?