20CVPR(Hinton)A Simple Framework for Contrastive Learning of Visual Representations
提出SimCLR: 可用于视觉表示的一种对比学习(Contrastive Learning) 的简单框架
- 用的是对比损失函数, 最小化正对间距离, 最大化负对间距离
- 自监督学习: 标签产生方式不同
与度量学习结合, 训练网络
- 无监督的方式学习表示网络(度量网络)
- 卷积神经网络提取特征
- 少量样本微调网络
样本增强方式
- 随机裁剪
- 颜色增强
主要工作:
-
我们简化了最近提出的的对比自监督学习算法, 使其无需专门的架构或存储库 。
-
为了了解什么使对比预测任务能够学习有用的表示形式,我们系统地研究了框架的主要组成部分。
-
提出了如下主要结论 :
- 多个数据扩充方法的组合与数据增强非常重要, 尤其使用无监督学习方法时
-
在表示 (特征) 和对比损失间引入可学习的非线性变换可以大幅度提高模型学到的表示的质量
- 对于对比学习更大的批处理数量和更多的训练次数的重要性
使用通过Sim-CLR自监督学习到的表示来训练线性分类器得到的效果:
- 大幅胜过ImageNet上先前用于自监督和半监督学习的先前方法。可达到76.5%的top-1准确性,与最新技术相比相对提高了7%.
- 与监督的ResNet-50的性能相匹配。 在仅使用 1% 的 ImageNet 标签进行微调时,SimCLR 实现了 85.8% 的 top-5 准确率,比之前的 SOTA 方法提升了 10%。
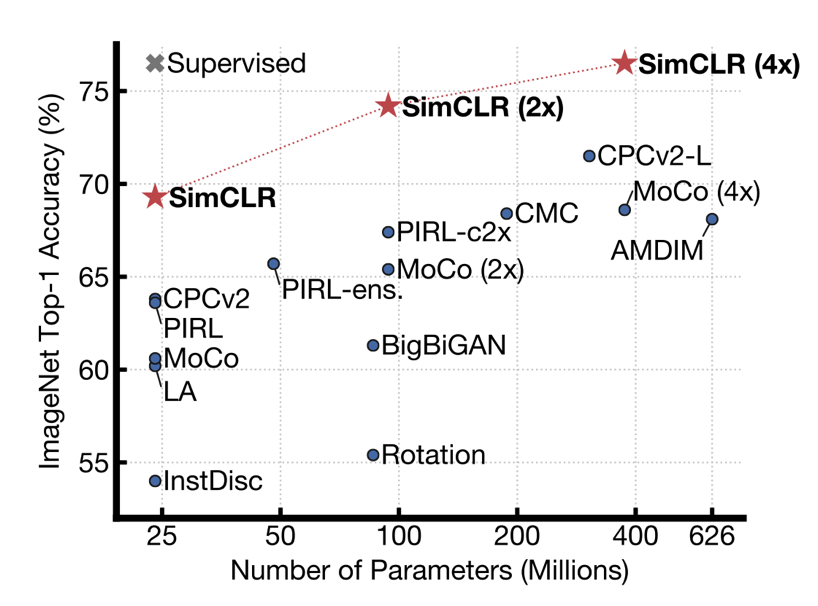
图为SimCLR 与此前各类自监督方法在 ImageNet 上的 Top-1 准确率对比(以 ImageNet 进行预训练),以及 ResNet-50 的有监督学习效果(灰色×)
自监督学习
-
训练数据集 – 不是由人手动标记的,每个样本的标签是通过利用输入的相关性生成的(如来自不同的传感器模式)。
-
标签 – 通常来自于数据本身: 即模型直接从无标签数据中自行学习,无需标注数据。
-
训练 – 通过使用各种辅助任务 (auxiliary task ) 训练网络, 来提高学习表征 (representation) 的质量.
-
核心 – 如何自动为数据产生标签。如随机旋转, 均匀分割而自动产生的标注
-
性能评价 – 通过模型学出来的feature的质量来评价. feature质量是通过迁移学习的方式,把feature用到其它视觉任务中通过结果的好坏来评价。

Q: 到底使用了多少标签和准确率
Q: 自监督和无监督的区别
自监督与无监督相同之处是都不需要使用人工标注标签, 不同之处是自监督使用辅助任务产生标签, 从而达到类似于有监督的训练过程.
Q: 怎么理解”既不需要专门的架构,也不需要特殊的存储库。”
Q: 无监督表示学习??/啥意思
A: 只是学习一个视觉表示, 然后再用线性分类器分类?????
评价
SimCLR 是一种简单而清晰的方法,无需类标签即可让 AI 学会视觉表示,而且可以达到有监督学习的准确度。
它不仅优于此前的所有工作,也优于最新的对比自监督学习算法,而且结构更加简单:既不需要专门的架构,也不需要特殊的存储库。
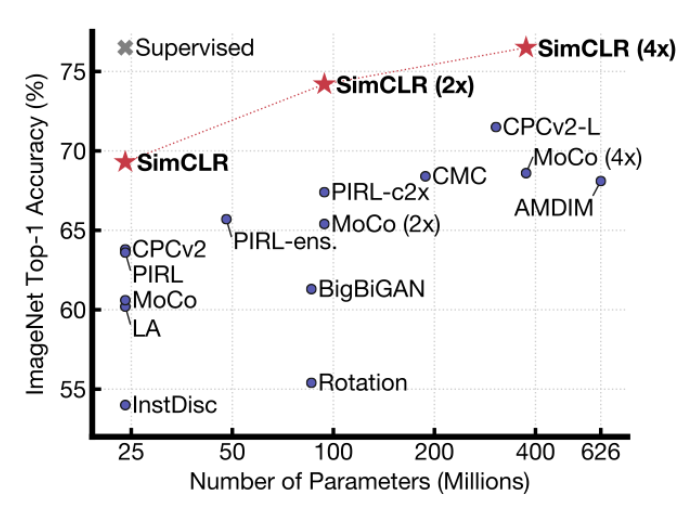
SimCLR 与此前各类自监督方法在 ImageNet 上的 Top-1 准确率对比(以 ImageNet 进行预训练),以及 ResNet-50 的有监督学习效果(灰色×)
基于这些发现,他们在 ImageNet ILSVRC-2012 数据集上实现了一种新的半监督、自监督学习 SOTA 方法——SimCLR。在线性评估方面,SimCLR 实现了 76.5% 的 top-1 准确率,比之前的 SOTA 提升了 7%。在仅使用 1% 的 ImageNet 标签进行微调时,SimCLR 实现了 85.8% 的 top-5 准确率,比之前的 SOTA 方法提升了 10%。在 12 个其他自然图像分类数据集上进行微调时,SimCLR 在 10 个数据集上表现出了与强监督学习基线相当或更好的性能。
无监督学习的快速发展让科学家们看到了新的希望,DeepMind 科学家 Oriol Vinyals 表示:感谢对比损失函数,无监督学习正在逼近监督学习!
Q: 线性评估是什么
A: 在训练好的基础网络上训练一个线性分类器, 将测试精度作为学习到的表征的质量
where a linear classifier is trained on top of the frozen base net- work, and test accuracy is used as a proxy for representation quality. Beyond linear evaluation, we also compare against state-of-the-art on semi-supervised and transfer learning.
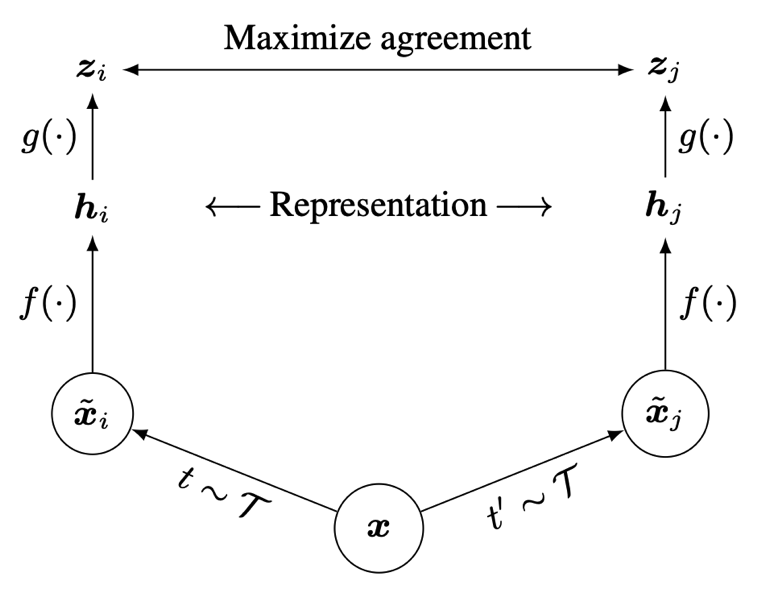
整体流程
SimCLR 通过隐空间中的对比损失来最大化同一数据示例的不同增强视图之间的一致性,从而学习到特征表示。具体说来,这一框架包含四个主要部分:
-
随机数据增强模块
-
基本的神经网络编码器 f(·) – 特征网络
-
神经网络映射头 g(·) – 变换网络
-
对比预测任务的对比损失函数
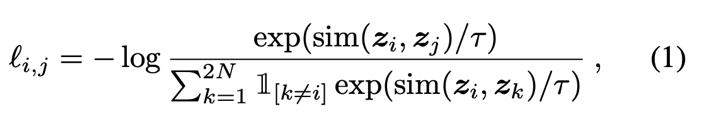 其中,
其中, 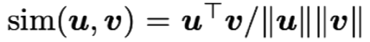
相比之前对比学习模型: 结构更简单, 省去数据存储队列
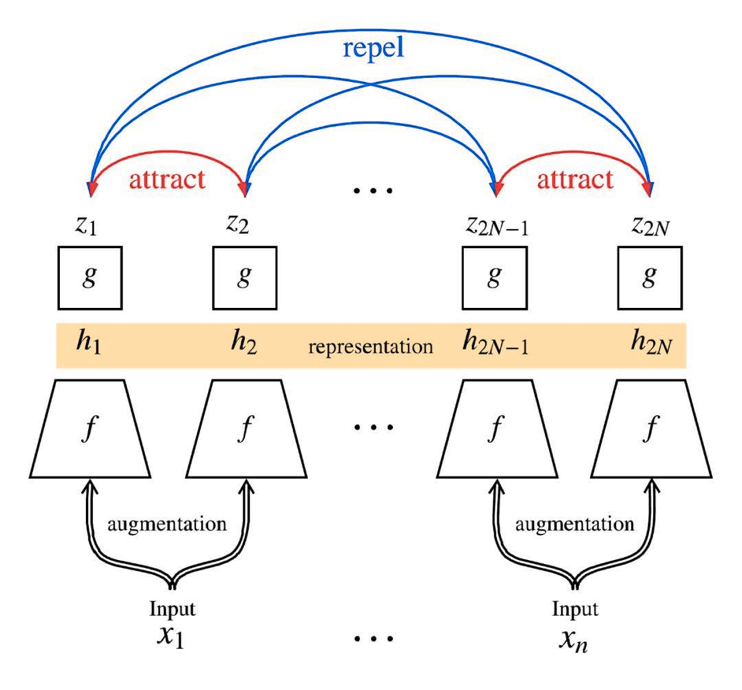
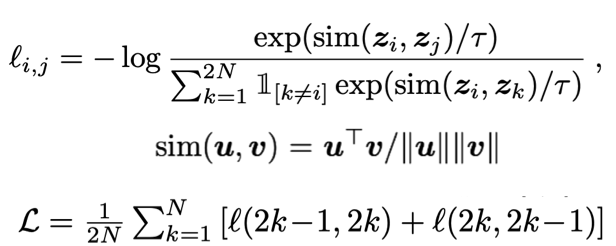
如图, 来自同一图片(x1)的不同增广(z1, z2)互相吸引,它们的特征应该接近(红色的线);
而来自不同图片的增广(例如z1和z2N)互相排斥,它们的特征应该偏离(蓝色的线)。
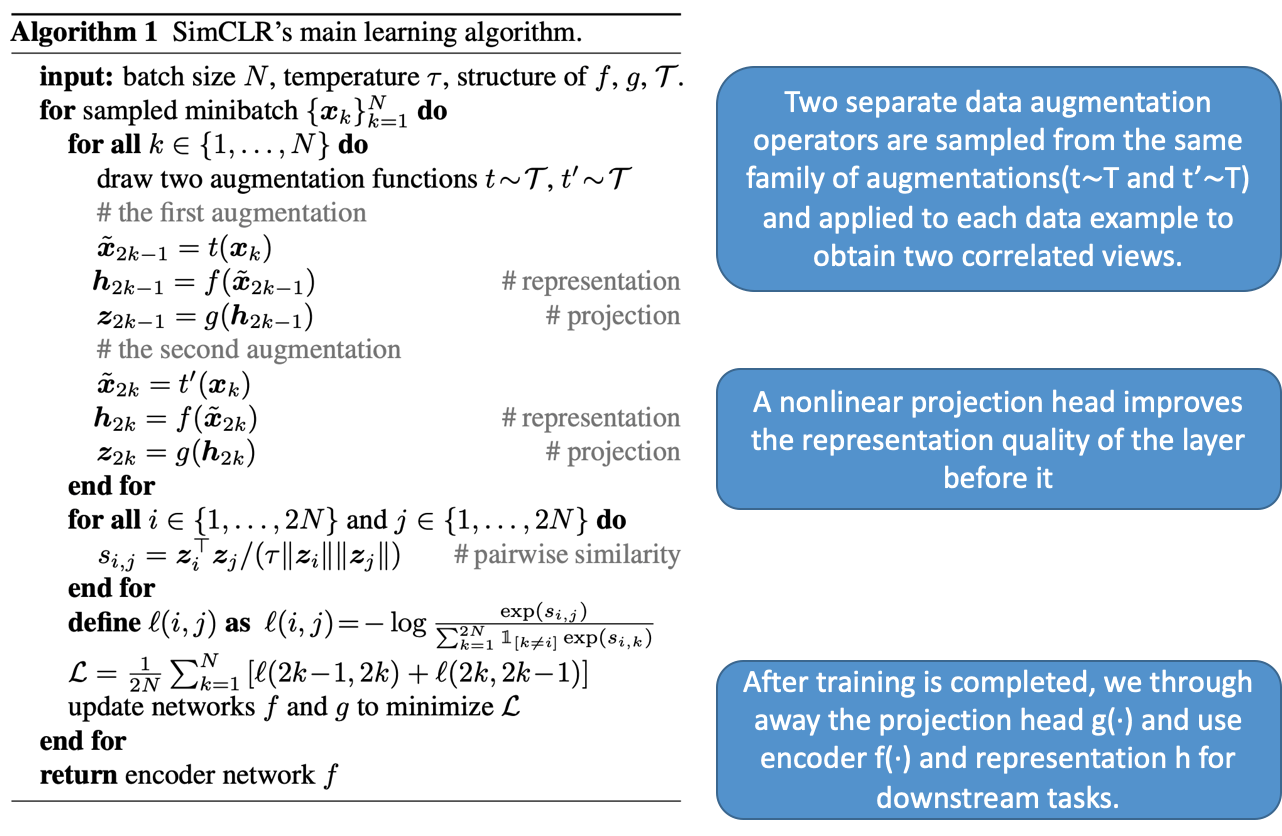
独立的数据增强函数
F g 为可训练的神经网络, 其中每个 f 和每个 g 都是同一个网络
加入这个非线性变换网络也是文章比较创新的地方, 可提高获得的特征表示的质量
学习完特征表示后, 我们将投影头g 拿走,并使用特征网络 f 和represention h 进行后面阶段的任务。
f 是正常的卷积网络 比如文中用的是resnet
投影头g 是liner+relu+liner(非线性变换层)
Q: g用的是什么网络???
网络结构
不同且独立的增强函数$t(x)$
编码器网络(encoder network) $f(·)$, **投射头网络(projection head)$g(·)$**???为可训练的神经网络, 其中每个 f 和每个 g 都是一样的
**利用对比损失来最大化一致性(maximize agreement)训练f, g**, 训练完成后,我们将投影头g 拿走,并使用**编码器网络f**和represention **h** 进行后面阶段的任务。
用更大的批大小进行训练
作者将训练批大小 N 分为 256 到 8192 不等。批大小为 8192 的情况下,增强视图中每个正对(positive pair)都有 16382 个反例。当使用标准的 SGD/动量和线性学习率扩展时,大批量的训练可能不稳定。为了使得训练更加稳定,研究者在所有的批大小中都采用了 LARS 优化器???。**他们使用 Cloud TPU 来训练模型**,根据批大小的不同,使用的核心数从 32 到 128 不等/。
Q: 我们的服务器规模好像不够, 可以使用降维或者什么操作??`
Q: 提取表示向量, 类似度量因子???
Q: LARS 优化器???
数据增强
虽然数据增强已经广泛应用于监督和无监督表示学习,但它还没有被看做一种定义对比学习任务的系统性方法。许多现有的方法通过改变架构来定义对比预测任务。
本文的研究者证明,通过对目标图像执行简单的随机裁剪(调整大小),可以避免之前的复杂操作,从而创建包含上述两项任务的一系列预测任务,如图 3 所示。这种简单的设计选择方便得将预测任务与其他组件(如神经网络架构)解耦。
随机裁剪
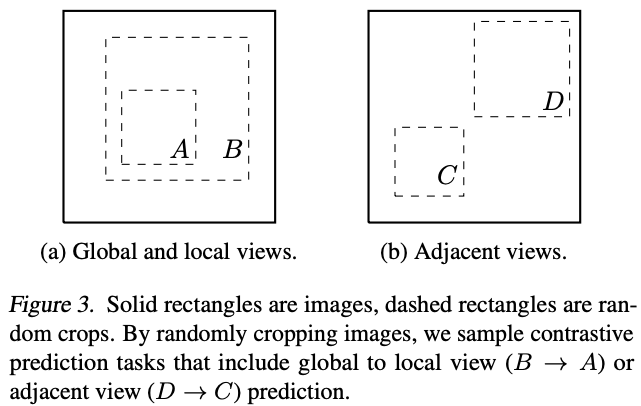
作者研究了一系列数据增广和数据增广的两两组合

Q: 将预测任务与其他组件(如神经网络架构)解耦????。
实验验证
多种数据增强操作的组合是学习良好表示的关键
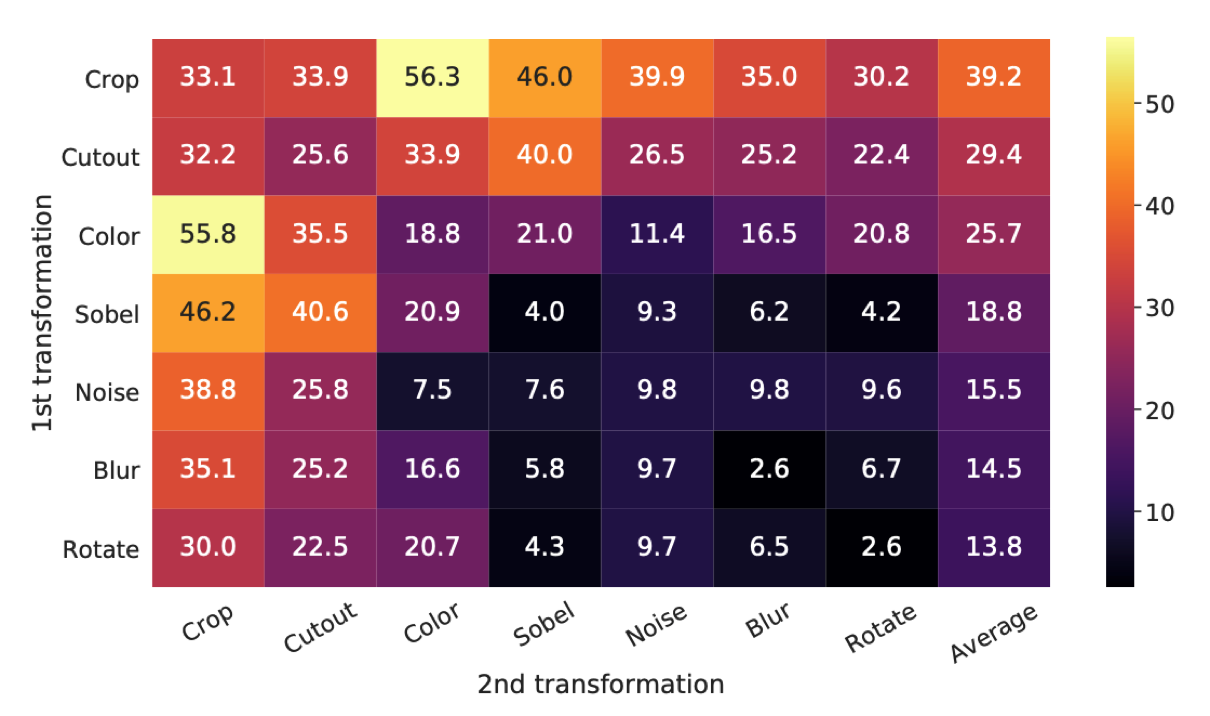
线性评估(ImageNet top-1精度)下的单独或合成的数据增广的实验结果。
颜色增强的重要性???, 如下调整了颜色的强度
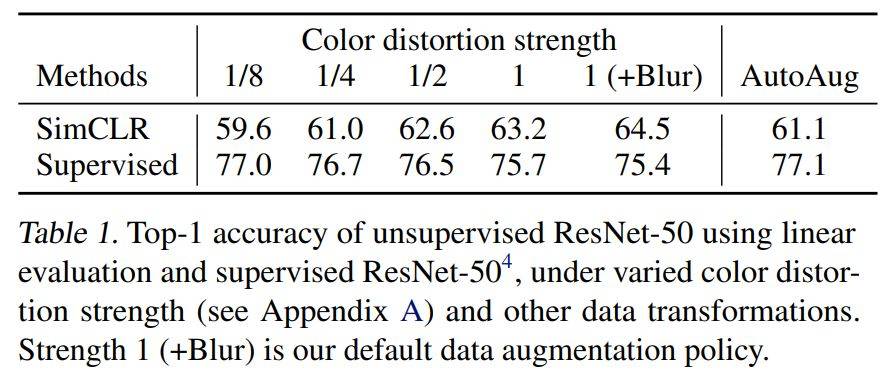
网络结构
•随着模型大小的不断增加,SimCLR(红色的线)带来的提升,要大于监督学习(绿色的线)。说明无监督学习可以更好的利用更大模型的潜力。
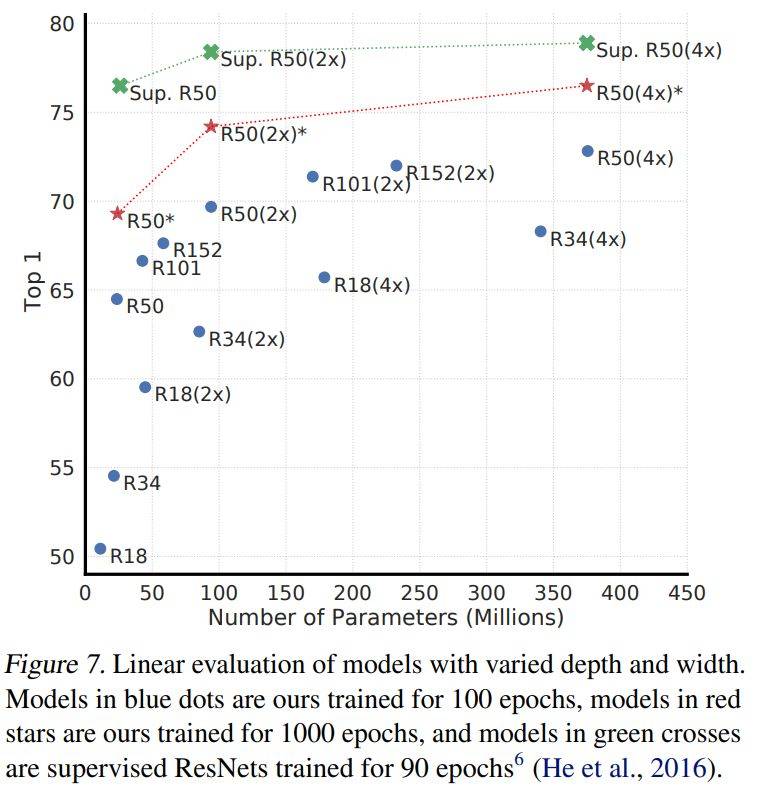
具有不同深度和宽度的模型的线性评价。蓝点上的模型我们训练了100个迭代,红星上的模型我们训练了1000个迭代,绿十字上的模型我们训练了90个迭代
非线性的投射头
•对比可以发现,在特征后面加入一个可学习的非线性变换层 g ,可以极大的提升特征的表达能力。图 8 展示了使用三种不同投射头架构的线性评估结果。
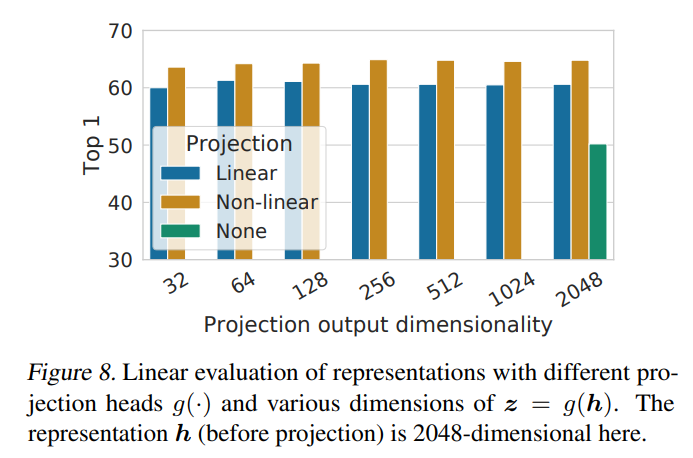
对使用不同种类和不同维度的 变换网络 g 时学习得到的表示的线性评估
损失函数
可调节温度的归一化交叉熵损失比其他方法更佳。研究者对比了 NT-Xent 损失和其他常用的对比损失函数,比如 logistic 损失、margin 损失。表 2 展示了**目标函数和损失函数输入的梯度**????。

Batch size和训练步数
对比学习(Contrastive learning)能从更大的批大小和更长时间的训练中受益更多。图 9 展示了在模型在不同 Epoch 下训练时,不同批大小所产生的影响。
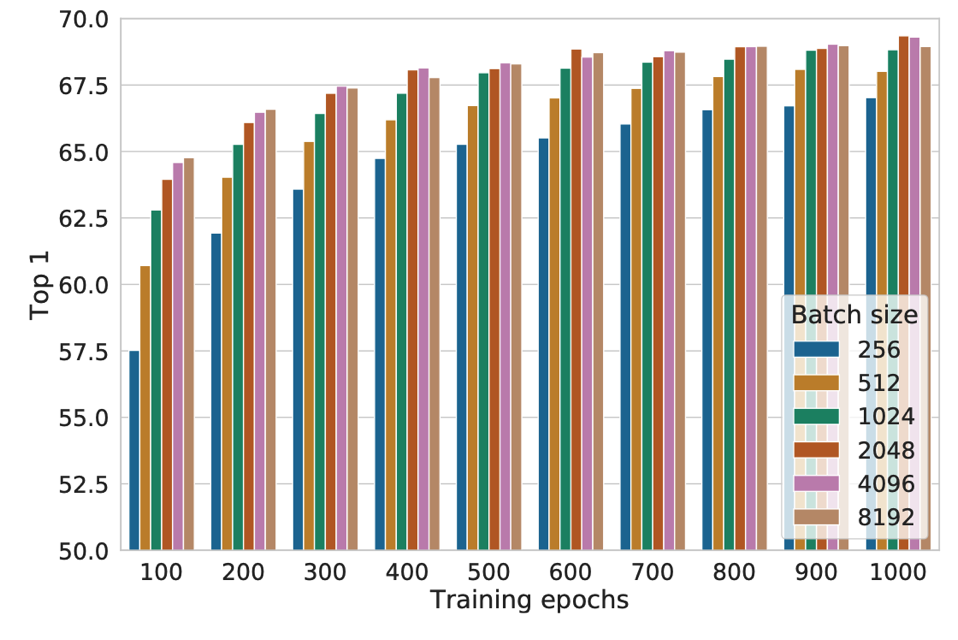
图9. 不同batchsize和训练步数对模型的影响
作者用的是google的Cloud TPU,对于batchisze=4096以及epoch=100的情况,128个TPU v3,训练时间大约1.5小时
线性评估 — 用不同的自监督学习方法训练的线性分类器在ImageNet上的准确率对比
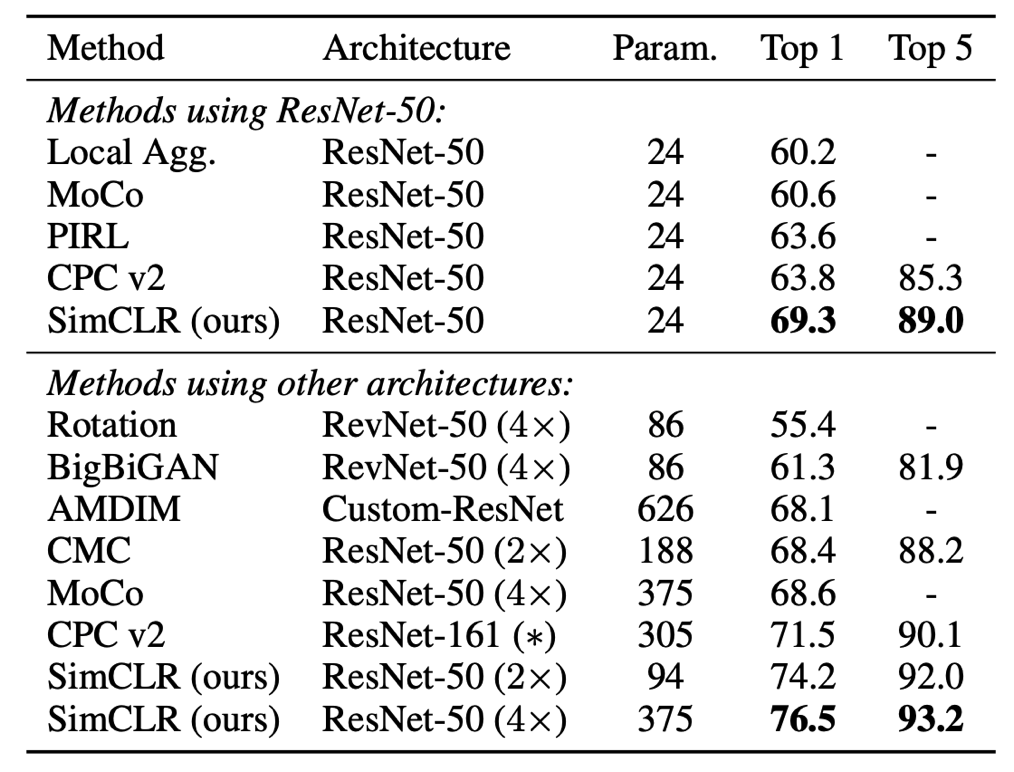
表 6 显示了 SimCLR 与之前方法在线性估计方面的对比。此外,上文中的表 1 展示了不同方法之间更多的数值比较。从表中可以看出,用 SimCLR 方法使用 ResNet-50 (4×) 架构能够得到与监督预训练 ResNet-50 相媲美的结果。
与其他方法通过半监督学习在ImageNet上的准确率对比
下表 7 显示了 SimCLR 与之前方法在半监督学习方面的对比。从表中可以看出,无论是使用 1% 还是 10% 的标签,本文提出的方法都显著优于之前的 SOTA 模型。
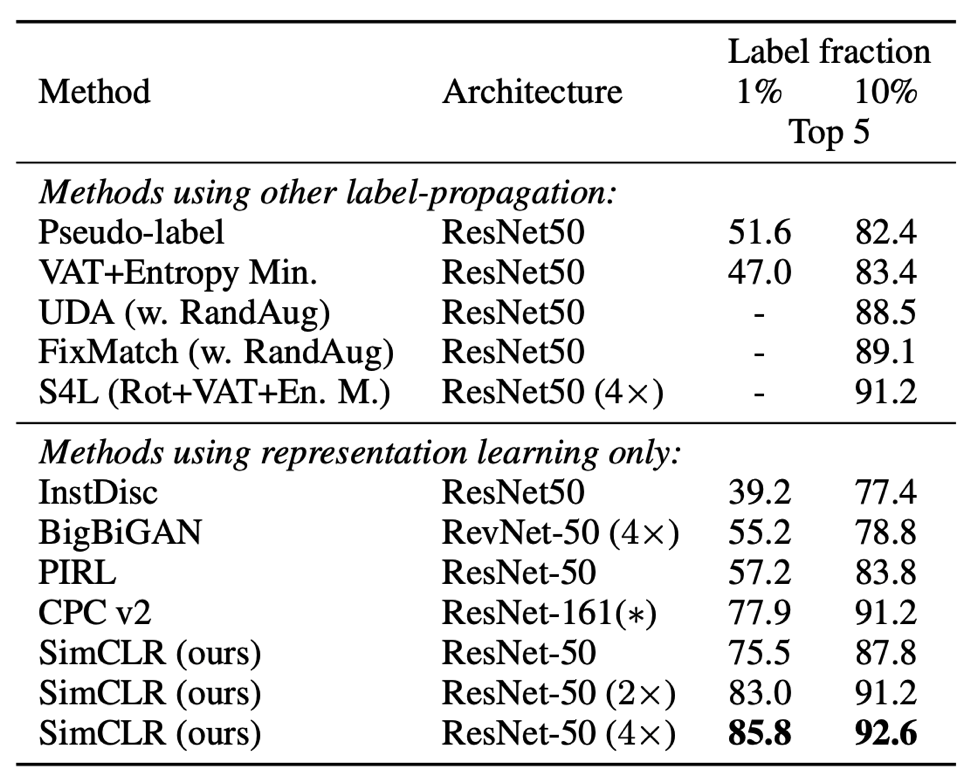
我们只需根据标记的数据对整个基础网络进行微调 在1%和10%的标签的基础上有了显著的改进。
迁移学习
研究者在 12 个自然图像数据集上评估了模型的迁移学习性能。下表 8 显示了使用 ResNet-50 的结果,与监督学习模型 ResNet-50 相比,SimCLR 显示了良好的迁移性能——两者成绩互有胜负。
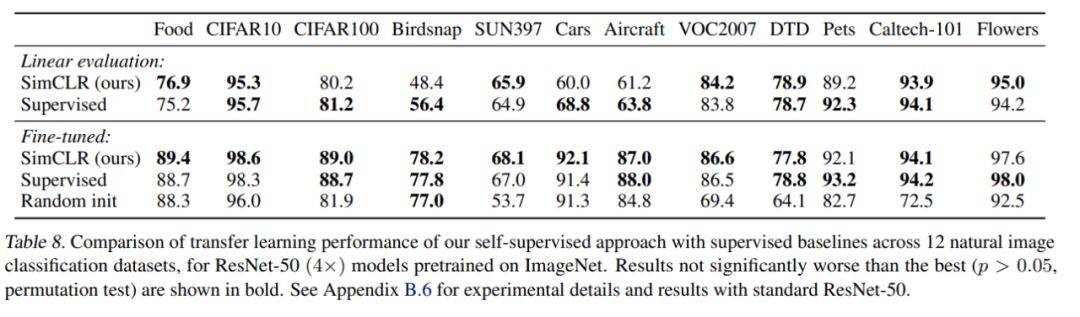
在 12 个自然图像数据集上模型的迁移学习性能与监督学习baselines的对比
线性评估是什么
我们用预训练网络上提取到的特征训练 $l2$ 正则化的多项式逻辑回归分类器, 使用L-BFGS来优化softmax交叉熵损失,
Q: L-BFGS是什么
解无约束非线性规划问题最常用的方法, 收敛速度快内存开销小.
L-BFGS和梯度下降、SGD干的同样的事情,但收敛速度更快
微调的方法
我们使用预训练网络的权值作为初始化,对整个网络进行了微调。我们使用带有Nesterov动量的SGD进行了20000步的批量训练,其动量参数为0.9。我们将批量标准化统计的动量参数设置为max(1 10s, 0.9),其中s为每个epoch的步数。作为微调期间的数据扩充,我们只执行随机裁剪与调整大小和翻转;与训练前相比,我们没有进行色彩增强或模糊处理。在测试时,我们沿着短边将图像大小调整为256像素
总结
•提出了一个对比学习的简单框架并用于视觉表示学习中, 相比以前的自监督、半监督和迁移学习方法在结果上有了很大的改进。
•结果表明, 想要获得良好性能, 以往一些用于自监督学习的方法的复杂性并不是所必需的。本文方法与ImageNet上标准的监督学习方法的不同之处在于,它只选择了数据增广、在网络的末端使用一个非线性映射头以及损失函数。这一简单框架的强大说明尽管近来人们对自监督学习的兴趣激增,但它的价值仍然被低估了。
Reference
Hinton组力作:ImageNet无监督学习最佳性能一次提升7%,媲美监督学习
-
Previous
Visual Representations(VR)综述 -
Next
论文学习 Fuzzy c Means clustering with local information and kernel metric for image segmentation