
收获/点子:
现用的是基于cnn的光谱图像分割, 可考虑用基于fcn的HSI 分类
普通分类网络(如CNN)会在全连接层将原来二维矩阵(图片)压缩为一维的向量, 丢失了空间信息
将全连接替换为全卷积层, 即构成全卷积神经网络, 将图像基本分类扩展到像素级别分类.
(Berkeley团队提出 Fully Convolutional Networks(FCN)方法用于图像语义分割,将图像级别的分类扩展到像素级别的分类(图1),获得 CVPR2015 的 best paper。)
Fully Convolutional Networks for Semantic Segmentation
FCN实现了end-to-end
文章《【总结】图像语义分割之FCN和CRF》 认为,发展到现在,基于深度学习的图像语义分割“通用框架已经确定”:前端 FCN(包含基于此的改进 SegNet、DeconvNet、DeepLab)+ 后端 CRF/MRF (条件随机场/马尔科夫随机场)优化
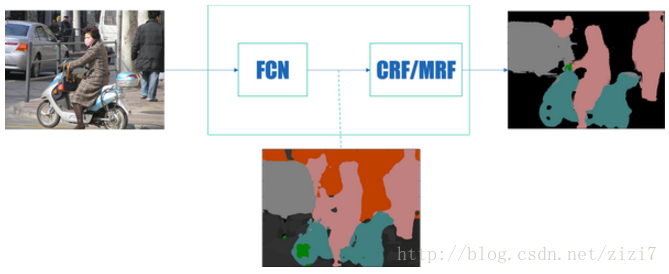
图2. 图像语义分割通用框架(摘自这里)
基于CNN的分割方法和FCN比较传统的基于CNN的分割方法:为了对一个像素分类,使用该像素周围的一个图像块作为CNN的输入用于训练和预测。这种方法有几个缺点:
一是存储开销很大。例如对每个像素使用的图像块的大小为15x15,然后不断滑动窗口,每次滑动的窗口给CNN进行判别分类,因此则所需的存储空间根据滑动窗口的次数和大小急剧上升。 二是计算效率低下。相邻的像素块基本上是重复的,针对每个像素块逐个计算卷积,这种计算也有很大程度上的重复。 三是像素块大小的限制了感知区域的大小。通常像素块的大小比整幅图像的大小小很多,只能提取一些局部的特征,从而导致分类的性能受到限制。 而全卷积网络(FCN)则是从抽象的特征中恢复出每个像素所属的类别。即从图像级别的分类进一步延伸到像素级别的分类。=
一句话概括原理
FCN将传统卷积网络后面的全连接层换成了卷积层,这样网络输出不再是类别而是 heatmap(每种特征一个热力图????);同时为了解决因为卷积和池化对图像尺寸的影响,提出使用**上采样**的方式恢复。 核心思想
本文包含了当下CNN的三个思潮 :
增大数据尺寸的反卷积(deconv)层。能够输出精细的结果。结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。怎么理解网络结构
网络结构示意图:
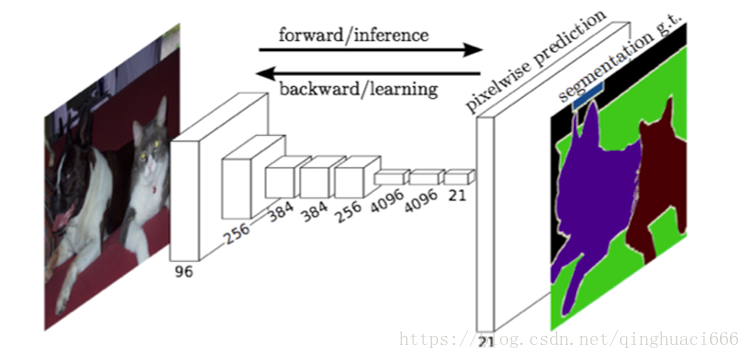
网络结构详图。输入可为任意尺寸图像彩色图像;输出与输入尺寸相同,深度为:20类目标+背景=21。
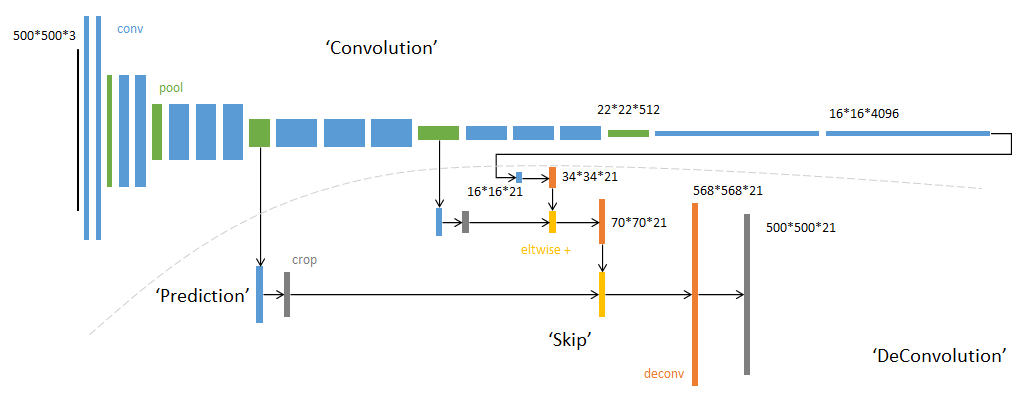
采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。
最后的输出是1000张heatmap经过upsampling变为原图大小的图片,为了对每个像素进行分类预测label成最后已经进行语义分割的图像,这里有一个小trick,就是最后通过逐个像素地求其在1000张图像该像素位置的最大数值描述(概率)作为该像素的分类。因此产生了一张已经分类好的图片,如下图右侧有狗狗和猫猫的图。 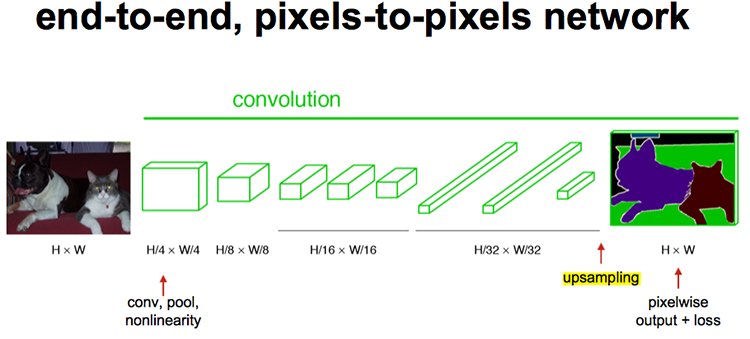
简单来说就是pooling的逆过程,pooling采样后数据数量减少,upsample采样后数据数量增多。
最后选用的是反卷积的方法(FCN作者称其为后卷积)使图像实现end to end
***\*反卷积(deconvolutional)\****反卷积(Deconvolution),当然关于这个名字不同框架不同,Caffe和Kera里叫Deconvolution,而tensorflow里叫conv_transpose。CS231n这门课中说,叫conv_transpose更为合适。
参数和CNN的参数一样是在训练FCN模型的过程中通过bp算法学习得到。
反卷积和卷积类似,都是相乘相加的运算。只不过后者是多对一,前者是一对多。而反卷积的前向和后向传播,只用颠倒卷积的前后向传播即可。所以无论优化还是后向传播算法都是没有问题。图解如下:

获取heatmap
经过前面操作,基本就能实现语义分割了,但是直接将全卷积后的结果进行反卷积,得到的结果往往比较粗糙
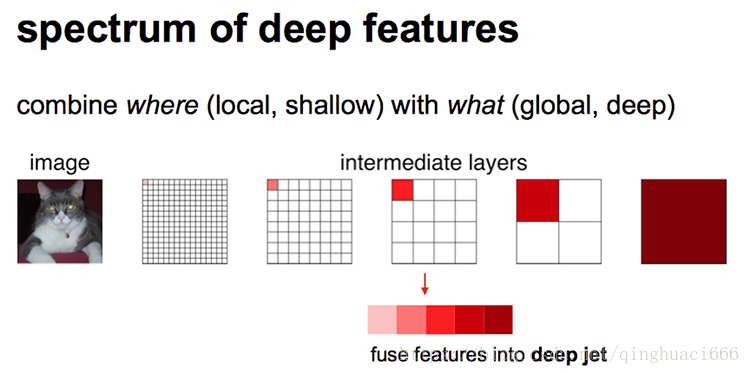
此时图像不再叫featureMap而是叫heatMap。
跳跃结构实现精细分割
现在我们有1/32尺寸的heatMap,1/16尺寸的featureMap和1/8尺寸的featureMap,1/32尺寸的heatMap进行upsampling操作之后,因为这样的操作还原的图片仅仅是conv5中的卷积核中的特征,限于精度问题不能够很好地还原图像当中的特征。因此在这里向前迭代,把conv4中的卷积核对上一次upsampling之后的图进行反卷积补充细节(相当于一个插值过程),最后把conv3中的卷积核对刚才upsampling之后的图像进行再次反卷积补充细节,最后就完成了整个图像的还原。
具体来说,就是将不同池化层的结果进行上采样,然后结合这些结果来优化输出,分为FCN-32s,FCN-16s,FCN-8s三种,第一行对应FCN-32s,第二行对应FCN-16s,第三行对应FCN-8s。 具体结构如下:

6 训练过程未完待续 – https://blog.csdn.net/qinghuaci666/article/details/80863032
de are probably your best bets out of the 11 options considered. “Great code completion” is the primary