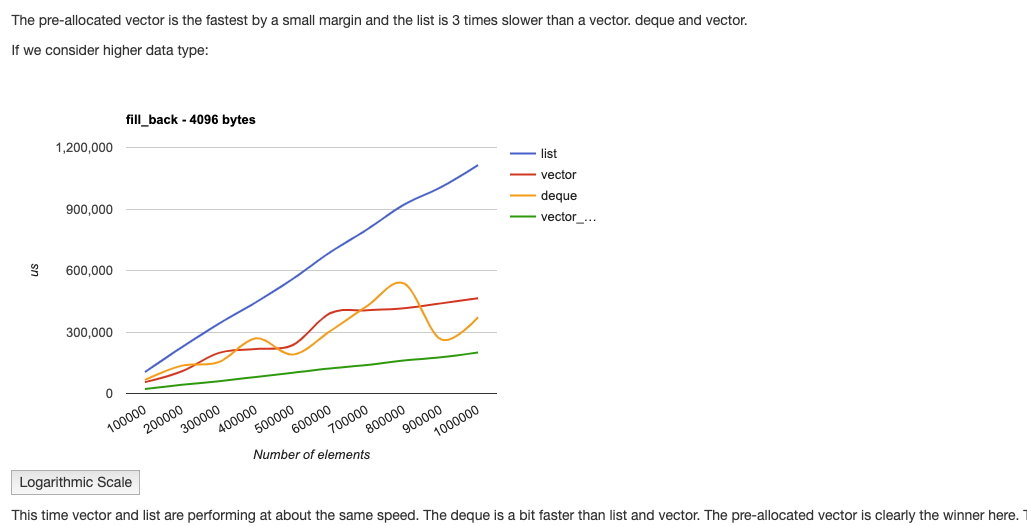
list,vector,deque,vector_preallocated 对比
C++ benchmarks: vector vs list vs deque实验对比及源码
| 数据结构模型 | 实例 | 查找 | 插入 | 删除 | 优缺点 |
|---|---|---|---|---|---|
| 数组 | vector | o(n) | o(1) | o(n) | 优点:高效随机访问、节省空间, 任意元素的读取、修改具有常数时间复杂度,在尾部进行插入、删除是常数时间复杂度 缺点:其他位置的插入/删除操作效率低下、动态大小查过自身容量需要申请大量内存做大量拷贝。 |
| 有序数组 | o(lgn) | o(n) | o(n) | ||
| 数组与链表的折中 | Deque | 优点:高效随机访问、内部插入删除元素效率方便、两端push pop 缺点:内存占用比较高 |
|||
| 链表 | list | o(n) | o(1) | o(n) | 优点:任意位置插入删除元素常量时间复杂度、容器融合是常量时间复杂度 缺点:不支持随机访问、内存占用高 |
| 平衡树 | map set multimap multiset |
o(lgn) | o(lgn) | o(lgn) | 优点:元素会按照键值排序、查找的速度非常快时间复杂度是O(logN)、通过键值查元素、map提供了下标访问 |
| 哈希表 | hash_map hash_set hash_multimap hash_multiset |
o(1) | o(1) | o(1) | 注意选择hash函数, hash表如果未选择合适的hash函数, 最坏情况均为O(N) |
| 有序链表 | o(n) | o(n) | o(n) | ||
| 二叉树最坏 | o(n) | o(n) | o(n) | ||
| 二叉树一般 | o(lgn) | o(lgn) | o(lgn) |
1) 如果需要高效随机访问,不在数组内部插入删除 –> 用vector
随机访问: 通过下标定位到元素位置, 即 [ ] 操作符和vector.at()
2) 如果存储元素的数目已知 –> 用vector (需要内存分配)
如: 已经知道了是十万的情况下,那先设定好Capacity,选vector 使用 push_back 。
3) 需要任意位置随机插入删除,不考虑随机存取 –> 用list
4) 只有需要首部插入删除元素且兼顾随机存取时 –> 用deque
不需要考虑首部插入删除则均选择vector
6) 元素是复杂结构用list,也可以用vector存储指针(需要额外的精力去维护内存),看需求
7) 如果操作是基于键值或经常的搜索 –> 用map set
8) 当要存储的是大型负责类对象时,list要优于vector;当然这时候也可以用vector来存储指向对象的指针, 同样会取得较高的效率,但是指针的维护容易出错。
如果内存不是考虑的问题。用vector比map好。map每插入一个数据,都要排序一次。所以速度反不及先安插所有元素,再进行排序。
如果你需要在数据中间进行插入,list 是最好的选择
list优于vector,vector的erase()方法慎用。
map
连续内存的容器
这种类型容器包含vector、deque。 如果存储的是复杂结构的话就要花费大量的时间进行拷贝操作(可以存储复杂结构的指针来弥补这个缺陷)。
因为需要保证连续内存同时给新元素腾出空间或者填充删除元素的空间,
基于节点的容器
这类容器是剩余的几个list、set、multiset、map、multimap.这类容器中的数据是分别存储在不同的内存块中,可能连续也可能不连续(一般不认为是连续的),这样的容器在插入删除元素的时候修改的只是节点的指针,这样的消耗是非常小的。
C++三种容器:list、vector和deque的区别–有vector和list使用代码
C++ benchmarks: vector vs list vs deque实验对比及源码
对vector进行预分配空间很重要.
vector如果你没有一开始就分配好空间的话,在插入中会不时重新分配大小,这个效率不好预估,依赖于各个vector的实现了,搞不好也有一次全元素的copy操作。
对于push_back操作,如果预先知道大小,则预分配向量是一个很好的选择。其他的表现或多或少相同。
旧空间+指针 指向 新空间, 注意避免copy操作, 要考虑 vector插之前预分配的size是多少 , 扩充空间(不论多大)都应该这样做: (1)配置一块新空间 (2)将旧元素一一搬往新址 (3)把原来的空间释放还给系统
capacity V.S size a、capacity是容器需要增长之前,能够盛的元素总数;只有连续存储的容器才有capacity的概念(例如vector,deque,string),list不需要capacity。 b、size是容器当前存储的元素的数目。 c、vector默认的容量初始值,以及增长规则是依赖于编译器的。
size和capacity:
reserver函数用来给vector预分配存储区大小,即capacity的值
resize方法被用来改变vector的大小,即vector中元素的数量
vector在大量添加元素的时候问题最大, 如果由于其他因素必须使用vector,并且还需要大量添加新元素,那么可以使用成员函数reserve来事先分配内存,这样可以减少很多不必要的消耗。
因为他的一种最常见的内存分配实现方法是当前的容量(capacity)不足就申请一块当前容量2倍的新内存空间,然后将所有的老元素全部拷贝到新内存中,添加大量元素的时候的花费的惊人的大。
list对这种情况的适应能力就非常好,都是常数时间的插入消耗。deque前面说过了,他是vector和list的折衷形式,内存不够了就申请一块新的内存,但并不拷贝老的元素。
对于序列容器需要分两种情况,区分依据是元素是否排序,
1)对于已经排序的序列容器,使binary_search、lower_bound、upper_bound、equal_range可以获得对数时间复杂度的查找速度(O(logN));
2)而未排序的序列容器二分查找肯定是用不了,能达到的最好的时间复杂度是线性的(O(n))。
对于关联容器,
存储的时候存储的是一棵红黑树(一种更为严格的平衡二叉树,文档最后有介绍),总是能达到对数时间复杂度(O(logN))的效率,因为关联容器是按照键值排好序的。
需要考虑在操作的过程中是否有在任意位置插入元素的需求,有这种需求的话尽量避免使用连续内存的vector、deque.
标准容器中的vector、deque是连续内存的,其中vector是完全连续内存,而deque是vector和list的折衷实现,是多个内存块组成的,每个块中存放的元素连续内存,而内存块又像链表一样连接起来。
连续内存的容器有个明显的缺点,就是有新元素插入或老元素删除的时候,为了给新元素腾出位置或者填充老元素的空缺,同一块内存中的其他数据需要进行整体的移位,这种移位的拷贝代价有时是非常巨大的。
序列容器中的元素不会自动排序,程序员插入什么顺序内存中就是什么顺序,而关联容器不是这样的,他会以自己的键值按照某种等价关系(equivalence)进行排序。所以默认情况下序列容器中的元素是无序的,而关联容器中的元素是有序的。
所以容器在遍历元素的时候序列容器输出的顺序和插入的顺序式一致的,关联容器就不一定了。下面给出两个例子:
通过例子看到序列容器vector遍历的顺序和插入的顺序是一样的,而关联容器set把插入的元素按照某种顺序重新组织了,所以选择容器的时候如果很在意插入顺序的话就选择序列容器。
适合的容器只有一个vector,意思就是如果需要把容器中的数据放到C类型的数组中那么不需要做多余复杂的操作,如果有vector v,只需要直接使用&v[0]就可以得到v中第一个元素的指针,因为vector和C数组的内存布局是一样的,这个要求同时也是标准C++委员会制定的标准。所以能保证有这样特性的容器只有vector,那么vector以外的其他STL容器中的数据如果需要变换成C数组形式,或者C数组放到其他类型容器中,可以把vector作为一个桥梁,下面给个例子:
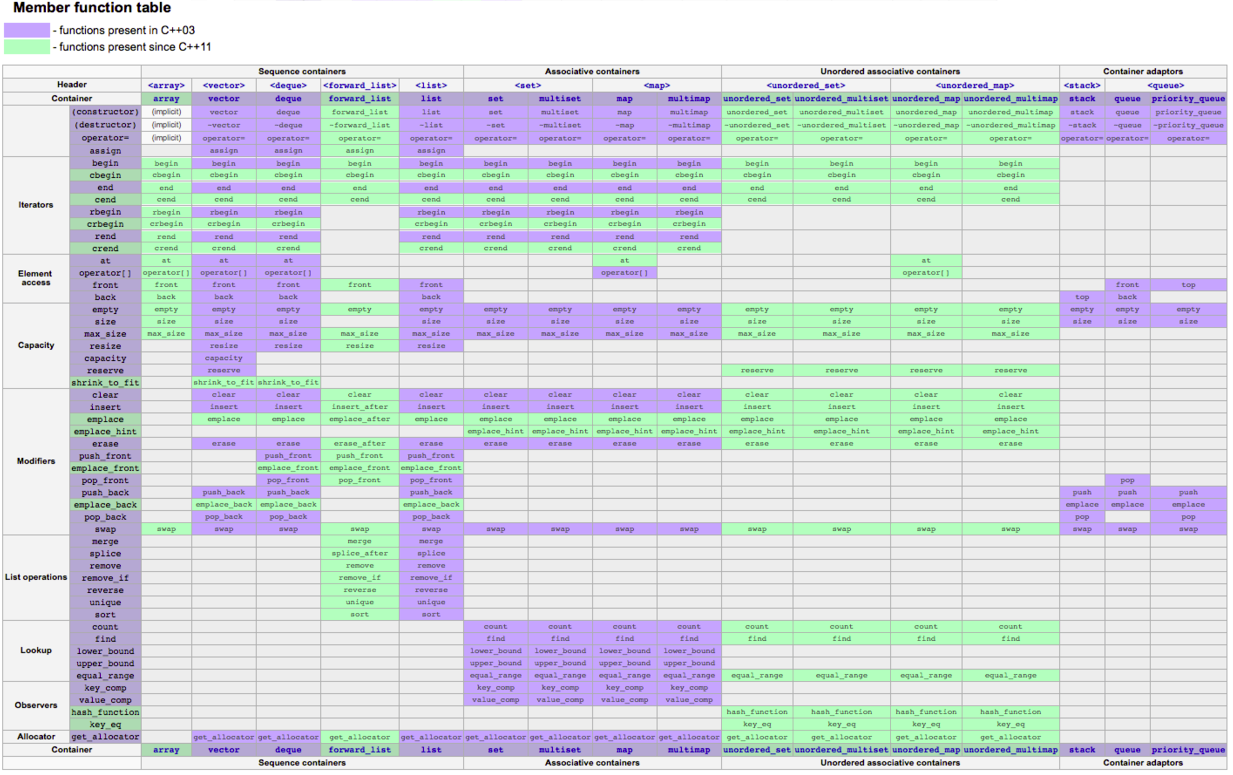
C++支持情况:
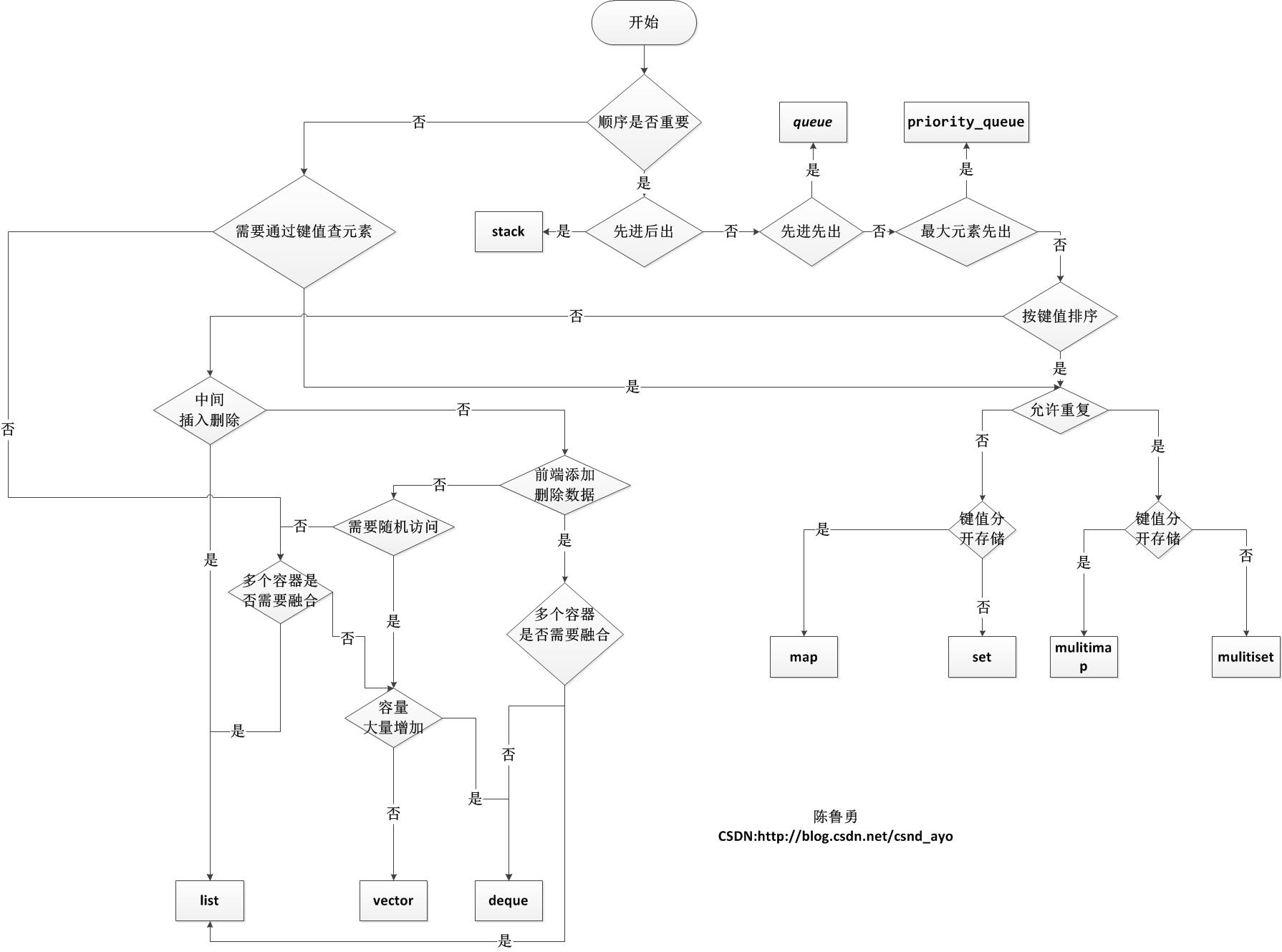
本文章参考STL容器的适用情况,对该文章进行了补充
1 vector
内部实现: 数组 // 就是没有固定大小的数组,vector直接翻译是向量的意思 支持操作: begin(), //取首个元素,返回一个iterator end(), //取末尾(最后一个元素的下一个存储空间的地址) size(), //就是数组大小的意思 clear(), //清空 empty(), //判断vector是否为空 [] //很神奇的东东,可以和数组一样操作 //举例: vector a; //定义了一个vector //然后我们就可以用a[i]来直接访问a中的第i + 1个元素!和数组的下标一模一样! push_back(), pop_back() //从末尾插入或弹出 insert() O(N) //插入元素,O(n)的复杂度 erase() O(N) //删除某个元素,O(n)的复杂度 可以用于数组大小不定且空间紧张的情况
Sample: TOJ1743 King’s Treasure
https://blog.csdn.net/jenus1/article/details/2227691
2 deque
类似 //双端队列,两头都支持进出 支持push_front()和pop_front() 是的精简版:) //栈,只支持从末尾进出 支持push(), pop(), top() 是的精简版 //单端队列,就是我们平时所说的队列,一头进,另一头出 支持push(), pop(), front(), back()
3 list 内部实现: 双向链表 //作用和vector差不多,但内部是用链表实现 支持操作: begin(), end(), size(), clear(), empty() push_back(), pop_back() //从末尾插入或删除元素 push_front(), pop_front() insert() O(1) //链表实现,所以插入和删除的复杂度的O(1) erase() O(1) sort() O(nlogn) //不支持[ ]操作!
4 set
内部实现: 红黑树 //Red-Black Tree,一种平衡的二叉排序树 //又是一个Compare函数,类似于qsort函数里的那个Compare函数,作为红黑树在内部实现的比较方式 insert() O(logn) erase() O(logn) find() O(logn) 找不到返回a.end() lower_bound() O(logn) 查找第一个不小于k的元素 upper_bound() O(logn) 查找第一个大于k的元素 equal_range() O(logn) 返回pair
5 multiset 允许重复元素的
的用法及Compare函数示例: struct SS {int x,y;}; struct ltstr { bool operator() (SS a, SS b) {return a.x < b.x;} //注意,按C语言习惯,double型要写成这样:return a.x < b.x ? 1 : 0; }; int main() { set st; … }
6 map 内部实现: pair组成的红黑树 //map中文意思:印射!! //就是很多pair 组成一个红黑树 insert() O(logn) erase() O(logn) find() O(logn) 找不到返回a.end() lower_bound() O(logn) 查找第一个不小于k的元素 upper_bound() O(logn) 查找第一个大于k的元素 equal_range() O(logn) 返回pair [key]运算符 O(logn) *** //这个..太猛了,怎么说呢,数组有一个下标,如a[i],这里i是int型的。数组可以认为是从int印射到另一个类型的印射,而map是一个任意的印射,所以i可以是任何类型的!
7 multimap 允许重复元素, 没有[]运算符
Sample : TOJ 1378 Babelfish
8 priority_queue 内部实现: 堆 //优先队列
支持操作: push() O(n) pop() O(n) top() O(1) See also: push_heap(), pop_heap() … in
9 hash_map 内部实现: Hash表//内部用哈希表实现的map
重载HashFcn和EqualKey 支持操作: insert(); O(1) earse(); O(1) [ ]; O(1)
https://blog.csdn.net/jenus1/article/details/2227691
1.sort()
2.从大到小排序(需要自己写comp函数)
\3. 对结构体排序
\2. binary_search()