6.6-张亚勤 New Wave of Digital Transformation
日期
2020-6-6
11:00~12:00 BJT
梗概
- Digitalization 3.0 : New wave of digitalization
- 2nd aspect of digital information: ABC Particularly AI
- New architectural & infrastructural Revolution
6.6-李开复 AI赋能时代的创业
日期
2020-6-6
9:00~11:00 BJT
梗概
- 中国AI如何弯道超车
- AI从“发明期”进入“应用期”
- AI赋能时代的创业特点
- 给AI未来人才的建议
内容
中国AI如何弯道超车
perception AI: 如计算机视觉: 旷世,商汤, 无人驾驶,
现在AI现在进入了应用期, 深度学习与产业界结合刚刚开始,
AI对未来人才的建议
如何成为未来人才, 而不是做过去的工作
System2 聚焦于AI认知问题 (感知 -> 认知)
AI会自然融入各种公司, 让AI无所不在, 赋能到传统行业
图像–> 医疗, 无人驾驶, (数据非常重要), CV的应用才刚刚开始, 需要商业+技术
关于可解释性:
医疗,自动驾驶,金融: 需要有可解释性
创业
把用户当上帝
加入传统公司
互联网
金融公司
加入AI赋能公司
6.7-吴恩达 Full Cycle Machine Learning
- http://wiki.deecamp.com:8090/pages/viewpage.action?pageId=1769942#page-metadata-start)
日期
2020-6-7
9:00~11:00 BJT
梗概
The Full Cycle Machine Learning is designed for ML practitioners (Data Scientists, MLEs, Data Engineers, Data Analysts), students of ML/AI as well as data software engineers with some background in ML/AI . This course bridges the gap between being able to develop a ML algorithm/model and being able to develop and deploy a robust ML system to production.
A lot of AI work focuses on building the model—such as the neural network needed to generate a specific X–>Y mapping. But to build practical production systems, many additional steps are needing, ranging from scoping the project, to deciding on the data collection methodology, to making sure the data is high quality, to strategies for model iteration, to practical deployment and monitoring.
课后资源补充:
- Open positions of Landing and deeplearning.ai: https://landing.ai/careers/; https://www.deeplearning.ai/careers/
- deeplearning.ai is also recruiting a senior full stack engineer in Beijing. You can send the resume to career@landing.ai
- Here is the information of Stanford ML group: https://stanfordmlgroup.github.io/#contact
- Machine Learning Yearning https://www.deeplearning.ai/machine-learning-yearning/
6.13-张潼 神经网络模型设计和理论研究简介
2020-6-13
9:00~11:00(BJT)
梗概
当今深度学习的发展是以大数据和大计算力为基础的。这个模式在现阶段起到如下作用:设计更深更复杂的模型来提升效果,大模型预训练技术和表示学习取得广泛应用,自动化模型设计成为可能。虽然基于这个模式的深度学习研究有很多的成功案例,但是已经遇到了一系列技术瓶颈。为了进一步的技术突破,我们在现阶段需要建立更加完整的理论体系来指导今后研究。
在这个讲座,我围绕以上这几个问题简单介绍关于神经网络研究的一些近期进展,包括以下三个部分:
\1. 人工设计模型和预训练大模型简介
\2. 针对特定任务和硬件的自动化模型设计简介
\3. 神经网络的优化和过参数化理论简介
6.14-周志华 机器学习的挑战
日期
2020-6-14
9:00~11:00
课程大纲:
- 关于深度模型
- 关于监督信息
- 关于任务环境
附件
机器学习的挑战_周志华.pdf
周志华老师讲课回忆—机器学习的挑战(未完,待更新).pdf
机器学习的挑战 - 周志华2.pdf
周志华 机器学习的挑战note.pdf
内容
Neuro Network development
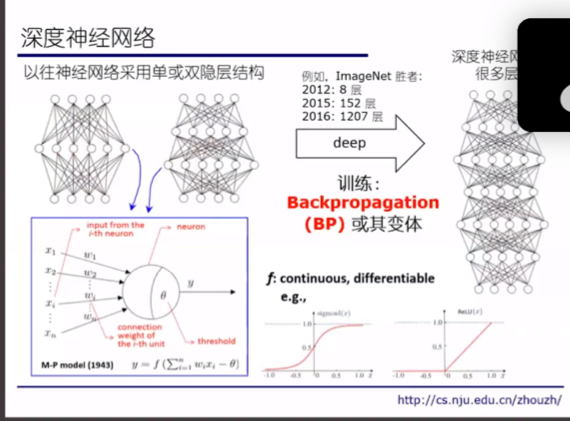
M-P model 1943年出现, 2012年8层, 2015年152层, 2016年1207层.
为什么要deep?
Deep -> 增加嵌套迭代层数 → 更增加复杂度
Width → 增加函数个数
机器学习在做什么?
主要在避免过拟合 →所以要避免用复杂模型, 防止将训练集特性当做一般规律
如:
- 决策树 → 剪枝
- SVM → 正则化
- 神经网络 → 早停
为何会过拟合?
数据量少+模型复杂
机器学习算法为了满足未知复杂度的任务 → 模型复杂度往往高于问题复杂度, 即有”在拟合出正确规则前提下,能进步一拟合噪声”的能力
网络越深: 抽象程度越高, 自由度越大
网络过深的缺点: https://zhuanlan.zhihu.com/p/44304391
-
梯度x消失, 梯度爆炸
-
过拟合
-
网络退化
残差网络一定程度解决这个问题
解决过拟合的方法有哪些?
知乎 - 解决过拟合方法 https://www.zhihu.com/question/59201590/answer/167392763
-
获取更多数据 → 最有效, 让模型看到更多特例
-
从源头直接增加
-
根据当前数据集,估计参数分布 → 生成数据 (但会引入抽样误差)
-
数据增强(data argumentation)
位置, 姿态, 尺度, 明暗度 → 平移, 翻转, 缩放, 切割
-
-
合适模型
- 网络结构(simpler model structure) → 减少网络层数, 神经元个数
- 训练时间(early stopping) → 早停, 限制网络能力
限制权值(weight-decay), 也叫正则化(regularization) ?????- 增加噪声(Noice)
- 输入中
- 权值上
- 网络响应
-
**结合多种模型**(ensamble) → 训练多种模型, 以每个模型平均输出作为结果-
Bagging(神经网络一般不用)
类似分段函数概念
-
Boosting
- 训练简单神经网络, 加权平均输出
-
Dropout
-
贝叶斯方法(Bayesian)?? -
utilize invariance?????
-
神经网络为什么有用?
很可能因为其网络很深, 参数够多, 故表达能力够强.
现在问什么可以用复杂模型了?
- 大数据
- 大计算能力
- 足够训练技巧

网络的泛化能力???
泛化能力好 → 网络复杂度低
深层网络网络复杂度不一定高
可以多高复杂度网络降低复杂度, 提升繁华能力 ?????可做
泛化能力好的网络是低复杂度的网络,但是要找到这样的网络是困难的,只有通过对复杂网络(具有更高复杂度潜力的结构)来扩大搜索范围,从而在复杂网络中找到低复杂度的配置模式,来改善泛化能力。 这就是为何我们一般需要使用更复杂的网络结构来寻找泛化性能更好的网络。
如ResNet实际就降低了深层网络的复杂度
为什么神经网络浅的就是干不过深的? - 表示学习
左边数据, 右边结果, 中间特征是自己学习出来的.
现在用的神经网络直接端到端好不好? → 实际上很好用, 因为可以自己把特征学习出来, 人类不可能把所以特征考虑进去
实际上很好, 虽然理论上不一定, 因为内部可能在抵消
所以, 深度学习的关键 → 自动提取特征(表示学习)
表示学习的关键?(除了神经网络外其他的都不能做) → **逐层处理, 逐层加工**
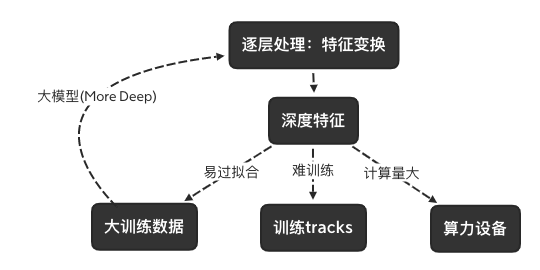
以前逐层处理的模型为何效果不够?
决策树: 1. 复杂度不足 2. 无特征变换
Boosting: 1. 复杂度不足 2. 基于初始特征, 无特征变换
Deep Models 的关键
- 逐层加工处理
- 内置特征变换
- (足够模型复杂度)
现在NN的缺陷
- 太多超参, 难调, 跨任务难
- 模型和复杂度必须先确定
- 打训练数据
- 理论分析难, 黑箱模型
哪些用深度效果好?
图像, 视频, 语音.**等连续信号** **(数值建模任务)** → DNN
-
**只要可微( 即 differentiable nonlinear models) 便可实现**如PCA可看做一种神经网络 实现???
其他任务如**离散的, 符号化的** (非数值建模任务) → 往往随机森林 / XgBoost好用
- 深度上的探索
- 深度森林(gcforest)
- diversity → avoid diversity vanish (对应 avoid gradient vanish)
- feature augmentation → assemble
- 深度森林(gcforest)
监督信息的使用
目前模型都依赖强监督信息
强化学习的AlphaGo, 也是利用了”胜负规则”作为极强的监督信息(本质上需要监督)
弱监督有哪些
- 监督信息不完全: 少量监督 → 半监督/
- 监督信息不具体: 仅做整体标注 →
- 监督信息不精确: 标错标签 →
表现:
- 分布偏移
- 属性变动
- 类别增长
强化学习: 不能适应环境的变化
类别变化工作使用的方法?
增量学习(Incremental Learning)
流数据检测(streaming data)
周志华团队的强化学习模型? Open AI RL 竞赛
- 单关模型集成(二次学习)
- 多样性激励(好奇心策略)
Q&A
开放动态学习????
非独立同分布的 → 可用关系学习
有噪声时怎么办?
- 对噪声有先验
- 分类噪声的学习
如何将其他模型和神经网络结合?
-
将已有工作解释为神经网络
如PCA(传统方法), 可将其描述为神经网络来进行计算
-
不能解释时将优点结合????
为何除深度完了模型,其他机器学习不需要参数迁移?
其他模型也可以迁移, 知识因为不够深, 参数量少, 故不需要迁移
Differential Programming 的价值?
可微 → 可用神经网络语言进行描述 → 可用GPU加速/其他通用tracks
关于RL落地问题?
CV等: 数据集易搜集 → 易落地
RL : 也有, 如虚拟淘宝等
机器学习应用和机器学习理论的学习轨迹
机器学习应用: 李航«统计学习方法» + pytorch实践 即可
机器学习理论: 需要数学基础更多一些
6.20-俞敏洪 AI在教育领域的应用和教育创业启示
时间
2020-6-20
9:00~11:00
6.21-汪华 科技互联网发展趋势与 To B 创业方法论
日期
2020-6-21
9:00~11:00
课程大纲
- 过去8年科技互联网发展趋势解析
- To B(企业服务)创业方法论
计算机视觉的发展和未来——田奇(微信 +12106432559)

Q&A
为什么计算机视觉很难?
语义多样性
几何信息很重要
工作方式不一样
- 人眼就有抽象能力
- 人眼具有 三维感知能力
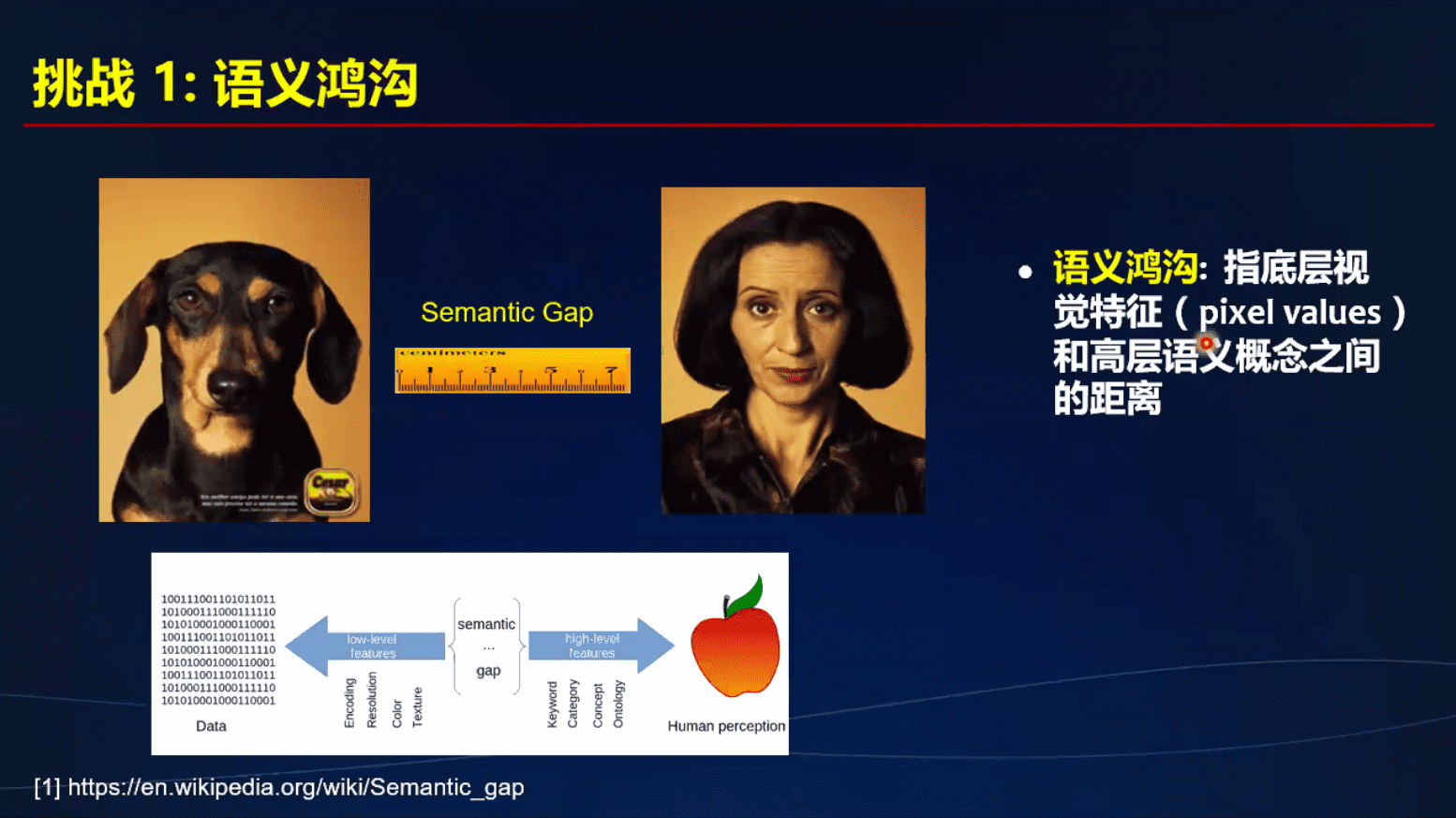
计算机视觉的挑战
- 语义鸿沟
- 缺乏常识 – 如何表示和使用常识 可做

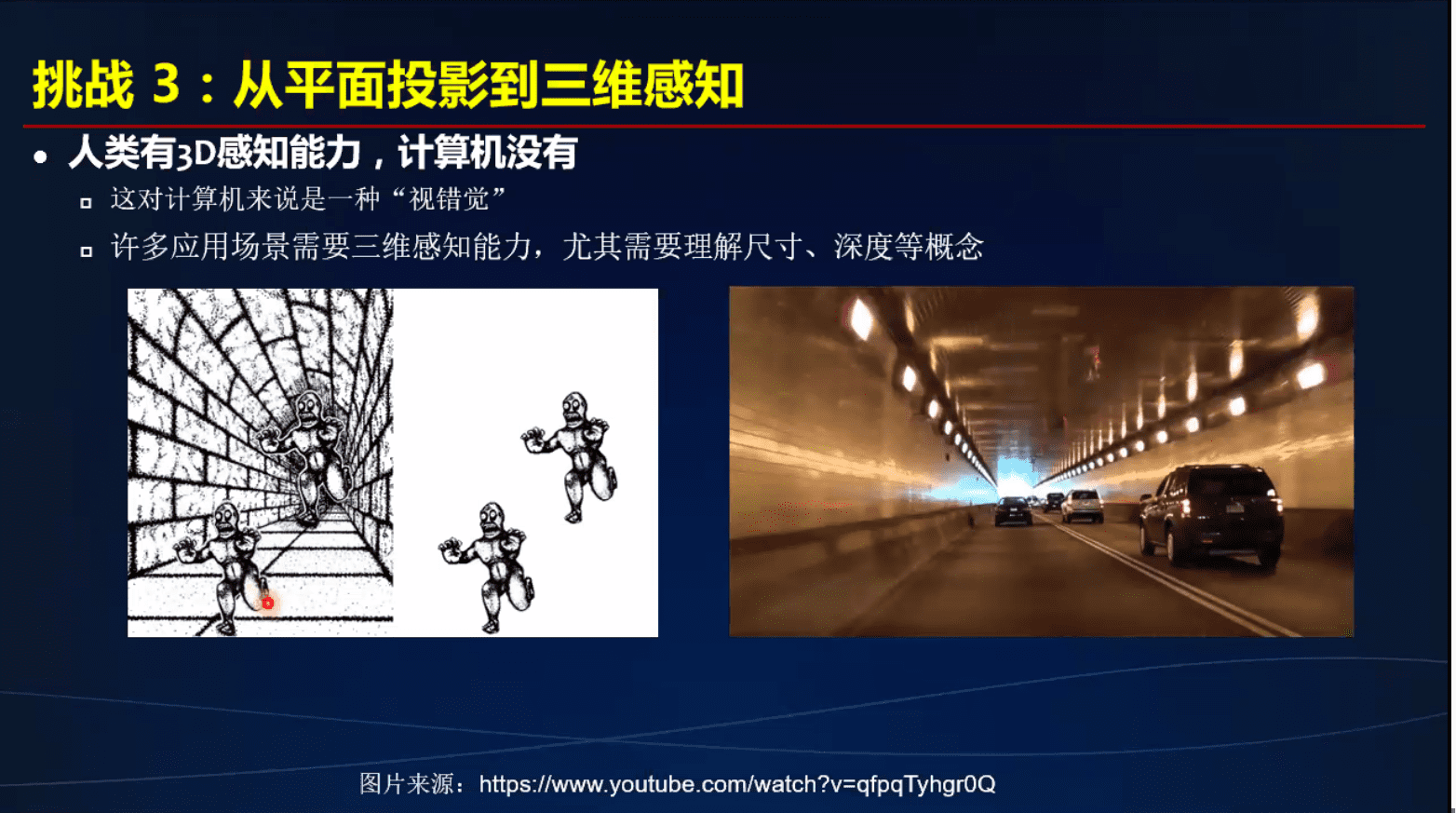
- 从平面投影到三维感知 – 3D视觉是计算机视觉的未来 可做
对视觉信号的讨论

对视觉问题的陈述


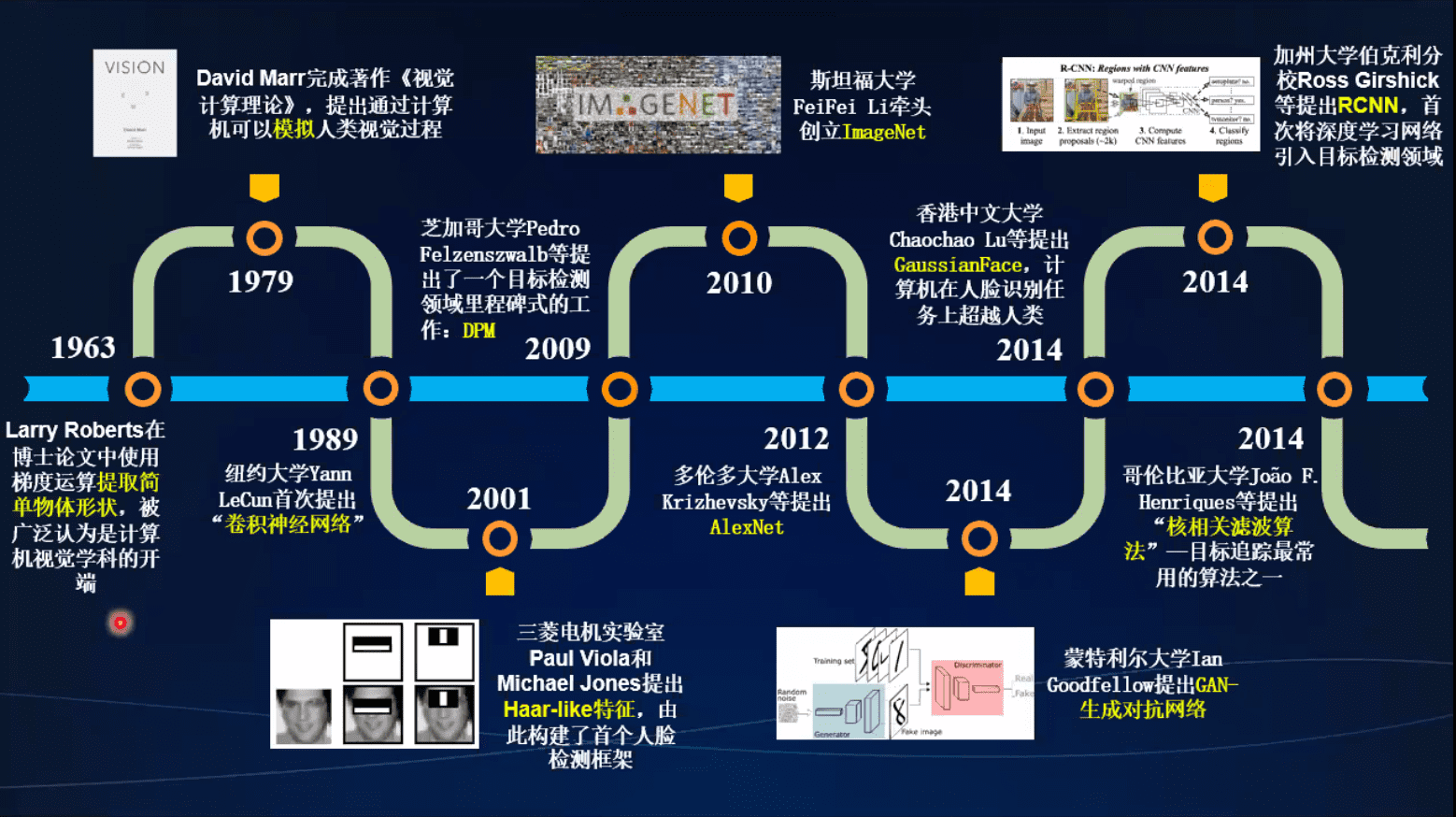
马尔的奠基工作

神经网络的诞生

多层神经网络

设计手工特征

深度学习时代

图像数据集

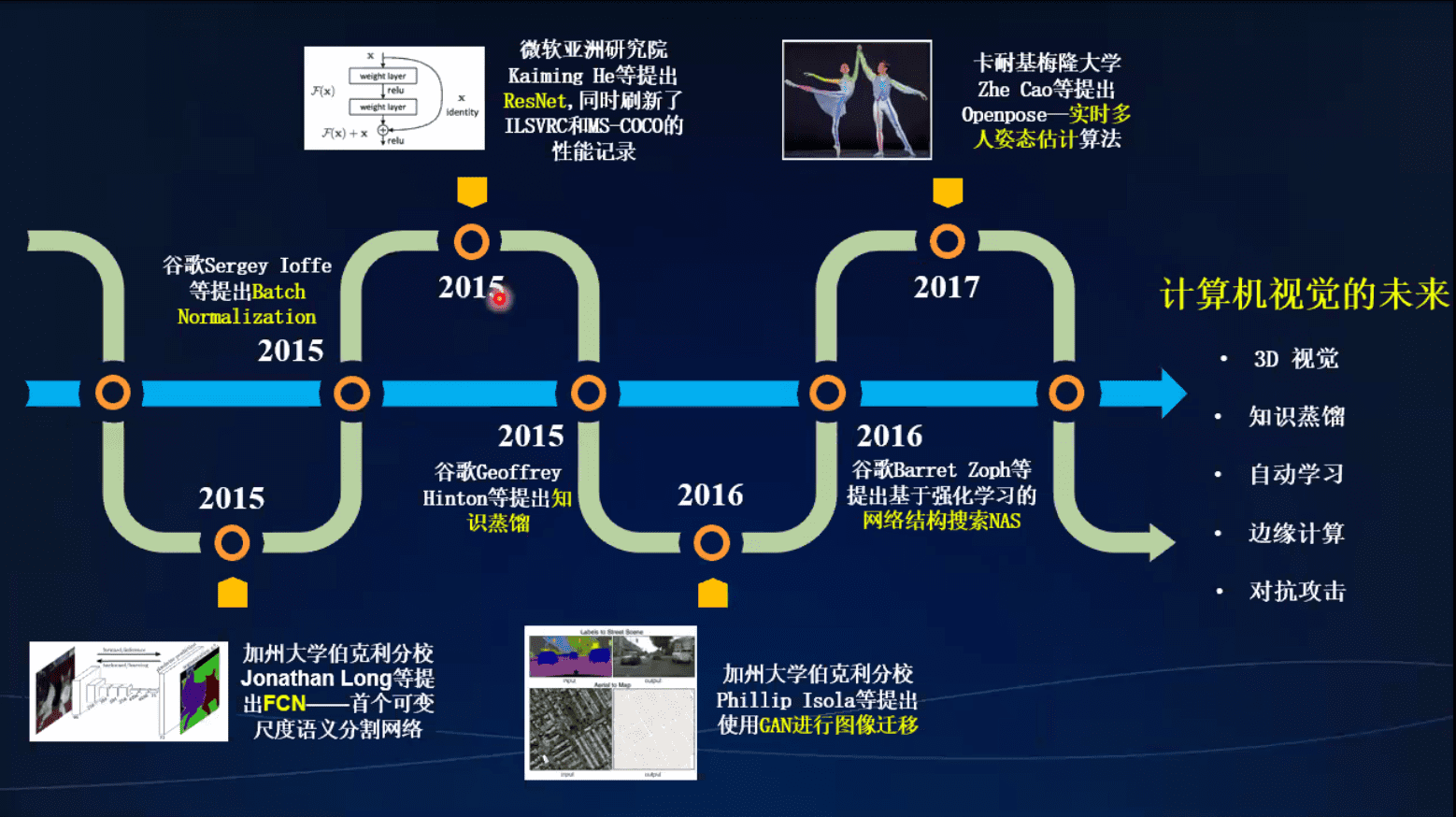
发展和计算机视觉未来、
- 3d视觉
- 知识蒸馏
- 自动学习
- 边缘计算
- 对抗攻击
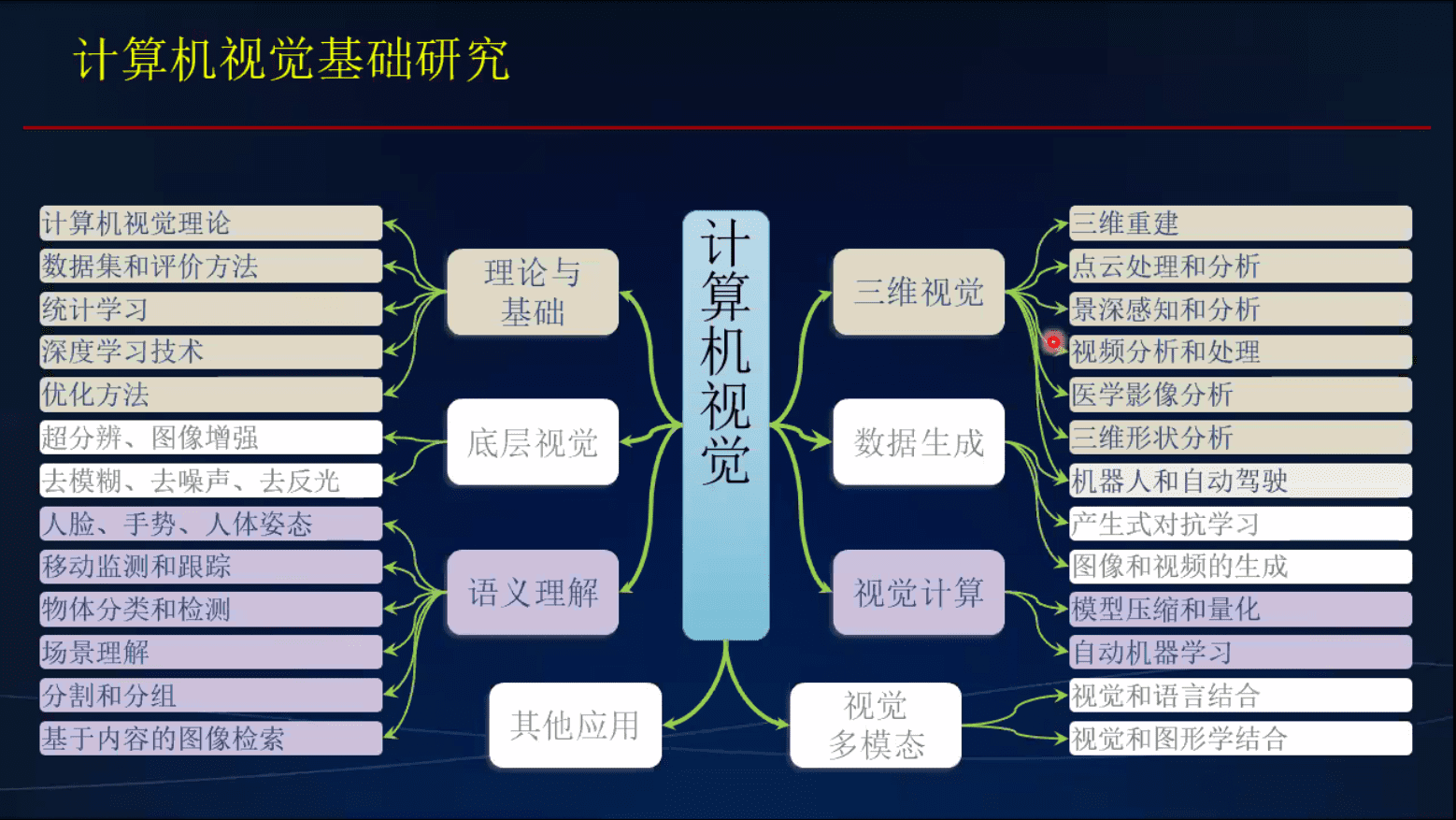
计算机视觉基础研究
数据生成: 生成对抗, 虚拟场景
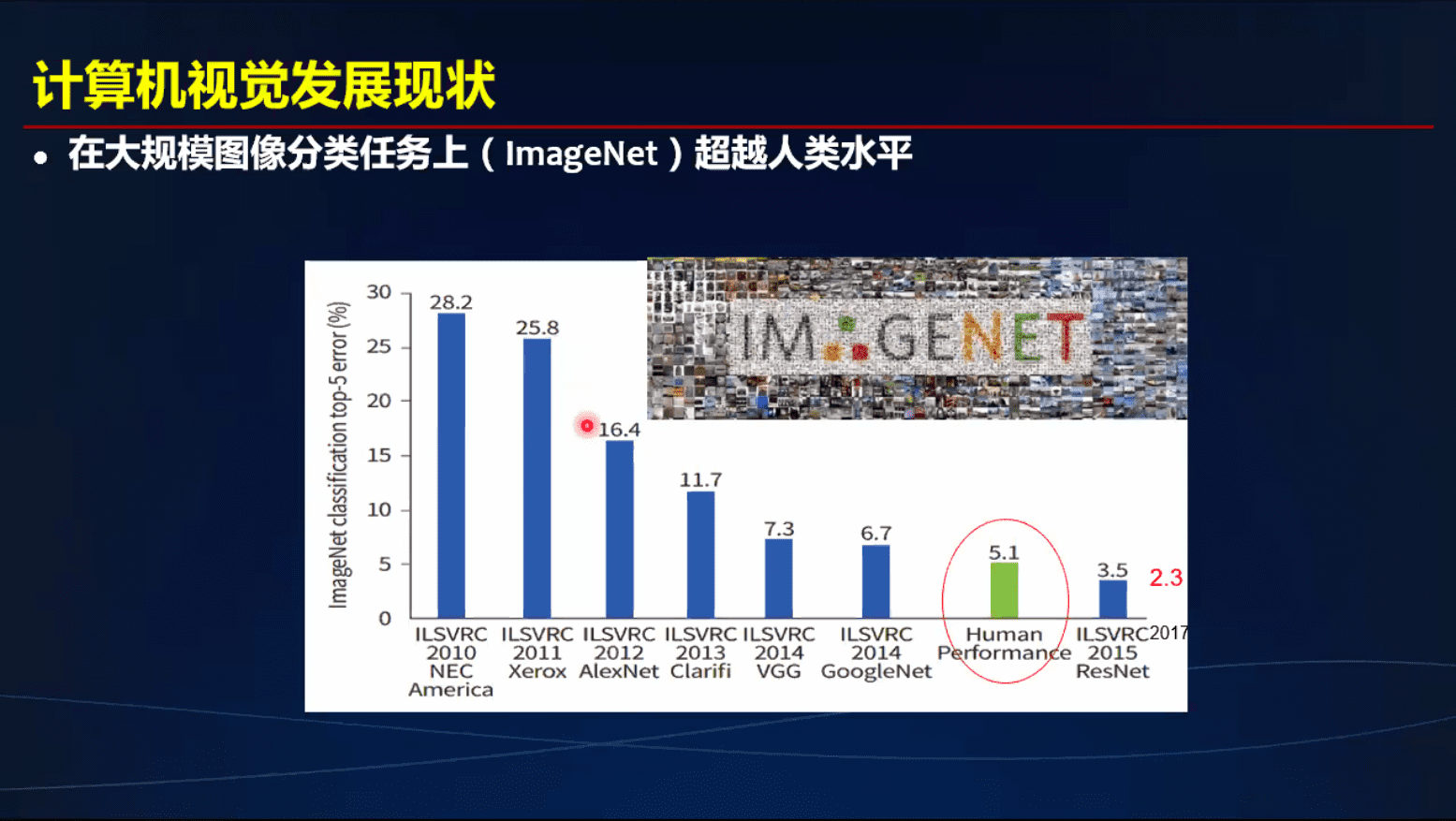
计算机视觉发展现状
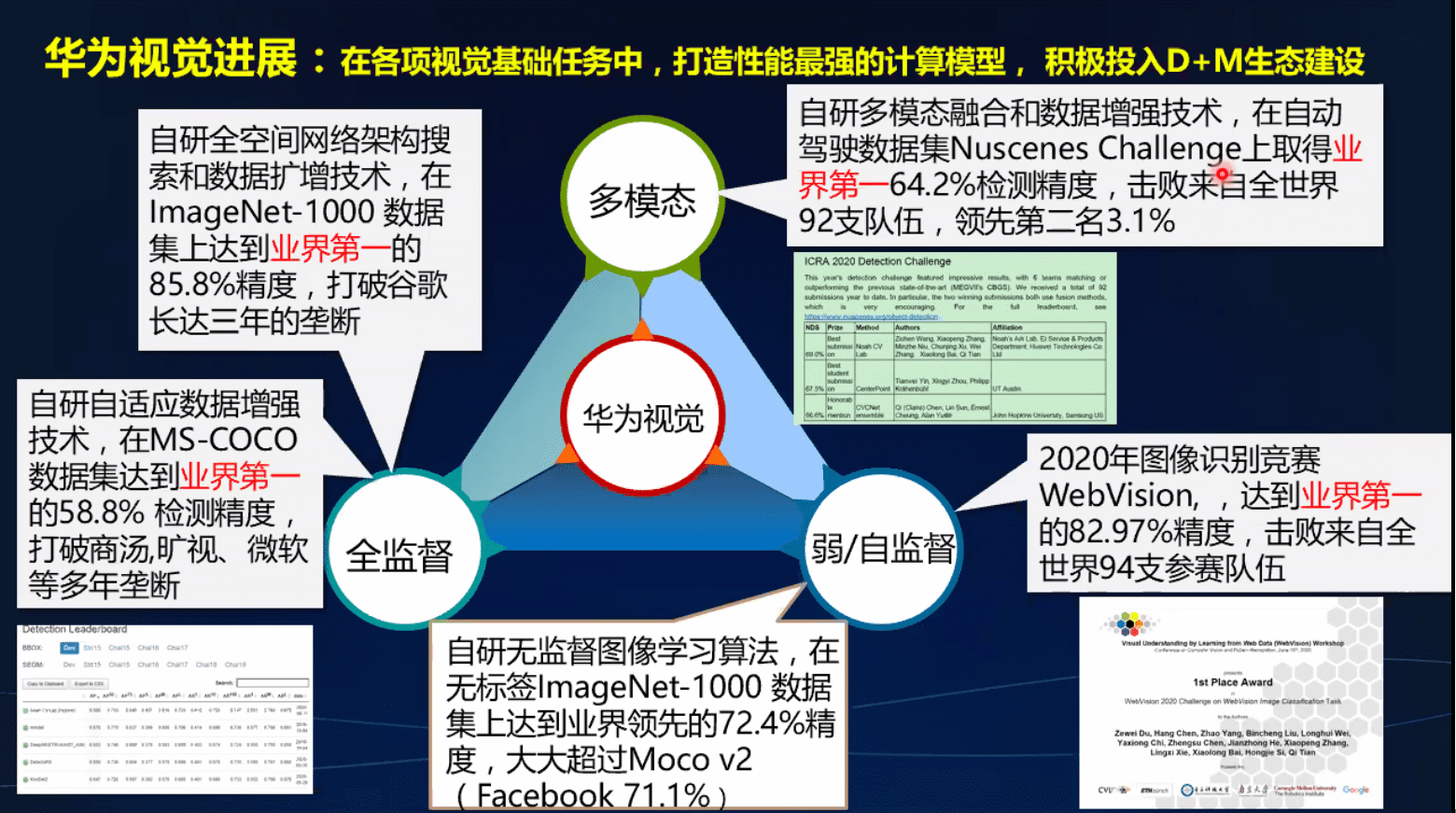
现在, top1:85.8

可解释性

生成图像缺乏常识

技术梗概
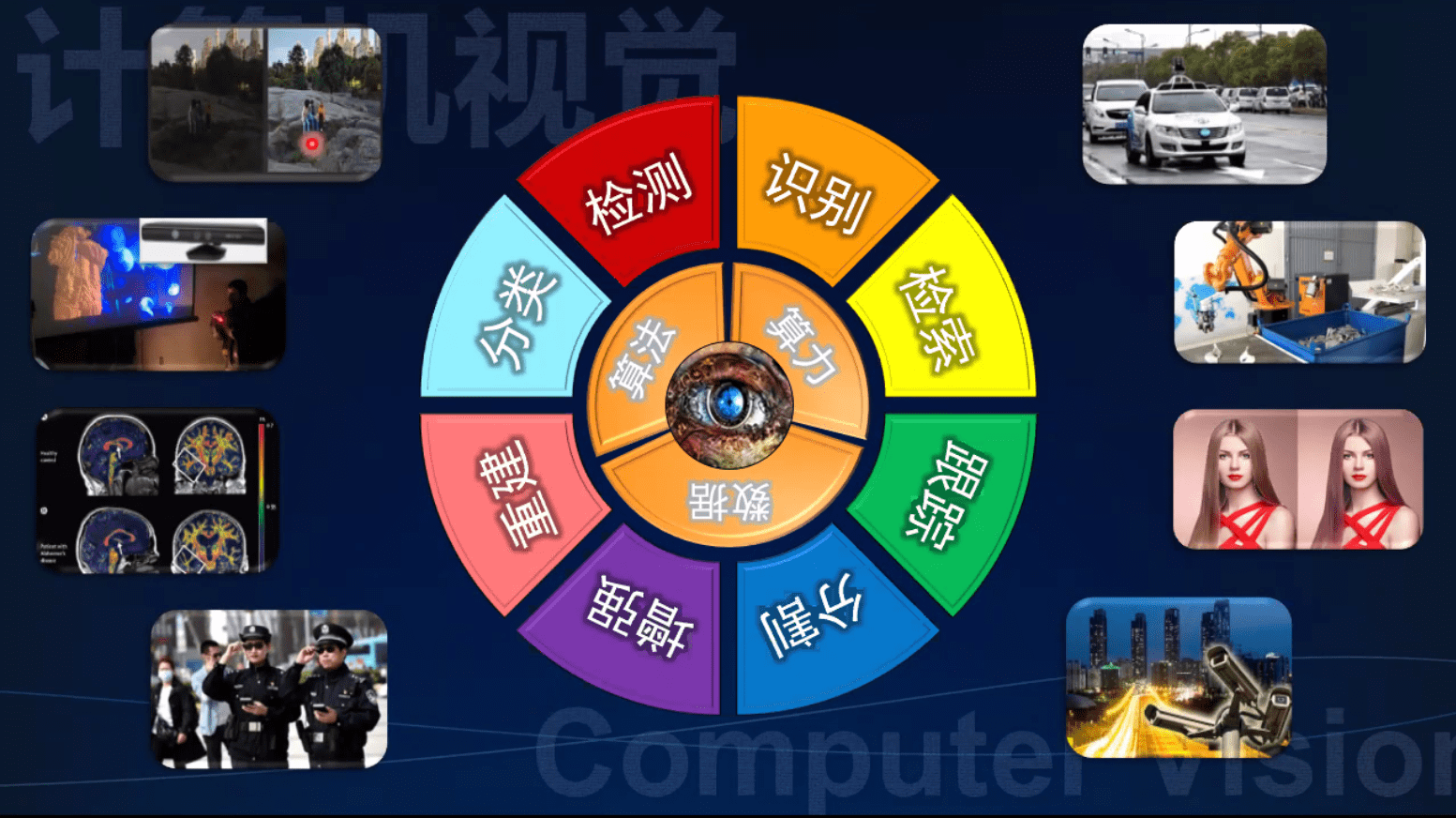



根据特征距离进行检索

跟踪,行程轨迹图
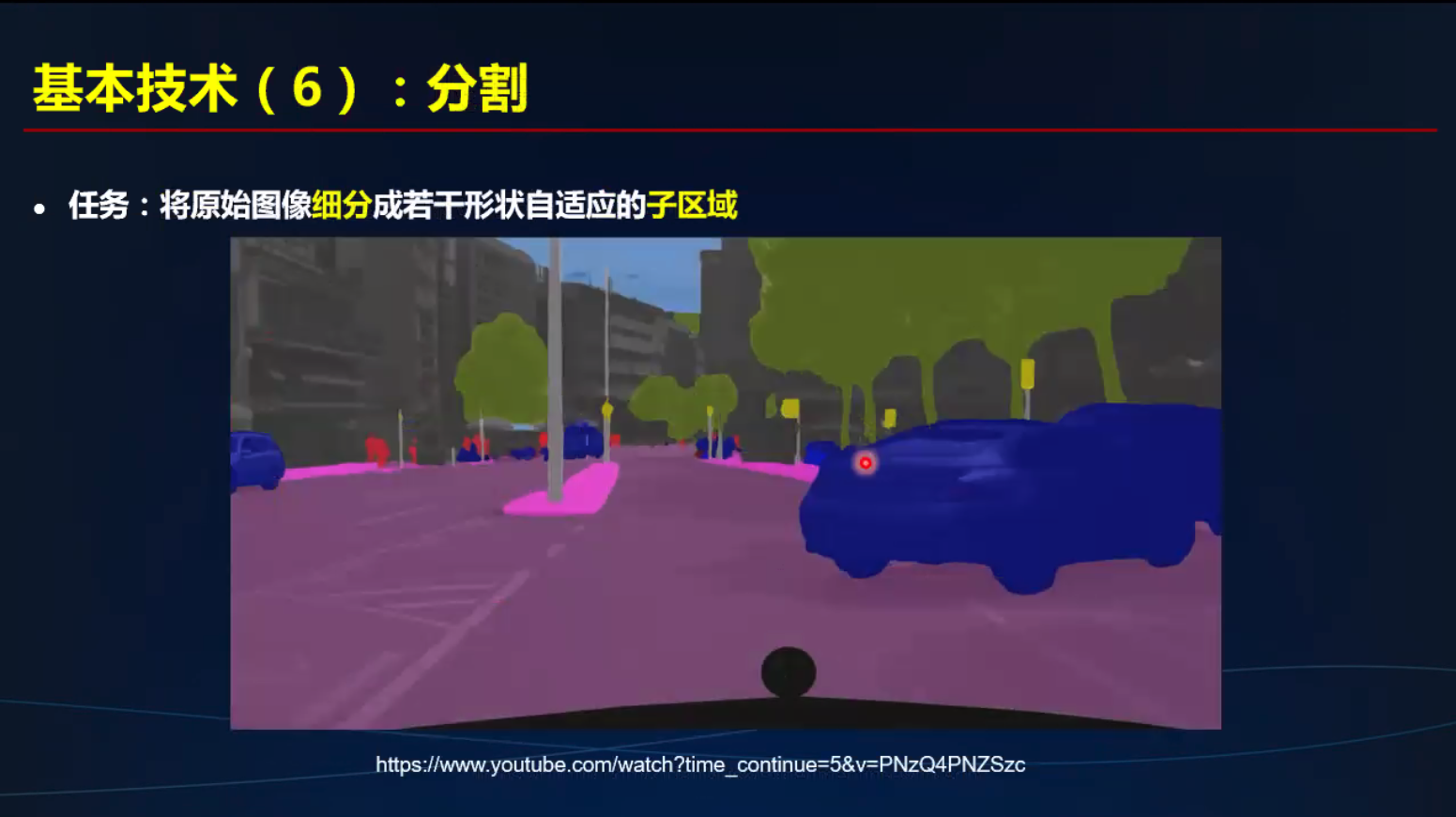
分割

3D重建

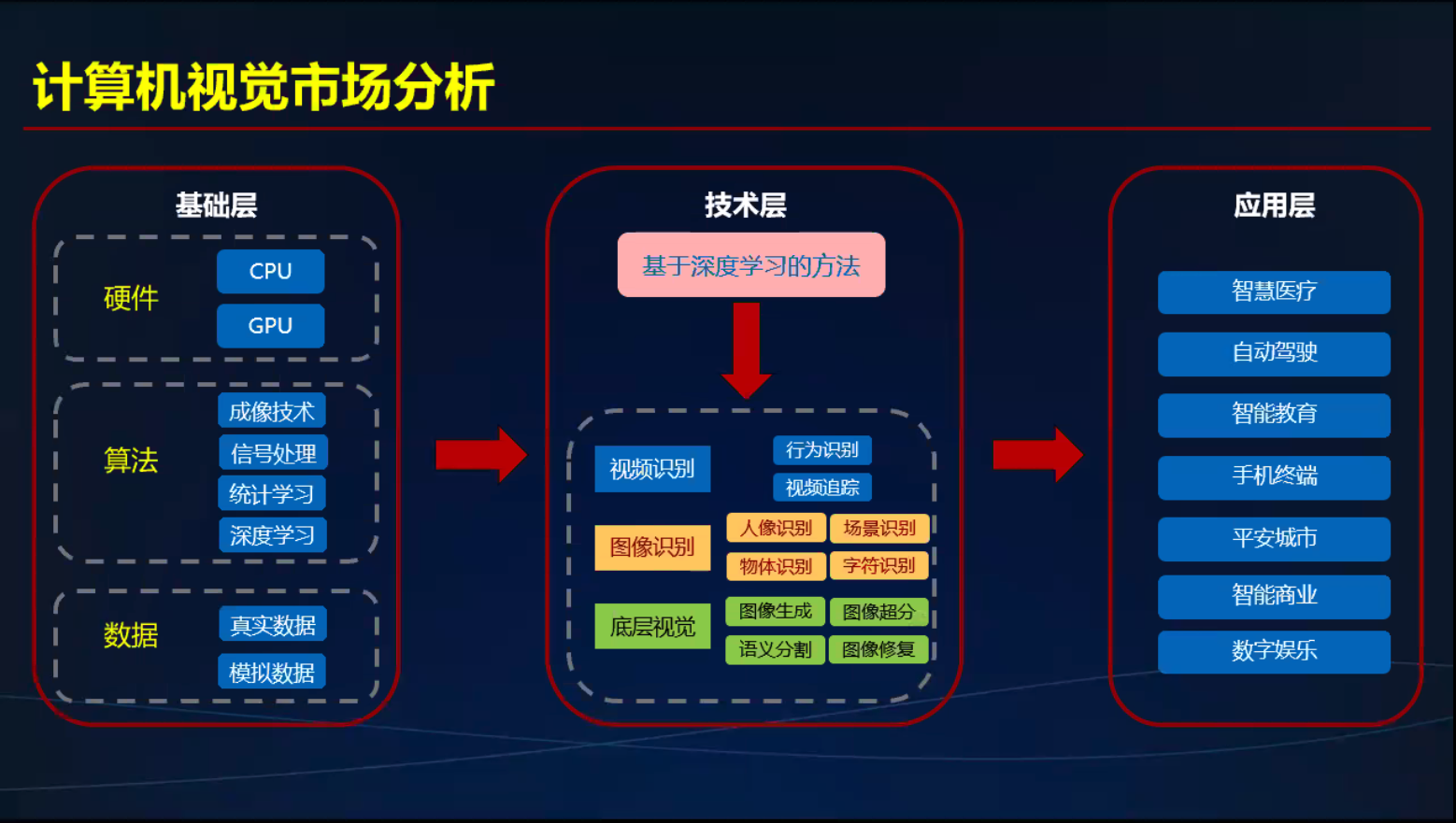
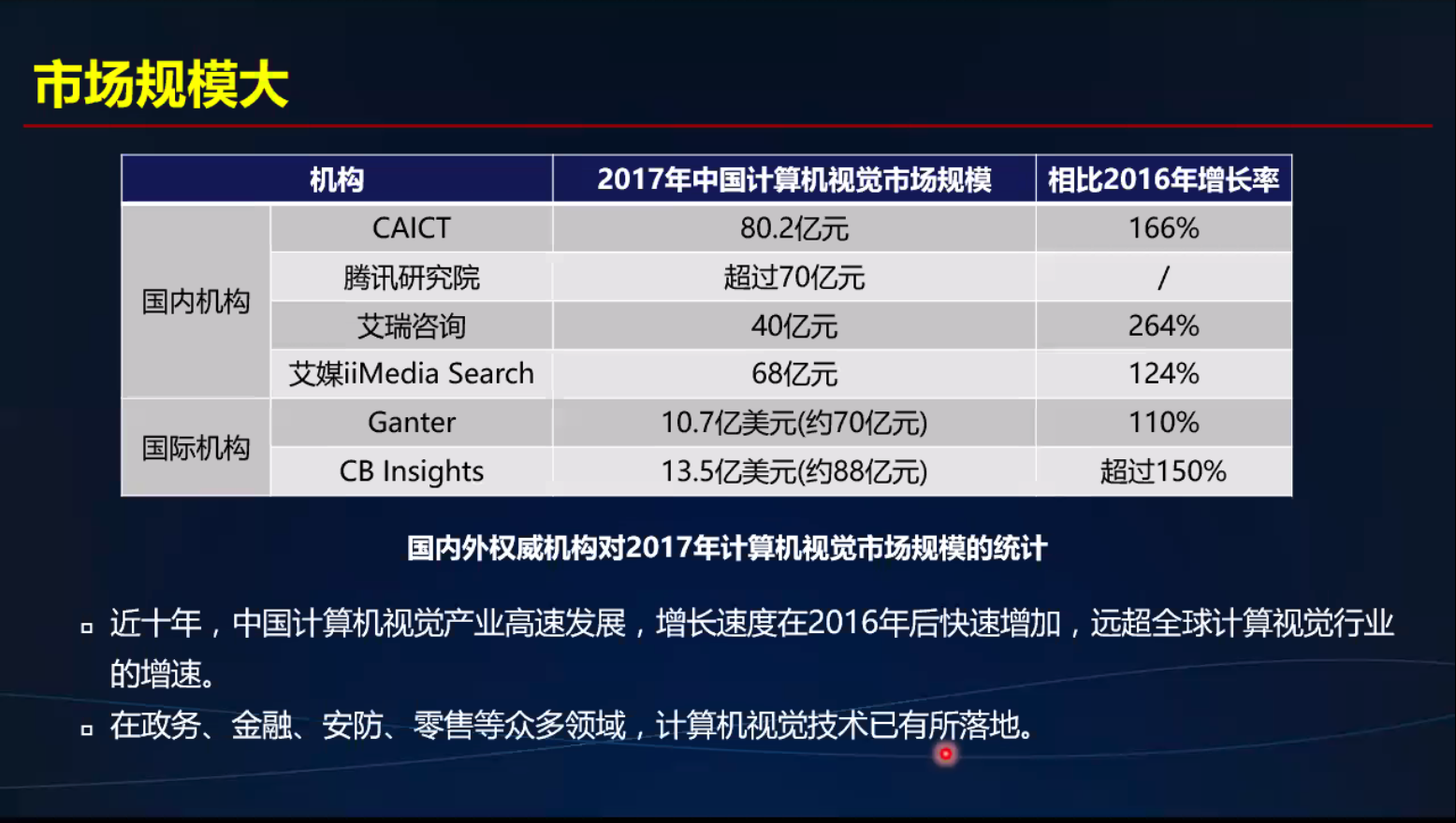
CV应用场景和市场分析
应用场景
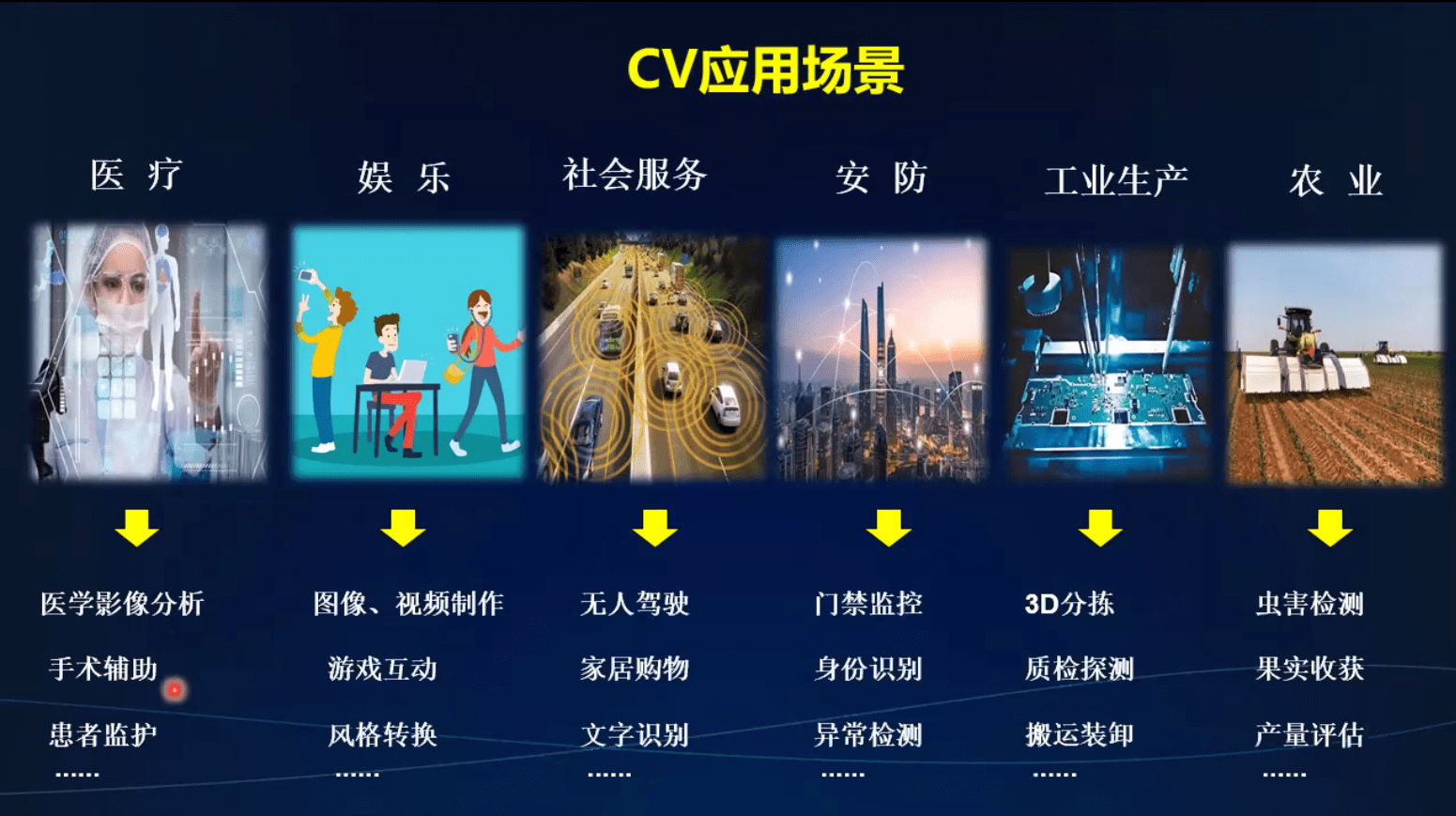







检索 可做

人脸识别挑战



计算机视觉 进步历史 - 自动驾驶为例
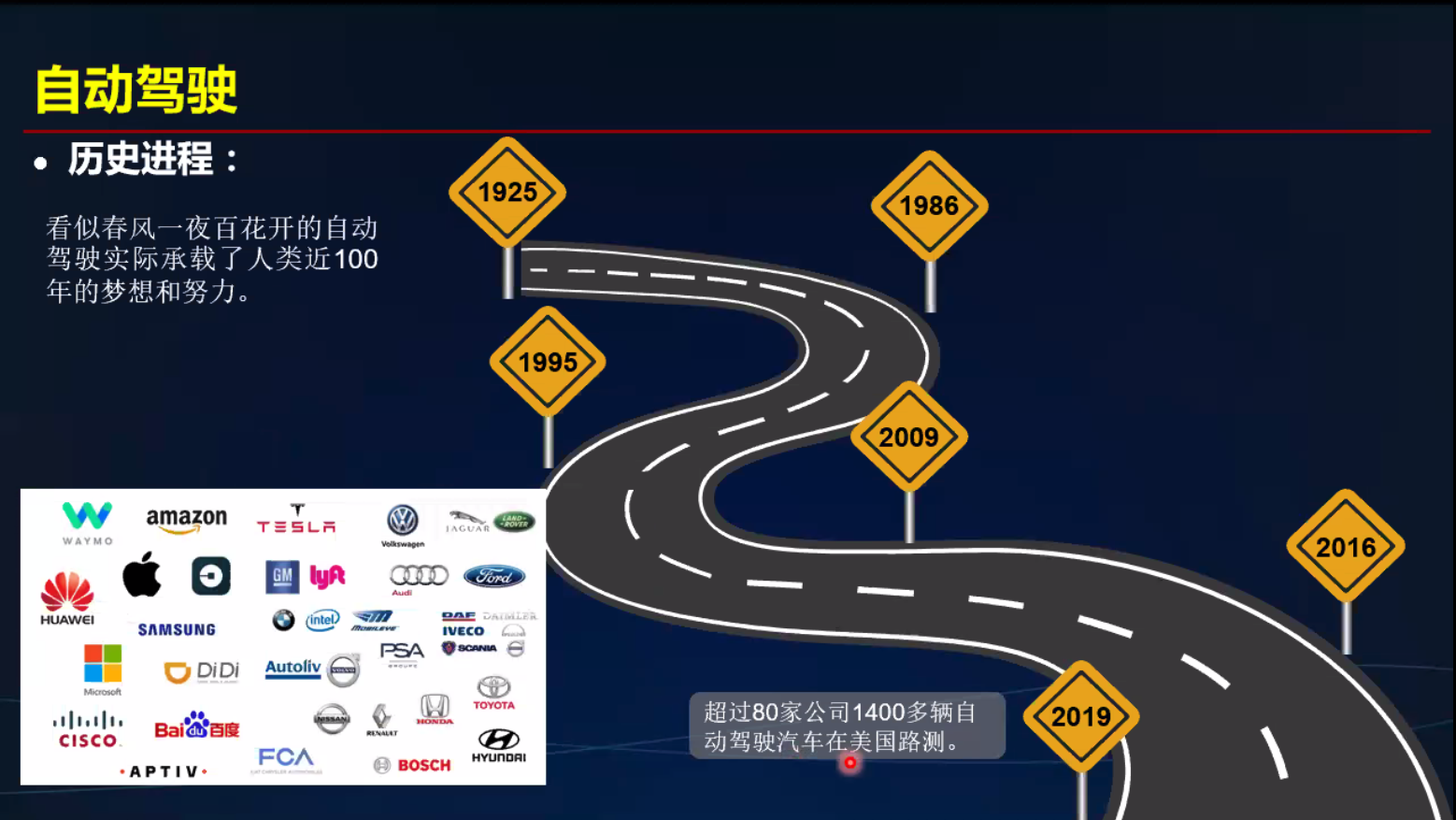
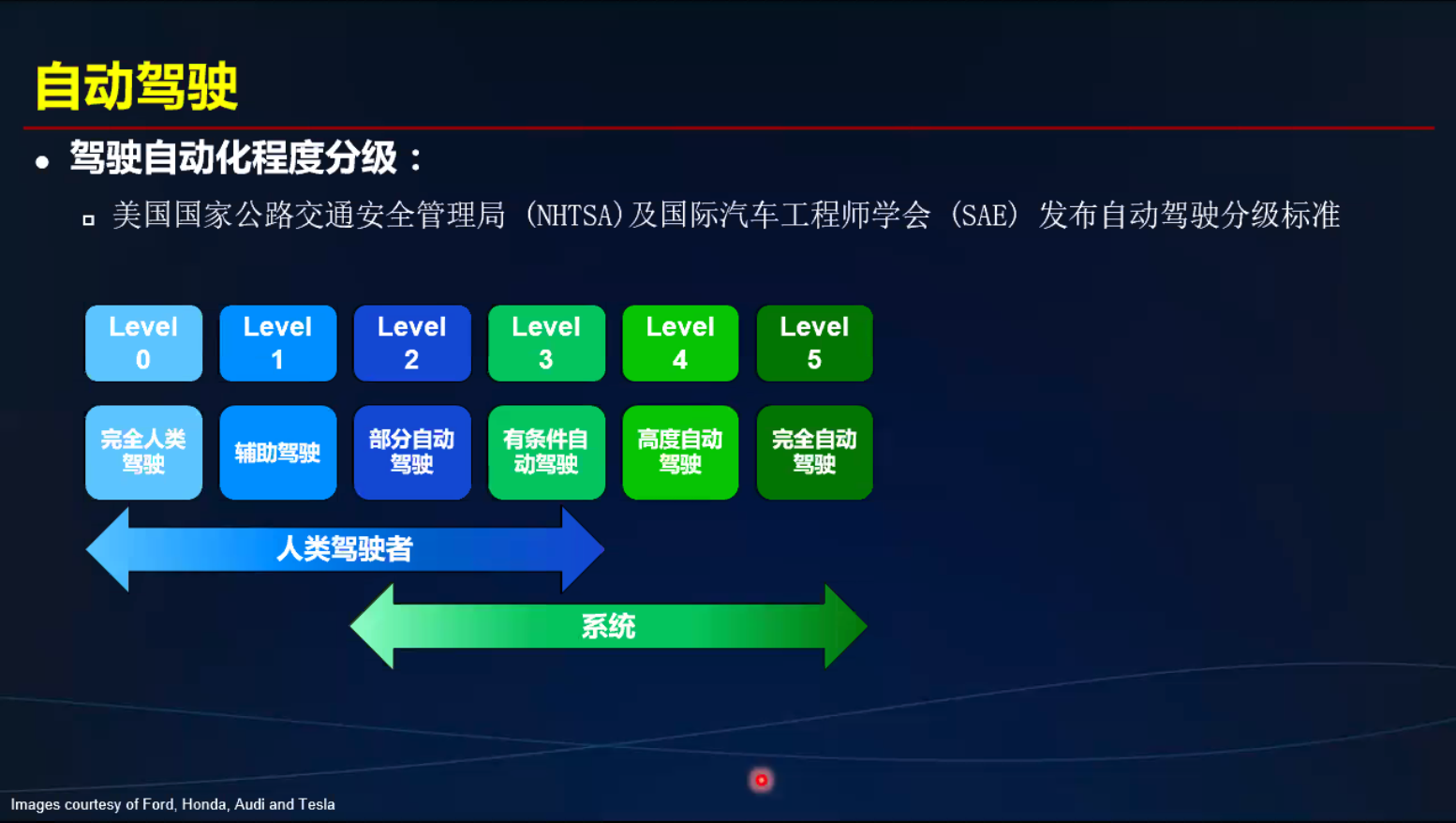
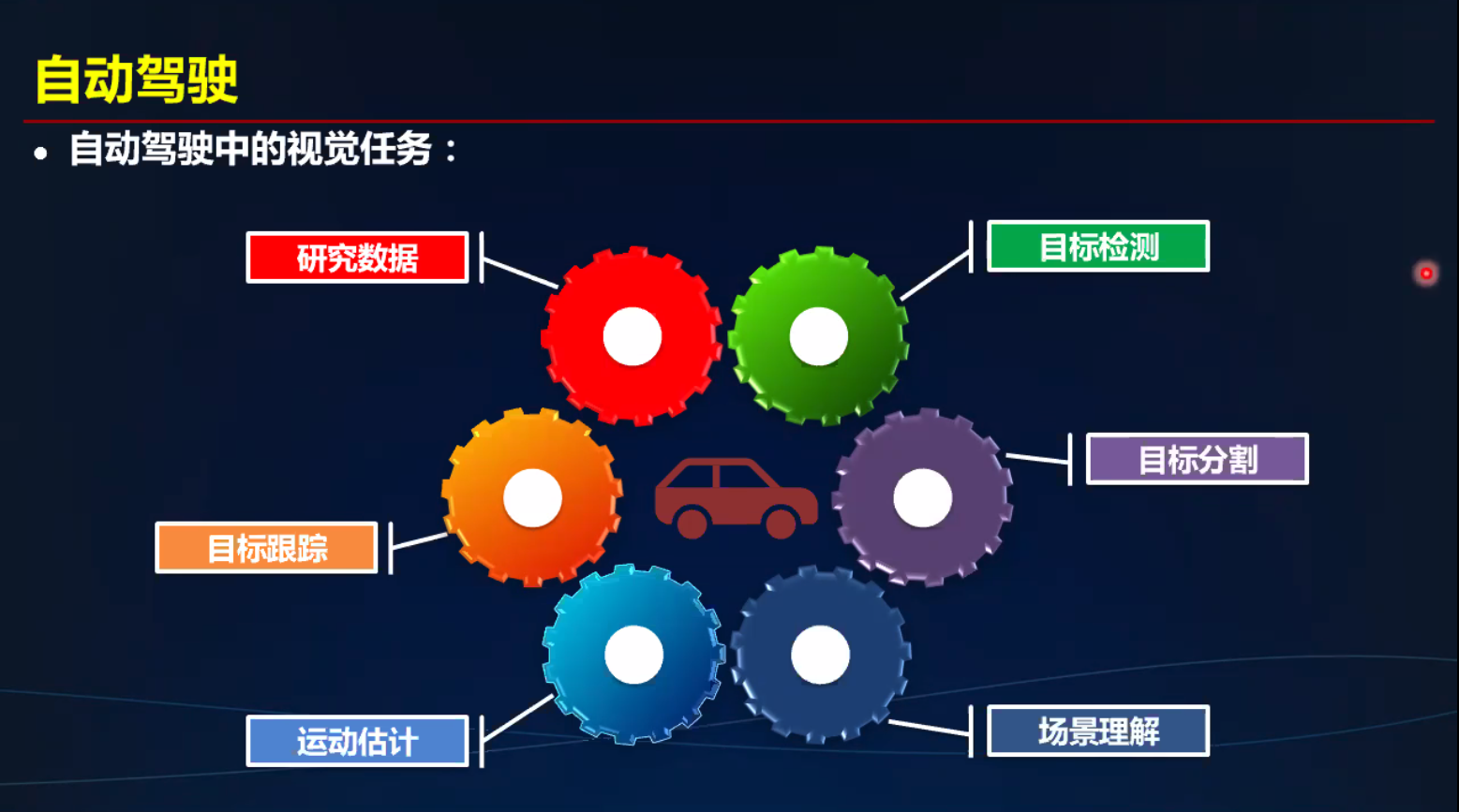




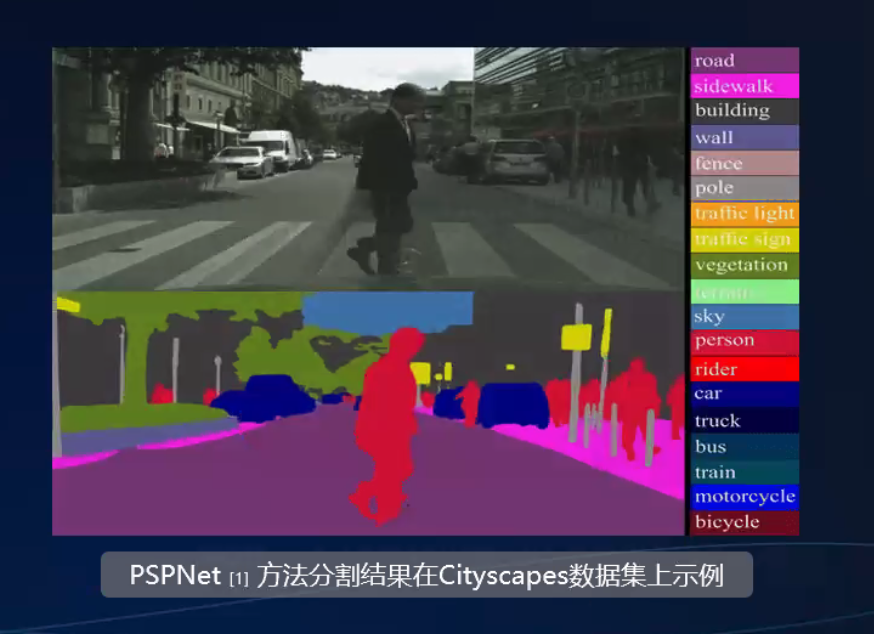

CV引领数字娱乐
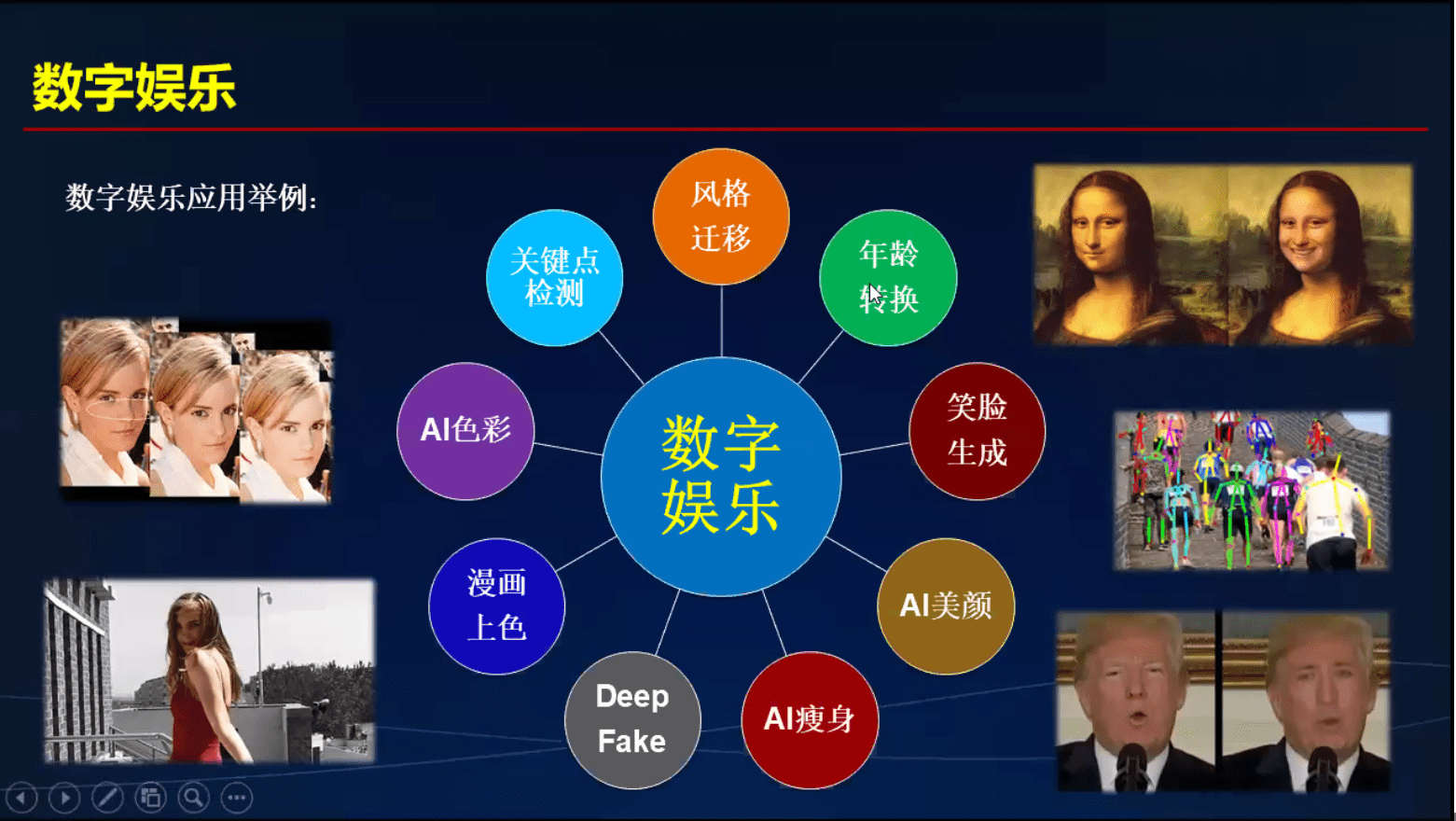
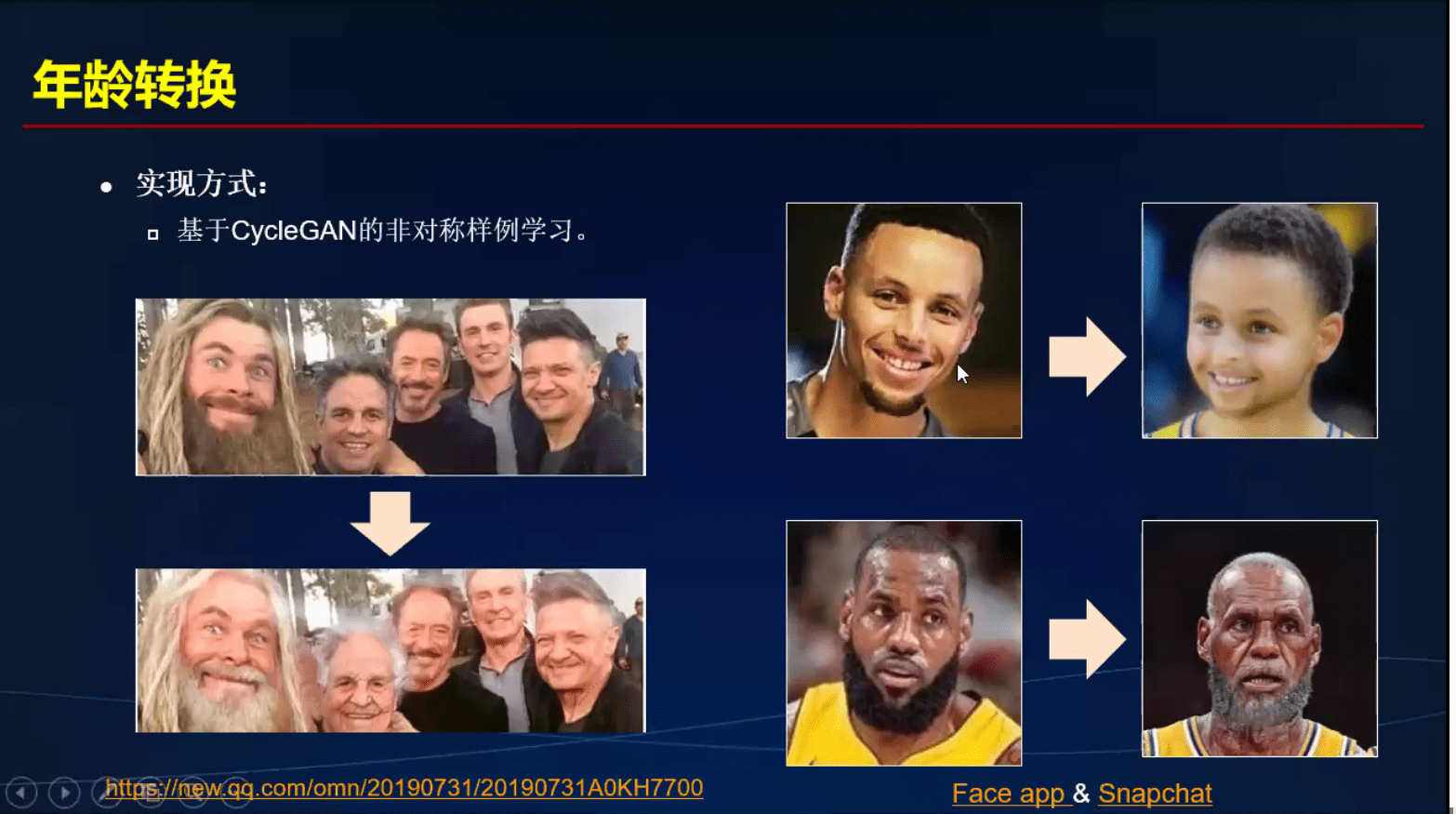





市场分析

软硬件结合



未来发展趋势

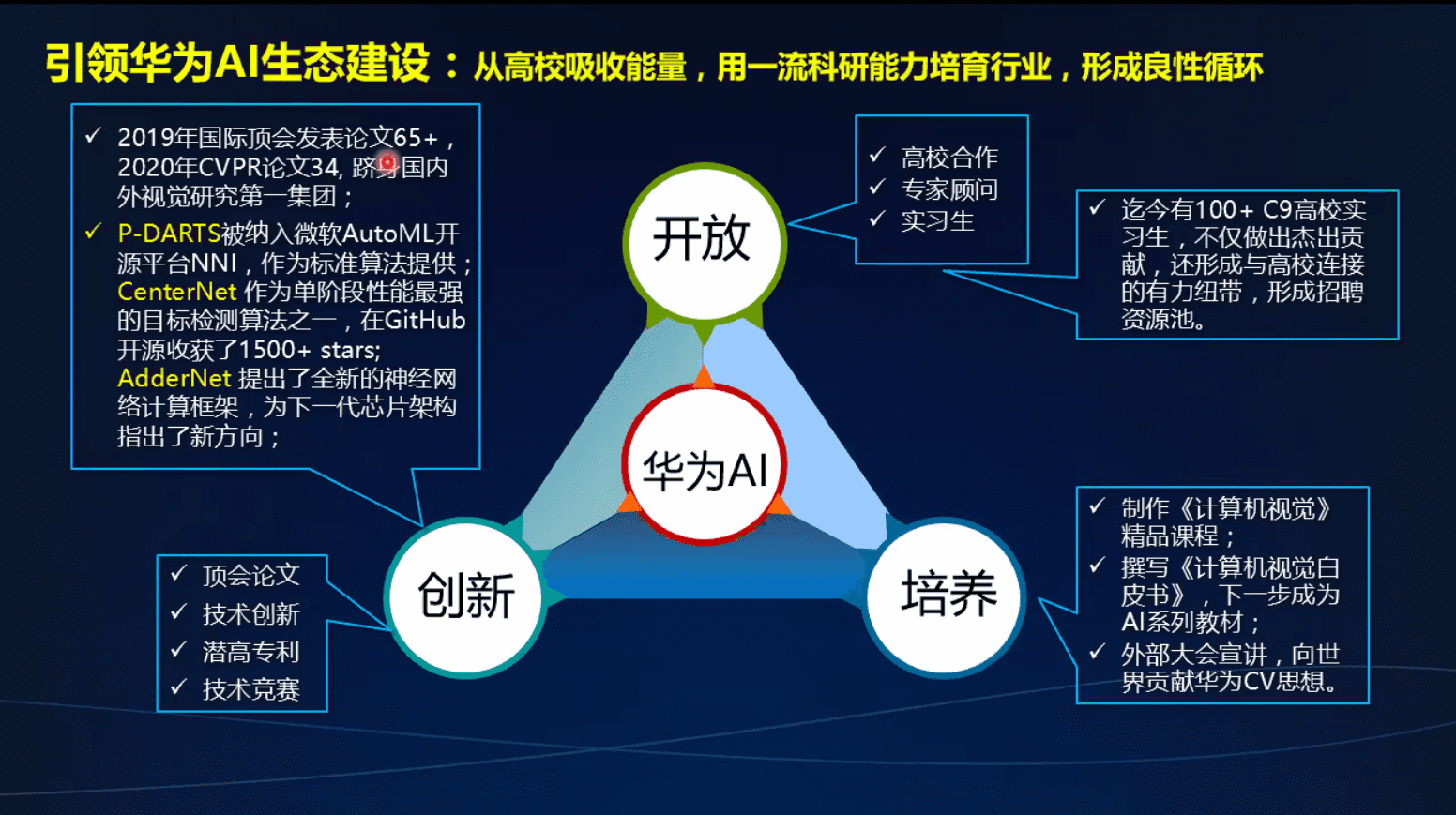
华为视觉研究计划和进展

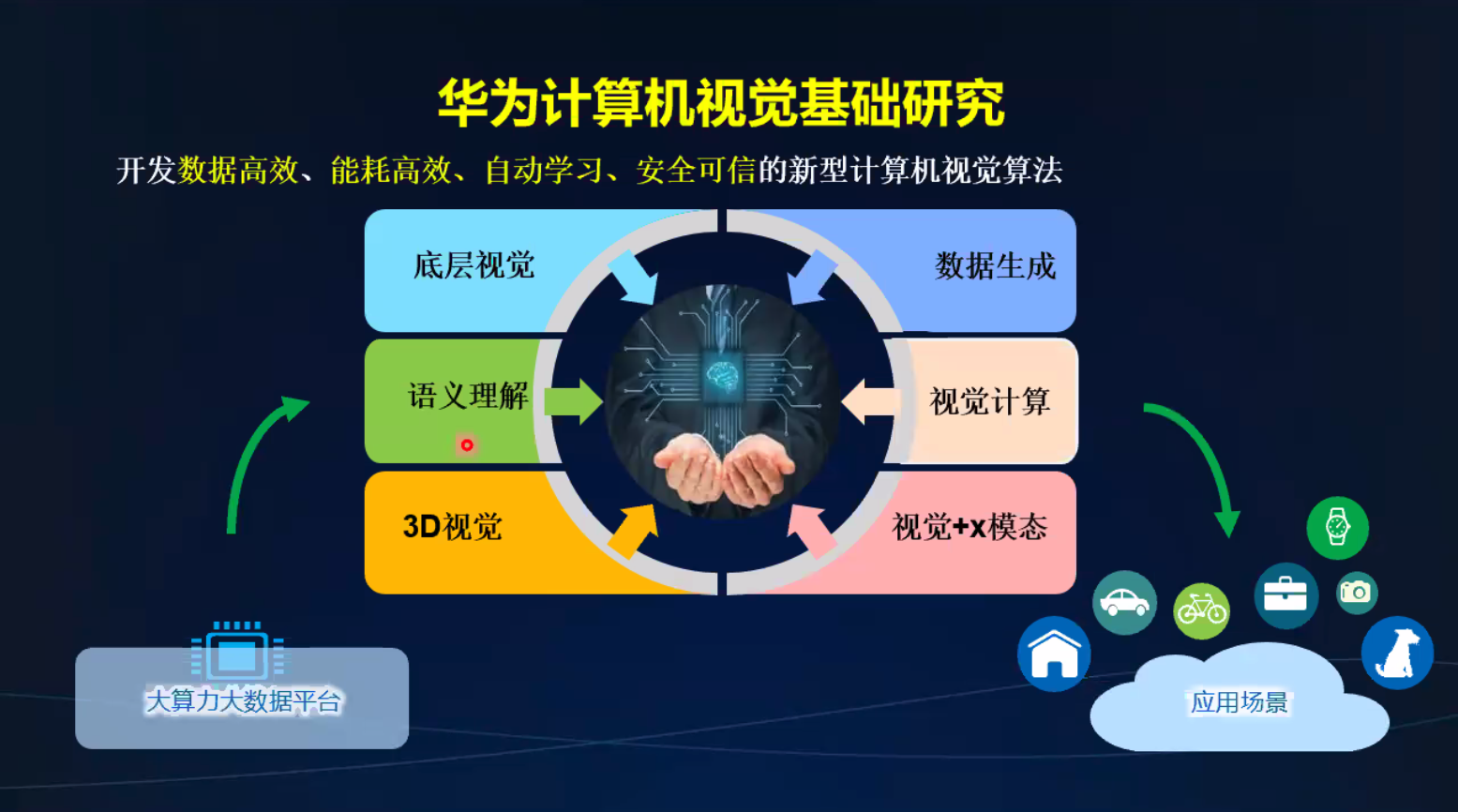


3d视觉


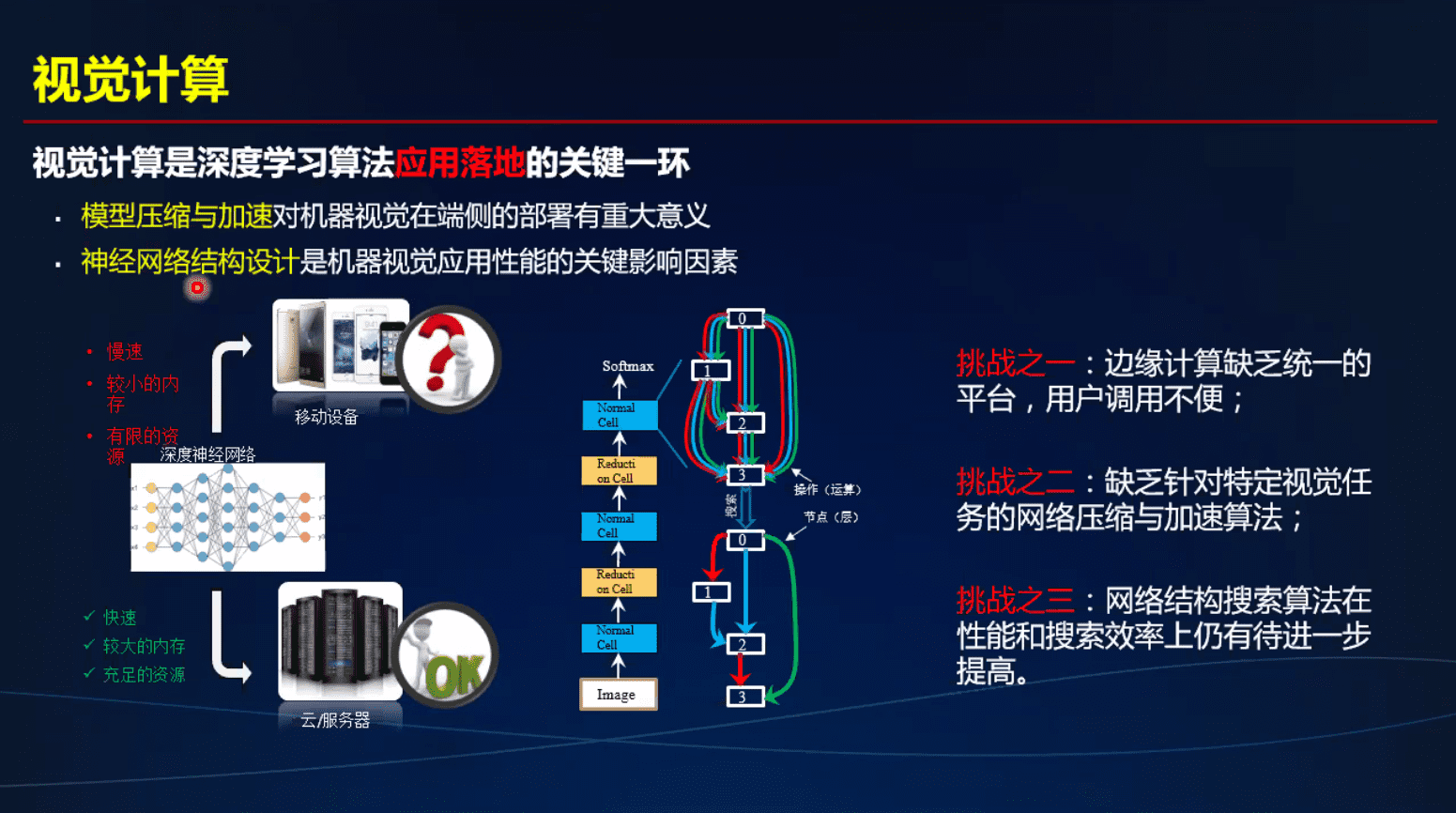

3个研究方向


数据扩增,gan,虚拟数据 可做

最新的iccv2020 – 解决扩增以后产生的歧义 可做?????
用于大规模数据学习 知识蒸馏与数据扩增结合 软分类 ????

-
多模态学习


自动网络架构搜索
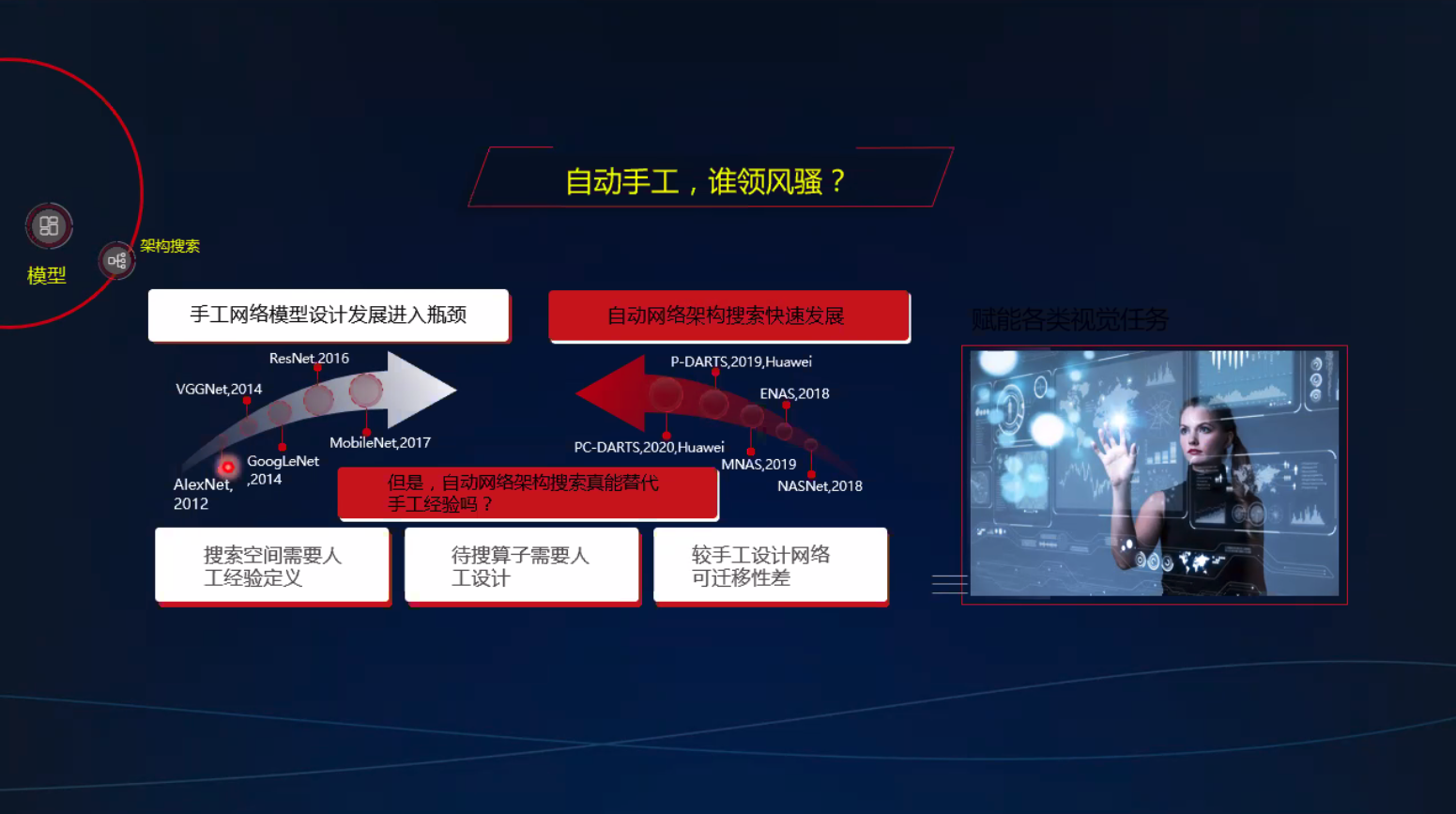


加法代替乘法
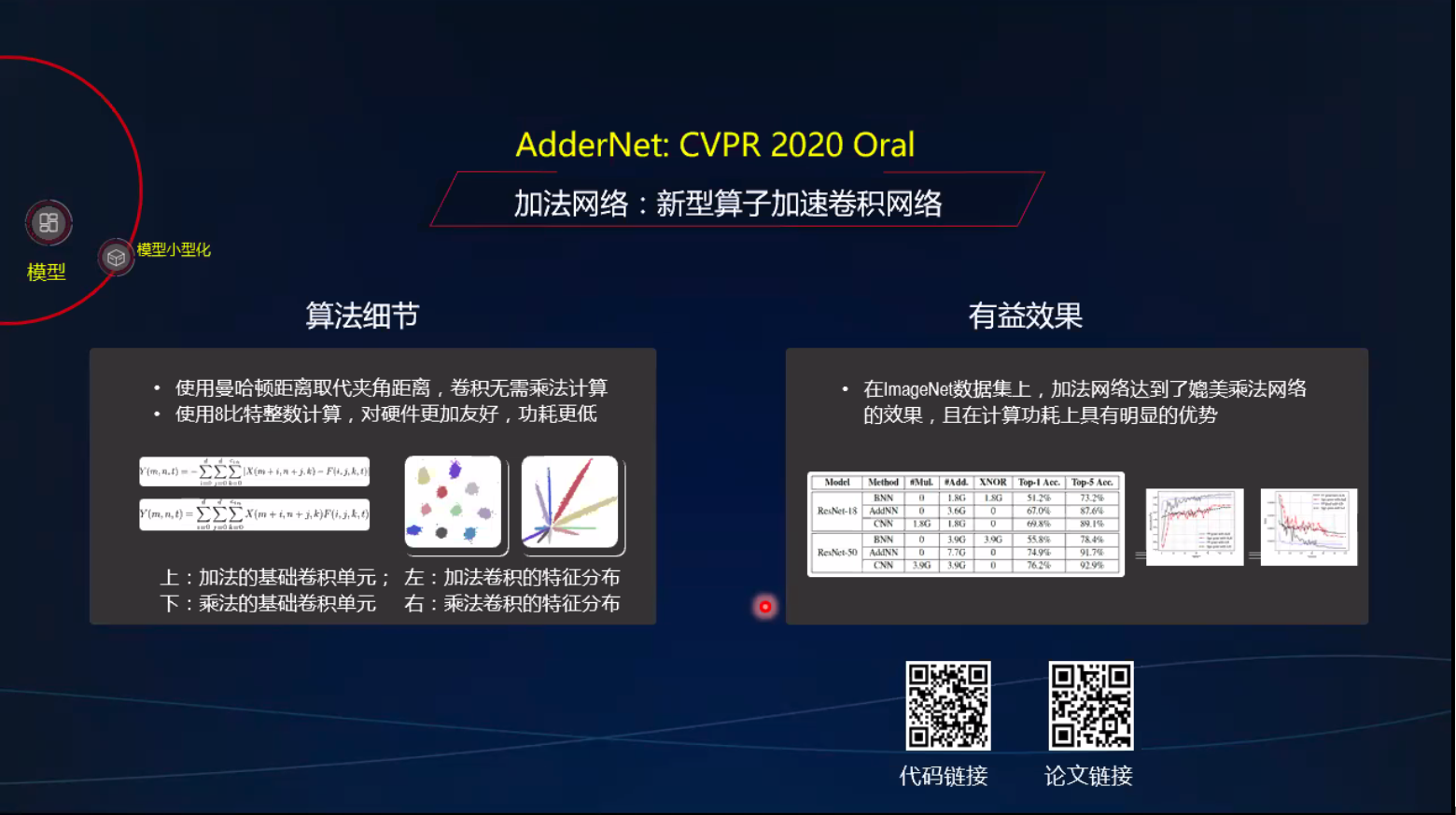
通用智能

自监督学习 – 不够成熟
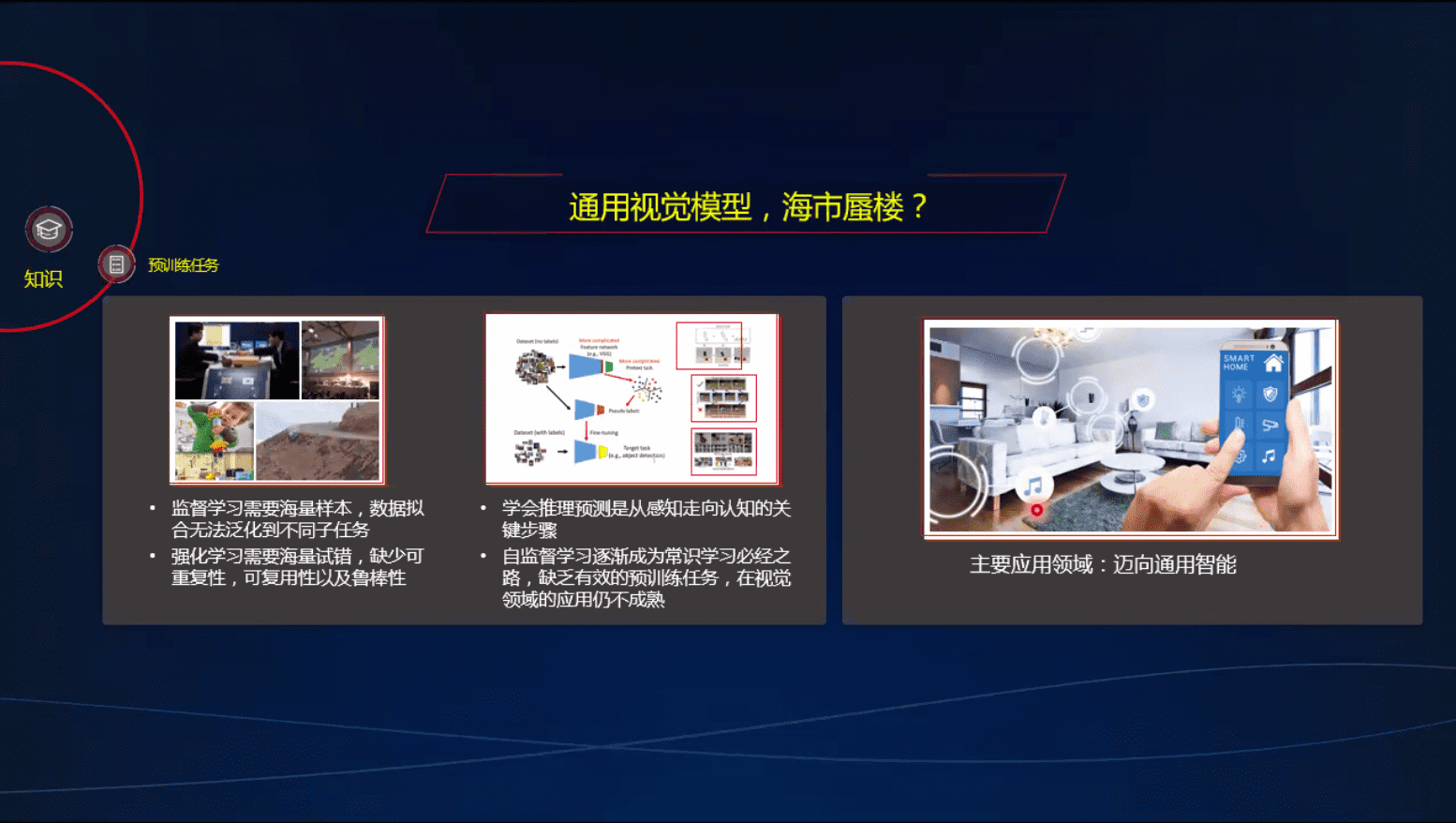
拼图任务

虚拟场景


华为CV研究计划





UNDP
UNDP-SDG Course_for DeeCamp2020_20200711 copy.pdf