blog-综述—图像处理中的注意力机制(https://blog.csdn.net/xys430381_1/article/details/89323444)
Attention in CNN(https://zhuanlan.zhihu.com/p/96975064)
待读 - https://blog.csdn.net/qq_40721337/article/details/106424154
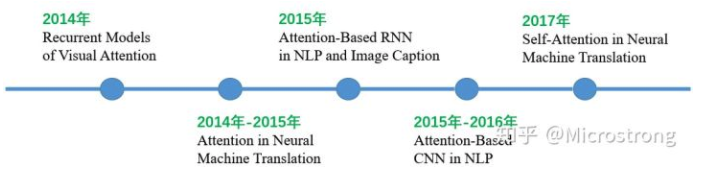
14年, Google Mind发表《Recurrent Models of Visual Attention》论文使attention开始流行, 在RNN上使用attention进行图像分类取得很好性能, 之后研究者将其应用到了NLP, Image caption领域.
17年, Google发表的论文《Attention is all you need》[12]中提出在机器翻译上大量使用自注意力(self-attention)机制来学习文本表示。在CNN上使用
人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
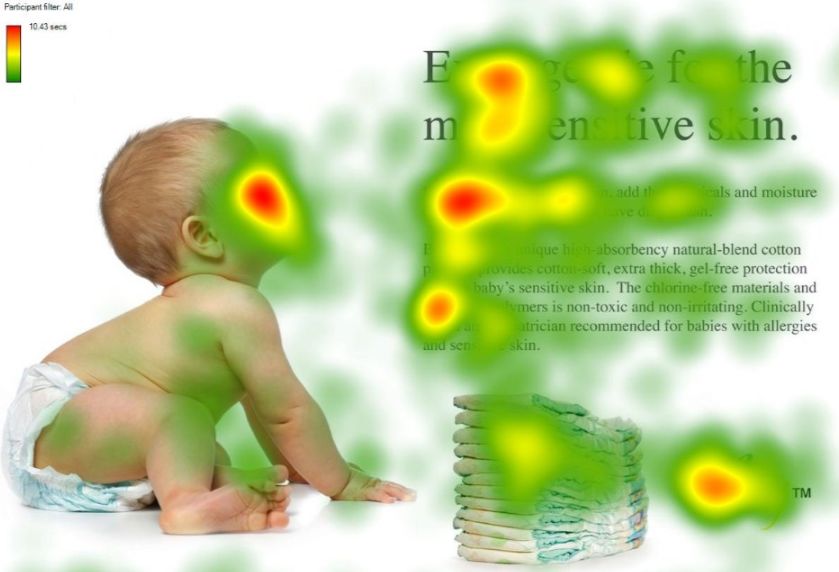
注意力机制的基本思想就是让模型能够忽略无关信息而更多的关注我们希望它关注的重点信息。
DL与CV注意力结合大多基于使用掩码(mask)形成注意力机制.
通过另一层新的权重, 将图片数据中关键的特征标识出来, 通过学习训练, 使神经网络学到每一张图片中需要关注的区域, 就形成了注意力, 即是希望学到一组作用在原图上的权值分布.

因此分为了软注意力( soft attention )和强注意力( hard attention )。
强注意力是一个随机的预测过程,更强调动态变化,同时其不可微,训练往往需要通过增强学习来完成。(没接触过,不是研究的重点)。
软注意力的关键在于其是可微的,也就意味着可以计算梯度,利用神经网络的训练方法获得。这也是本文着重关注的对象。 软注意力的关键点在于,这种注意力更关注区域或者通道,而且软注意力是确定性的注意力,学习完成后直接可以通过网络生成,最关键的地方是软注意力是可微的,这是一个非常重要的地方。可以微分的注意力就可以通过神经网络算出梯度并且前向传播和后向反馈来学习得到注意力的权重。
CBAM( Convolution Block Attention Module )
空间注意力,表现在图像上就是对 feature map 上不同位置的关注程度不同。
反映在数学上就是指:针对某个大小为
的特征图,有效的一个空间注意力对应一个大小为
的矩阵,每个位置对原 feature map 对应位置的像素来说就是一个权重,计算时做 pixel-wise multiply 。

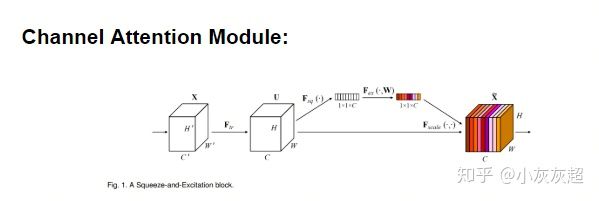
SE Block
这种注意力主要分布在 channel 中,表现在图像上就是对不同的图像通道的关注程度不同。
反映在数学上就是指:针对某个大小为 H×W×C 的 feature map ,有效的一个通道注意力对应一个大小为 1×1×C 的矩阵,每个位置对原特征图对应 channel 的全部像素是一个权重,计算时做 channel-wise multiply 。
简单对比上面两种注意力,空间域是忽略了通道域中的信息,将每个通道中的图片特征同等处理,这种做法会将空间域变换方法局限在原始图片特征提取阶段,应用在神经网络其他层的可解释性不强。而通道域的注意力是对一个通道内的信息直接全局平均池化,而忽略每一个通道内的局部信息,这种做法其实也是比较暴力的行为。所以结合两种思路,就可以设计出混合域的注意力机制模型。
\1. CBAM
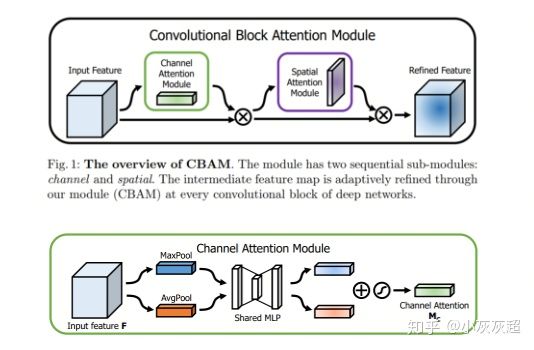
CBAM 中的 channel attention module 和 SE block 几乎一样,唯一的区别在于多了一次 max pooling ,中间 MLP 的参数共享。
这种注意力机制是与深度残差网络相关的方法,基本思路是能够将注意力应用到ResNet中,并且使网络能够训练的比较深。
- 如果给每一个特征元素都赋予一个mask权重的话, mask 之后的信息就会非常少,可能直接就破坏了网络深层的特征信息;
- 另外,如果你可以加上注意力机制之后,残差单元( Residual Unit )的恒等映射( identical mapping )特性会被破坏,从而很难训练。
因此,创新点在于:
残差注意力学习——不仅只把 mask 之后的特征张量作为下一层的输入,同时也将 mask 之前的特征张量作为下一层的输入,这时候可以得到的特征更为丰富,从而能够更好的注意关键特征。???????