参考
赛题相关
方案参考
github:https://github.com/jadyntao/HuaWei_CodeCraft_2020
(分析的比较详细)
队伍:助教小分队(粤港澳赛区) 初赛:0.2102(赛区第5) 复赛:11.8445(赛区第2) 决赛:909.8489(全国第24)
https://blog.csdn.net/qq_42756511/article/details/106594550
github:https://github.com/starfading/Huawei-CodeCraft-2020 队伍:一方通行 初赛:0.2136s (西北Rank 16) 复赛:7.5473s (西北Rank 2) 决赛:674.9344s (总榜Rank 21)
github:https://github.com/Chadriy/CodeCraft2020
队伍:IOT_TEAM(成渝赛区) 初赛: 0.1152 (成渝rank 1/总榜rank 3) 复赛A1: 0.6748 (成渝rank 1/总榜rank 1) 复赛A2: 2.2934 (成渝rank 1/总榜rank 7) 复赛B:3.1988(成渝rank 2/总榜rank 6) 决赛A:300.2459(总榜rank 3) 决赛B:263.7404(总榜rank 5)
github:https://github.com/cxq80803716/2020codecraft (代码较清晰)
队伍: 以上团队均未获奖 初赛粤港澳赛区第一(全国前十) 复赛粤港澳赛区A榜第一(全国第二)
赛题相关
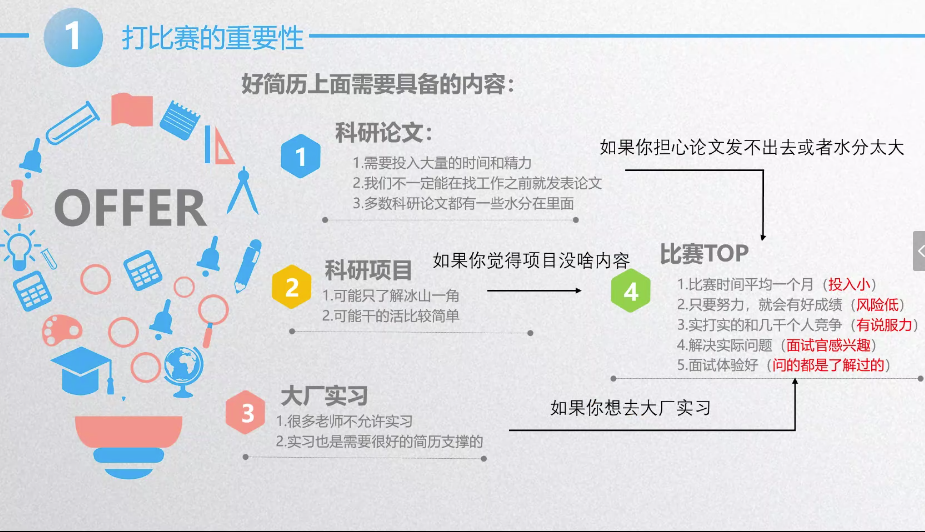
题目— 金融风控的资金流水分析
通过金融风控的资金流水分析,可有效识别循环转账,辅助公安挖掘洗钱组织,帮助银行预防信用卡诈骗。基于给定的资金流水,检测并输出指定约束条件的所有循环转账,结果准确,用时最短者胜。
如果是两个顺时针的圆相交。那么就有3个环,相交形成的叶形区域也要算一个环。
环不能交汇,所以像“8”这样书写顺序的一个环必须当成2个环来考虑。
一个环内,除了首位元素一样,其他不能出现重复的元素
讨论有向环的问题时一般也不考虑边的产生时序。
经验
需求
- 并行数据处理加速 — mmap
经验
进行需求分解
要能肝
主动贡献自己的思维, 不必太硬分工
2020年4月2日比赛经验分享会
视频复盘:西电青苔工作室和西电华了个为
分享1
剪枝
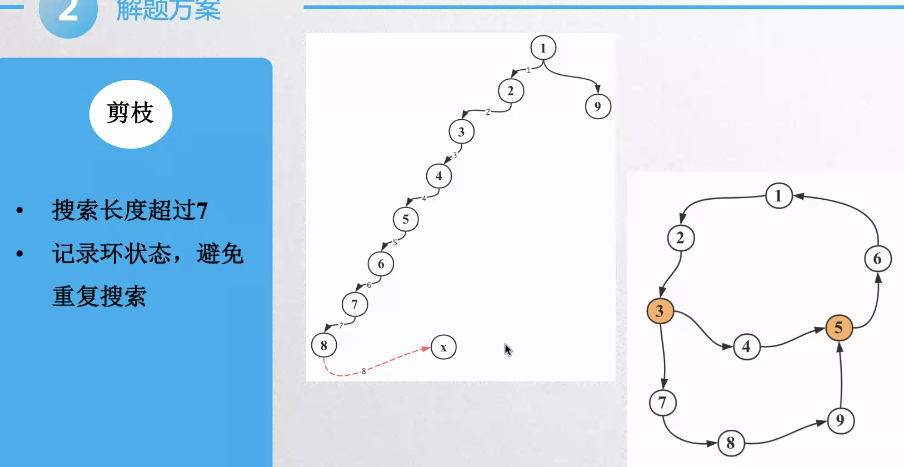
记录环的状态, 哪个找过了就不用找了
可以提高百分70左右 – 记录环的状态
文件io

用mmap — 磁盘和内存映射关系
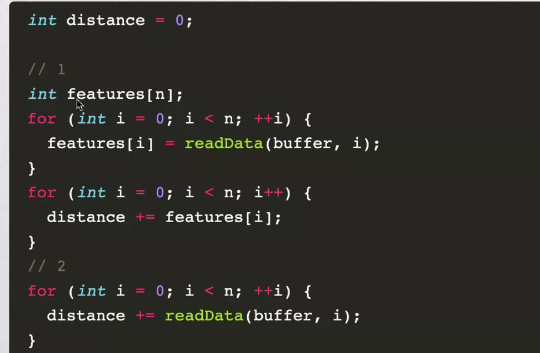
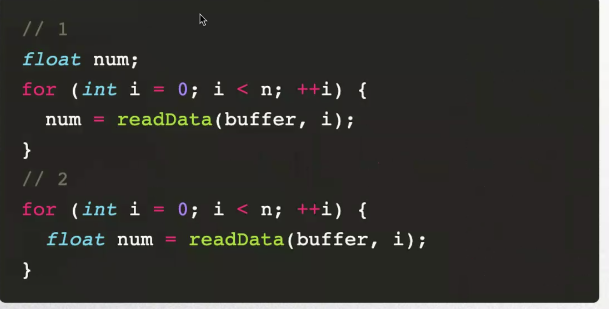
循环优化
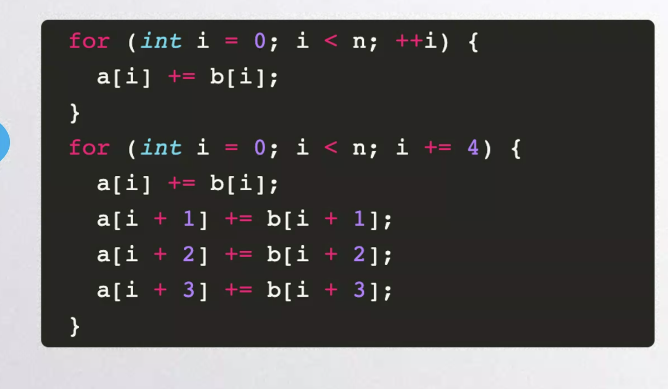
减少中间变量存储
延迟变量存储
Cache对齐 重要 鲲鹏相关

分享2 — 张宝丹学长






优化点
数据结构上的优化点:
IO写入文件— mmap:
-
mmap
-
mmap 采用内存映射的方式,直接将磁盘上的文件映射到内存(准确的说是虚拟内存)中,不需要其他额外空间,对内存映射区的修改可以与磁盘文件保持同步,故 mmap 的读写速度非常快。
-
仅支持 linux 系统, 另外,mmap 映射区域大小必须是物理页大小(page size)的整倍数(32 位系统中通常是 4k 字节)。
-
mmap可以用于多线程上进行文件读写。
1 2 3 4 5 6 7
int fd=open(output_file.c_str(),O_CREAT|O_RDWR,0666); 1==ftruncate(fd,total_offset); char*p=(char*)mmap(NULL,total_offset,PROT_WRITE|PROT_READ,MAP_SHARED,fd,0); memcpy(p,out.c_str(),out.size()); // msync(p,total_offset,MS_SYNC); // munmap(p,total_offset); close(fd);
-
数据存储 — 数组代替vector(可说)
-
方法(trick):
- 由于不同结点的出度数不一 , 无法指定数组大小 —> ,使用vector是在空间上最合适的方法,但相比于数组来说访问效率要低很多。
- 但是在初赛结束前一天,测试出来线上数据集的最大结点不超过5W,最大出度不超过50,—> 因此改成了静态数组 unsigned int Graph[maxn][50],提升上了第5名。
-
经测试,在效率上,数组 > 动态数组 > 预先reverse的vector > vector的效率,vector的执行效率比数组要低将近10倍。
-
数组是底层数据类型,存放在栈中,其内存的分配和释放完全由系统自动完成,效率最高;
1 2
//全局变量,只能根据最大转账记录250W来假设最大账号数maxn500W unsigned int dis[Tnum][maxn];
-
动态数组是程序员由new运算符创建的,存放在堆中,需由delete运算符人工释放,否则会内存泄露;
1 2 3 4 5 6 7 8 9 10
//全局变量 unsigned int *out_du_num; ... void get_input(){ ... //可以根据实际的账号数来申请空间 //(实际账号数必然小于500W,猜测华为线上数据比500W小不少) out_du_num = (unsigned int*)calloc(max_id, sizeof(unsigned int)); out_du_num = new unsigned int[max_id]; } -
vector
-
存放在堆(效率低于栈区)中,由STL库中程序负责内存的分配和释放,使用方便。
-
若添加元素时超过vector容器的空间大小,为保证元素内存的连续性,vector会重新申请原容量2倍(实际测试是3倍)的连续空间,再将原来的元素复制过去。
-
动态自增加:重新配置、元素移动、释放原空间。
-
二维vector每个行的数据是连续存放的,但是行与行之间是不连续存放的。
-
因此跨行访问时局部性降低,Cache命中率下降。所以跨行遍历时用时间更多。
1 2 3
//第一维是实际结点数,第二维是对应的指向结点 vector<vector<int> > Graph; Graph = vector<vector<int> > (node_num);
-
-
预先reverse的vector:vector.size()是指容器当前拥有的元素个数,vector.capacity()指容器在必须分配新存储空间之前可以存储的元素总数,capacity总是大于或等于size的。reserve()改变的是capactity,resive()改变的是size。
-
- 申请效率:
- 栈由系统自动分配,速度较快。但程序员是无法控制的。
- 堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
- 申请大小的限制:
- 栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是2M;
- 堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。
- 申请后系统的响应
- 栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
- 堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。
- 申请效率:
删重排序
- 根据官方赛题文档中,转出账号和转入账号均为无符号整型,故需要对所有转账账号进行删重并排序,再将其映射到0…max_id,才能在邻接表中遍历。经测试,使用vector的方法速度上略快与set,但无明显的性能差距。
- 使用vector:通过深拷贝vector,再使用sort快排进行排序,再使用erase函数进行删重。
1
2
3
4
5
6
vector<unsigned int> inputs;
vector<unsigned int> id_arr;
...
id_arr = inputs;//深拷贝,修改id_arr的值不影响inputs的值
sort(id_arr.begin(), id_arr.end());
id_arr.erase(unique(id_arr.begin(), id_arr.end()), id_arr.end());
- 使用set:set是基于红黑树实现的,具有删重与自动排序的功能,其插入访问删除的复杂度均为O(lgN)
建图
-
对于有向图的存储主要有4种方法:邻接矩阵、邻接表、前向星、链式前向星。
- 由于转账结点数较大,**内存有限 **—>邻接矩阵的方法一开始就不适用了
- 初赛的时候不需要记录边权,只尝试了数组邻接表和vector邻接表 —> 速度上显然数组邻接表 > vector邻接表;
- 复赛时赛题取消了平均出度为10的限制,由于存在一些结点的出度数或入度数很大 —> 无法使用数组邻接表,经测试,在速度上速度其实相差不大,没有明显的差距: 前向星>vector邻接表>链式前向星
-
- 使用二维数组矩阵来储存图的数据结构,矩阵的大小为node_num * node_num,因此并不适用这次的比赛中转账账号数量比较大的场景(内存不够),也不使用于顶点数量多而边数量少的场景(矩阵比较稀疏,有较多元素为0,对存储空间比较浪费)。
-
- 也是二维的数组或vector,第一维(行)的大小为总顶点数,第二维(列)的大小不一,以每一行下标为结点的出结点数量,储存的元素为出结点。
-
- 前向星是以存储边的方式来存储图,先将边读入并存储在连续的数组中,然后按照边的起点进行排序,这样数组中起点相等的边就能够在数组中进行连续访问了。
- 它的优点是实现简单,容易理解,缺点是需要在所有边都读入完毕的情况下对所有边进行一次排序,带来了时间开销,实用性也较差,只适合离线算法。
-
- 链式前向星其实相当于静态建立的邻接表,以存边为主,时间效率为O(m),空间效率也为O(m)。遍历效率也为O(m)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
//边的数据结构 struct Edge { int next;//下一条边的编号 int to;//这条边到达的点 int dis;//这条边的长度 }edge[maxm]; //加入一条从from到to距离为dis的单向边 void add_edge(int from,int to,int dis) { edge[++num_edge].next=head[from]; edge[num_edge].to=to;//将to记录 edge[num_edge].dis=dis;//将dis记录 head[from]=num_edge;// } //遍历 for(int i=head[k];i!=0;i=edge[i].next){ ... } -
结果排序
-
根据题目要求,先对环的长度升序,再对ID大小排序,由于结果的总环数可能在百万级别,故排序的选择会对总运行时间产生很大影响。
- test_main5.cpp: Graph中每一行的出结点并没有排序,输出的结果中自然环的长度乱序,ID号也是乱序的,要对总的结果进行一次sort快拍,线上时间为2.8S
- test_main7.cpp: 对不同长度的环分别用不同的数组去存,然后即可对不同长度的进行快排,O(lgn)> O(mlg(n/m)),线上时间为2.59s
- test_main13:对Graph每一个结点的出结点先进行排序,这样得到的结果就已经是符合题目要求,不用在进行一次排序,线上时间为1.55s。可以推测,线上数据集的结点数比较少,而环比较多。
- test_main24:由于dfs函数是多线程运行的,故将写入文件时的结点转字符串放到dfs里,额外定义数组来存储结点、在output中的起点、对应长度环的数量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
void dfs(unsigned int head,unsigned int cur,int depth,int tid){ ... ... //找到环 if( lastone[tid][v] == head+1 && depth){ if(!per_size[head][depth][2]){//环数量 per_size[head][depth][1]=offset[tid][depth];//起点 per_size[head][depth][0]=tid;//对应的线程编号 } path[tid][depth+1]=v; for(int i=0;i<depth+2;i++){ memcpy(outbuf[tid][depth]+offset[tid][depth],str[path[tid][i]].c_str(),str[path[tid][i]].size()); offset[tid][depth] += str[path[tid][i]].size(); } res_size[tid]++; outbuf[tid][depth][offset[tid][depth]-1]='\n'; if( per_size[head][depth][1]==0){ per_size[head][depth][0] = tid; } per_size[head][depth][2] = offset[tid][depth] - per_size[head][depth][1]; ... } } }
-
-
整型转字符串
- 由于发现线上数据集是结点少,而环的数量大的情况,故先用字符串数组存:各个结点的字符串+”,”;这样写入文件时就可以不需要重新对所有结果使用整型转字符串,转成寻址。此优化在速度上快了不少。
- 自定义的整型转字符串的函数,相比于STL库中的to_string()略快,但其实效果不明显。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
inline string myto_string(int value) { static const char digits[19] = { '9','8','7','6','5','4','3','2','1','0', '1','2','3','4','5','6','7','8','9' }; static const char* zero = digits + 9; char localbuf[32]; int i = value; char *p = localbuf + 32; *--p = '\0' ; do { int lsd = i % 10; i /= 10; *--p = zero[lsd]; } while (i != 0); return string(p); }- 粤港澳赛区初赛第一的大佬自定义的itoa,速度上有明显提升
1 2 3 4 5 6 7 8 9 10 11 12 13 14
void itoa(int d, char* c, char* l) { /*将结点转为字符串*/ char* s = (char*)malloc(11*sizeof(char)); int i = 10; s[i--] = ','; while (d > 0) { s[i--] = d % 10 + 48; d /= 10; } *l = 10 - i; memcpy(c, s+i+1, 10 - i); }
-
赋值优化
- 对于一些for循环,如for(;判断条件;)中的判断条件,或者循环中需要多次使用的遍历,涉及到vis[x]或x.size()等需要寻址的,会导致每次使用都需要寻址一次,故优化成:提前用一个临时局部变量来存,在速度上有一丢丢但不明显的提升,也尝试使用全局变量来存,但实际测试中还慢了,可能是对全局变量的寻址转换较慢,cache的命中率低。
1 2 3 4 5 6 7
unsigned int *it=Graph[cur]; unsigned int *it_end = Graph[cur] + size1[cur]; while(*it<head && it!=it_end) it++; for(;it!=it_end;++it){ unsigned int &v=*it; ... }
-
对于获取到环结果时,由原来的vector.push_back() 改成vector.emplace_back(),再最后改成数组使用memcpy赋值。
- push_back():使用push_back()向容器中加入一个右值元素(临时对象)时,首先会调用构造函数构造这个临时对象,然后需要调用拷贝构造函数将这个临时对象放入容器中。原来的临时变量释放。这样造成的问题就是临时变量申请资源的浪费。
- emplace_back():与push_back()的区别是 在容器尾部添加一个元素,这个元素原地构造,不需要触发拷贝构造和转移构造。而且调用形式更加简洁,直接根据参数初始化临时对象的成员。
- 拷贝函数主要有3种:速度上copy() < memmove() = memcpy()
- memmove()与memcpy()的区别:memmove函数的功能同memcpy基本一致,但是当src区域和dst内存区域重叠时,memcpy可能会出现错误,而memmove能正确进行拷贝。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
//测试代码 执行2000w次长度为7的整型数组的拷贝赋值 //测试结果1:593;2:175;3:177 unsigned int a[7]; a[0]=1;a[1] = 2;a[2] = 3;a[3] = 4;a[4] = 2;a[5] = 3;a[6] = 4; unsigned int b[2][3][7]; auto endtime=clock(); auto begintime=clock(); int test_num = 20000000; begintime=clock(); for(int i=0;i<test_num;i++) copy(a+1, a+8, b[0][0]); endtime=clock(); cout<<"1: "<<(double)1000.0*(endtime-begintime)/CLOCKS_PER_SEC<<endl; // for (int i = 0; i < 7; i++) cout<<b[0][0][i]; cout<<endl; begintime=clock(); for(int i=0;i<test_num;i++) memcpy(b[0][0],a+1,7*sizeof(int)); endtime=clock(); cout<<"2: "<<(double)1000.0*(endtime-begintime)/CLOCKS_PER_SEC<<endl; // for (int i = 0; i < 7; i++) cout<<b[0][0][i]; cout<<endl; begintime=clock(); for(int i=0;i<test_num;i++) memmove(b[0][0],a+1,7*sizeof(int)); endtime=clock(); cout<<"3: "<<(double)1000.0*(endtime-begintime)/CLOCKS_PER_SEC<<endl; // for (int i = 0; i < 7; i++) cout<<b[0][0][i]; cout<<endl;
-
多线程
- 区域式多线程:最开始使用的是将结点分成4部分,每一部分用一个线程去处理。通过猜测线上数据的分布,调节不同线程的区域大小。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
double split[]={0,0.12,0.4,0.7,1}; void dfs_method(int tid){ for(unsigned int i=int(id_size*split[tid]);i<int(id_size*split[tid+1]);i++){ if(size1[i]){ dfs_cut_backward(i,i,0,tid); dfs(i,i,0,tid); } } } int main(){ ... thread Td[Tnum]; for(unsigned int i=0;i<Tnum;i++){ Td[i] = thread(dfs_method,i); } for(unsigned int i=0;i<Tnum;i++){ Td[i].join(); } ... }- 抢占式多线程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
pthread_mutex_t mt;//还可以选择不同的锁? unsigned int curhead=-1; void dfs_method(int tid){ while(1){ pthread_mutex_lock(&mt); int cur=++curhead; pthread_mutex_unlock(&mt); if(cur>=id_size)break; if(size1[cur]){ dfs_cut_backward(cur,cur,0,tid); dfs(cur,cur,0,tid); } } } int main(){ ... thread Td[Tnum]; for(unsigned int i=0;i<Tnum;i++){ Td[i] = thread(dfs_method,i); } for(unsigned int i=0;i<Tnum;i++){ Td[i].join(); } ... }
算法上的优化
-
算法选择
- 一开始尝试了使用Tarjan算法中的分离强连通图的方式,发现对于比赛数据集中的有向图来说,强连通图数量很少,且算法花费的时间代价较大,就弃用了。
- Johnson算法在有向图找环上比DFS要快,但是无法在搜索过程中将深度大于3小于7的提取出来,需要在最后的结果上再遍历一遍来过滤,最后的过滤时间代价较大,也弃用了。
- DFS有迭代版与递归版,迭代法的话队友有实现,但是栈频繁的push与pop,加上额外需要存判断当前深度的机制,就速度上比递归版的DFS要慢,最终就选择了递归版的DFS,在复赛时有将递归版DFS用7重循环的方式迭代展开,不同于我们所常见的用栈做的迭代DFS。
-
3入度结点剪枝
- 在建立正向邻接表时,同时也做了反向邻接表,即入结点指向出结点的形式建立成的邻接表,正向邻接表需要排序便于最后结果中不需要额外的排序,而反向邻接表不需要排序。
- 当起点为s时,通过反向邻接表遍历3层,将遍历到结点(假设集合为T)记录下来,则在正向遍历到第4层之后(即5,6,7层)的结点中,若非集合T中的结点,则必然不可能搜索到s形成环。
- 每遍历一层所花费的时间代价成指数增加,2的话剪枝结点较少,4的话剪枝结点多但额外消耗的时间较大,得不偿失;经测试,3层反向结点剪枝效果最好。
1 2 3 4 5 6 7 8 9 10 11 12 13
unsigned int three_border[Tnum][maxn]; void dfs_cut_backward(unsigned int head,unsigned int cur,int depth,int tid){ visited[tid][cur] = true; for(int i=0;i<size2[cur];i++){ unsigned int &v=Graph2[cur][i]; if(v>head && !visited[tid][v] && depth<3){ ... three_border[tid][v] = head+1; dfs_cut_backward(head,v,depth+1,tid); } } visited[tid][cur] = false; } -
6+1双向DFS
- 在做3入度结点剪枝时,可以随便把反向邻接表第一层的结点记录下来,这样就可以在正向访问到第7层结点时,直接用条件判断该结点的下一个结点是否为起点,就不需要再dfs第8层来判断该点是否为起点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
unsigned int lastone[Tnum][maxn]; void dfs_cut_backward(unsigned int head,unsigned int cur,int depth,int tid){ visited[tid][cur] = true; for(int i=0;i<size2[cur];i++){ unsigned int &v=Graph2[cur][i]; if(v>head && !visited[tid][v] && depth<3){ if(!depth){ lastone[tid][v]=head+1; } ... } } visited[tid][cur] = false; }
复赛
复赛题目:
- A榜(在初赛题目的基础上进行改动的)
- 输入数据由原来的最多28W变成最多200W,输出数据变大;
- 取消了平均转账小于10次的限制;
- 增加限制条件,转账金额浮动区间约束为[0.2, 3]::循环转账的前后路径的转账金额浮动,不能小于0.2,不能大于3。如账户A转给账户B 转X元,账户B转给账户C转Y元, 那么进行循环检测时,要满足0.2 <= Y/X <= 3的条件。
- B榜(在A榜题目的基础上进行改动的)
- 输出环的长度范围从3-7变成3-8;
- 转账金额由整型变成最多两位小数的浮点型;
复赛过程:
- test_main3.cpp
- 6+1 33s
- test_main4.cpp
- 在test_main3.cpp的基础上优化了dfs和dfs_cut_backward的部分if语句 28s
- test_main5.cpp
- 在test_main4.cpp的基础上将dfs_cut_backward从递归改成迭代 27s 取600时线上内存不够
- test_main6.cpp
- 在test_main5.cpp的基础上dfs_cut_backward改成5+2
- test_main7.cpp
- 在test_main5.cpp的基础上将Graph从array改成vector 线上15.5128 服务器31.5-33.5s
- test_main8.cpp
- 在test_main7.cpp的基础上进行平行改动,将基于出结点排序编号变成基于入结点
- test_main9.cpp
- 在test_main7.cpp的基础上对dfs_cut的三领域也进行了对menoy的判断 线上12.9 服务器25.8-27.8s
- test_main10.cpp
- 在test_main9.cpp的基础上将基于出结点排序编号变成基于入结点 线上13.1
- test_main11.cpp
- 在test_main10.cpp的基础上去掉dfs_cut的visit,对dfs2的if改成两个。线上12.8
- test_mian14.cpp
- 在test_main11.cpp的基础上把6+1换成5+2 9.78
- test_mian15.cpp
- 在test_main14.cpp的基础上加入前向第一个点优化 first_one 服务器25s
- test_mian16.cpp
- 在test_main15.cpp的基础上将dfs递归改成迭代 线上9.459 服务器22.7s
- test_mian17.cpp
- 在test_main16.cpp的基础上将优化了forward,把two_border_head从vector改成array 服务器21.5s 线上0% runtime error
- test_mian18.cpp
- 在test_main17.cpp的基础上换成dfs递归,加入4+3与5+2的结合 服务器25s(未完成)
- test_mian19.cpp
- 在test_main17.cpp的基础上,加入4+3与5+2的结合 服务器25s 线上11.38
- test_mian20.cpp
- 在test_main17.cpp的基础上将graph2从vector改成前向星 服务器25s
- test_main22.cpp(w18)
- 在test_main14.cpp(即递归版,无first_one的5+2)上graph和graph2改成前向星 22.6s
- test_main23.cpp
- 在test_main22.cpp的基础上改成将递归改成多函数 21.7s
- test_main15_2.cpp
- 在test_main23.cpp的基础上将前向星改回vector 23.6s
- test_main24.cpp
-
在test_main23.cpp的基础上将dfs里的<=&&换成< ,三个局部变量拆分 21.4s
-
- test_main25.cpp
- 在test_main24.cpp的基础上将Graph,Graph2,two_border改成用指针遍历 21.1s
- test_main26.cpp
- 在test_main25.cpp的基础上将three_border只存depth=3的点。20.9s
- test_main27.cpp
- 多函数版 在test_main26.cpp的基础上改成复赛B榜,环最大长度为8,输入为浮点型 0%result
- w22.cpp
- 迭代版 unsigned long long 48000000000 <=&& 非指针 改了input three_border存3 改了input 11.8606
- test_main29.cpp
- 在w22基础上three_border存1 11.84
复赛总结:
数据结构上的优化
-
\r\n问题
-
在一开始使用复赛样例数据集时就发现,数据集的换行符由原来初赛时的\n换成了\r\n,说明复赛数据集是win系统下生成的。然而很多前排大佬在复赛B榜当天没有发现到这个问题而导致无成绩,确实是可惜。
-
换行与回车的区别
:
- \n表示换行(ASCII码为10),\r表示回车(ASCII码为13)
- Unix系统里,每行结尾只有“<换行>”,即"\n";Windows系统里面,每行结尾是“<回车><换行>”,即“\r\n”;Mac系统里,每行结尾是“<回车>”,即"\r"。
- 在Windows中:’\r’ 回车,回到当前行的行首,而不会换到下一行,如果接着输出的话,本行以前的内容会被逐一覆盖;’\n’ 换行,换到当前位置的下一行,而不会回到行首;
- nix/Mac系统下的文件在Windows里打开的话,所有文字会变成一行;而Windows里的文件在Unix/Mac下打开的话,在每行的结尾可能会多出一个^M符号。
-
-
递归改迭代
- 由于使用在递归时DFS()函数调用大约11亿次,而函数的形参有6个,会有相当一部分时间花费在传参上,故将递归改成迭代可节约到这部分时间。同时还可以减少递归中对一些同名的局部变量的申请,以及对当前结点深度的判断等。
- 基于栈的迭代:由于还是需要额外的空间和时间判断当前结点深度,与递归法相比,并没有明显优势,反而栈的数据结构使用频繁,比递归法还慢了。
- 7重for循环:对于递归法要快一点点,但是每一层都需要不同的遍历名,修改起来比较繁琐,比较容易乱,扩展性不强。
- 多函数法:每一层都实现一个函数,对第i层就使用dfs_i(),这样可以保持原有的一些变量名,修改起来相对于7重for循环法没有那么繁琐,实际上效果差不多。
- 由于使用在递归时DFS()函数调用大约11亿次,而函数的形参有6个,会有相当一部分时间花费在传参上,故将递归改成迭代可节约到这部分时间。同时还可以减少递归中对一些同名的局部变量的申请,以及对当前结点深度的判断等。
-
long long代替double
- 在复赛B榜时由原来32为无符号整型的基础上增加至少两位小数,输入的金额可能无小数位,或1到2为小数,故需要根据小数的位数来分情况乘以100再转成long long类型。(一开始就是不分情况,所有数都是整数位*100再加上小数,导致100.2会转成10002而不是10020)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43
inline void get_input(string &input_file){ ll len = 0; char *buf = mmapread(input_file,len); int in_num=0,out_num=0;//,menoy_xioahsu=0; ll menoy=0; for(char *p = buf; *p && p-buf<len; p++) { int dian_cnt=0,dian_flag=0; while(*p && (*p == '\n'||*p=='\r')) p++; while(*p && *p != ',') in_num = in_num*10 + (*(p++) - '0'); p++; while(*p && *p != ',') out_num = out_num*10 + (*(p++) - '0'); p++; while(*p && *p != '\n'&&*p!='\r'){ if(*p=='.'){ dian_flag=1; p++; } if(dian_flag){ menoy = menoy*10 + (*(p++) - '0'); dian_cnt++; } else{ menoy = menoy*10 + (*(p++) - '0'); } } switch(dian_cnt){ case 0: menoy*=100;break; case 1: menoy*=10;break; } inputs_in_num.emplace_back(in_num); inputs_out_num.emplace_back(out_num); inputs_menoy.emplace_back(menoy); in_num = 0; out_num = 0; menoy = 0; }- 不使用double
- 浮点型的精度问题:由于double为64bit,但是整数位只有16位,小数位为48位,很可能存不下原题意中32位的整数。另外,浮点型会存在存储精度误差,导致在计算金额的[0.2,3]区间时出现误判。
算法上的优化
-
DFS 6+1改5+2、4+3
- 5+2:使用反向邻接表可以提前遍历以s为起点的两层结点(即若形成环,则就是环的最后两个结点),与初赛时不同,初赛时只要存储反向邻接表中s的下两个结点,而复赛中还需要存头尾的边权,用来最后在结点形成环时还要判断边权是否也符合条件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
void dfs_cut_backward(unsigned int &head,unsigned int tid){ ... //depth = 0 -> head unsigned int len1 = Graph2[head].size(); for(int i=0;i<len1;i++){ unsigned int v1=Graph2[head][i].first; if(v1<=head)continue; unsigned int v1_money=Graph2[head][i].second; ... //depth = 1 -> v1 unsigned int len2 = Graph2[v1].size(); for(int j=0;j<len2;j++){ unsigned int v2=Graph2[v1][j].first; if(v2<=head)continue; unsigned int v2_money=Graph2[v1][j].second; ... two_border[tid][v2].push_back(node{v1_money,v2_money,v1}); ... } }-
4+3
:
- 这个在比赛的时候并没有使用,因为反向邻接表遍历得到的长度为3的环时,是没有经过排序处理,需要在最后补充一步对深度3的环进行排序,虽然可以在正向邻接表搜索时减少一层,但当时测试得到的结果是比5+2要慢。
- 后来在看别的大佬的比赛总结时,发现反向邻接表遍历后,就使用插入排序进行一次排序(大部分有序的情况,比快搜要好),再去正向邻接表的dfs搜索。
-
前向一层剪枝
- 在使用反向邻接表进行剪枝时,获取到反向第一层的menoy值时,可与正向邻接表第一层的menoy进行是否处于[0.2,3]区间的判断,可以剪去一些不符合的结点。
- 但是每反向第一层的点都需要遍历一遍正向一层所有的点,时间代价的消耗与正向第一层剪去结点数的时间收益往往很依赖于数据集。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
void dfs_cut_backward(unsigned int &head,unsigned int tid){ ... //depth = 0 -> head unsigned int len1 = Graph2[head].size(); for(int i=0;i<len1;i++){ unsigned int v1=Graph2[head][i].first; if(v1<=head)continue; unsigned int v1_money=Graph2[head][i].second; ... long long r1 = v1_money * 3ll; //forward_cut for(int fi=0;fi<flen1;fi++){ if(v0[fi][0]<= head || v0[fi][2] < v1_money || v0[fi][1] > r1) continue; first_one[tid][v0[fi][0]] = head; } ... } }
决赛
决赛题目:
概述
通过金融风控的资金流水分析,可有效识别每个账号的位置关键中心性,辅助公安挖掘洗钱组织,帮助银行预防信用卡诈骗。基于给定的资金流水,精确计算每个账号的位置关键中心性,并输出TOP 100的账户信息。结果准确,用时最短者胜。
输入
- 本端账号ID和对端账号ID为一个32位的无符号整数
- 转账金额为一个32位的无符号整数
- 转账记录最多为250万条
- 账号A给账号B最多转账一次
输出
- TOP 100 位置关键中心性的账号以及其位置关键中心性值
- 位置关键中心性的定义:
1
2
3
4
5
6
7
8
C_B(v_i) = \sum_{v_s=\not v_i=\not v_t \subset V} \frac { \sigma_{st} (v_i)}{\sigma_{st}}
C_B(v_i):为账号i的位置关键中心性
\sigma_{st}:账号s到账号t的最短加权有向图路径的条数
\sigma_{st} (v_i):账号s到账号t的最短加权有向图路径里通过账号i的条数
算法理论部分:
最短路径算法
解决最短路径问题的算法主要有三种:
- 迪杰斯特拉算法(Dijkstra算法)
- 弗洛伊德算法(Floyd算法)
- SPFA算法
Dijkstra算法
Dijkstra算法采用的是一种贪心的策略,用了广度优先搜索解决赋权有向图或者无向图的单源最短路径问题,算法最终得到一个最短路径树。
- 声明一个数组dis来保存源点到各个顶点的最短距离和一个保存已经找到了最短路径的顶点的集合:T。初始时,源点 s 的路径权重被赋为 0 (dis[s] = 0)。而其他所有顶点的路径权值被赋为最大值(dis[x]=INF,x为除了s之外的顶点)。
- 声明一个优先队列q用于保存中间点以及其dis值。起始时,q中只有一个node(s,dis[s])
- 算法核心:循环主体while(!q.empty()),从q中选择最小值node(u,dis[u]),则该值就是源点s到该值对应的顶点的最短路径。如果u的下一个结点v,若dis[u]+w(u,v)<dis[v],则更新dis[v],并把v存入q中。重复循环中的动作。
位置关键中心性算法
- brandes算法是解决网络介数中心性(betweenness)的一种经典算法,是在2001年brandes提出的算法”A faster algorithm for betweenness centrality”,在无权图上复杂度为O(mn),在有权图上复杂度在O(mn+nlogn),在网络稀疏的时候,复杂度接近O(n2).
- 核心公式:
1
2
\delta_{s.}(v) = \sum \frac{\sigma_{sv}}{\sigma_{sw}}(1+\delta_{s.}(w))
- 计算δs⋅(v)需要先计算δs⋅(w),而v是w的先驱,顺序恰好跟BFS相反,因此用个栈就可以了。
数据结构上的优化点:
-
vector初始化: 在对于vector[Tnum][maxn]初始化时,对于maxn为250W和5000W时,初始化时间从0.010615变成0.942100,相差了近100倍,vector的初始化速度也相当慢。
-
数组代替vector
由于vector的初始化、读写、遍历等都比数组要慢得多,测试了juesai1数据集单单优先队列的访问都要33亿次,对Graph的访问会更多。故为了将Graph从vector换成数组,使用了菊花图和非菊花图的存储方法。
- 需要建立一个数组out_du_num[maxn]来记录每个结点的出度数。
- 非菊花图G存储方法是对于:u_1->v1_1,v1_2,v1_3,v1_4,则使用一维数组G来储存时G[u_1* MAX_OUT_DU到u_1*MAX_OUT_DU+50]存v1_1,v1_2,v1_3,v1_4,0,0,0,0,0…
- 菊花图denseG存储方法是对于结点的出度数较多(出度数>MAX_OUT_DU)的情况下,需要另外建立一个数组tmp[maxn]来记录结点对应在denseG中的起始位置。对于u_1->v1_1,v1_2,v1_3,v1_4在denseG[tmp[u_1]…tmp[u_1]+out_du_num[u] = v1_1,v1_2,v1_3,相对于非菊花图来说,是紧凑的。
-
位运算:
- 将 MAX_OUT_DU设置为32或64等2的幂次方,在遍历时对于*MAX_OUT_DU的运行换成左移5或6位,位运算相比于运算符运算速度上会快一些,但实际测试中无明显效果。
1 2 3
#define T 32 //finish[ G[ i * T].v]++; finish[ G[ i << 5].v]++;
-
变量初始化与置位:
-
对于变量初始化大小,如sum[Tnum][maxn],其中maxn为题目中最大转账记录。为减少无用空间的申请,可根据全局变量max_id获取到后再申请sum的大小:
1 2 3 4 5
pair<double,unsigned int>* sum[Tnum]; for(int i=0;i<Tnum;i++){ sum[i] = (pair<double,unsigned int>*)calloc(max_id,sizeof(pair<double,unsigned int>)); //或者sum[i] = (pair<double,unsigned int>*)malloc(max_id*sizeof(pair<double,unsigned int>)); } -
对于为多线程之间不用锁而多设置一维的全局变量,如dis[Tnum][max_id],转化成Dji函数内的局部变量,可减少一维的访问时间。
1 2 3 4
long long *dis = (long long*)calloc(max_id,sizeof(long long)); double *delta = (double*)calloc(max_id,sizeof(double)); double *sigma = (double*)calloc(max_id,sizeof(double)); unsigned int *Stk = (unsigned int*)calloc(max_id,sizeof(unsigned int));
-
对于上述的局部变量,使用struct将其封装,可以通过访问结构体对象,再使用指针指向变量的形式,提高对多个局部变量多次访问时的效率,提高内核命中率,但实际测试中并没有提速效果,可能是中间需要另外申请临时变量来存结构体对象。
1 2 3 4 5 6 7 8
struct Dji_Block{ long long *dis; double *delta; double *sigma; priority_queue<node>q; } Dji_Block *dji_block = new Dji_Block[max_id]; -
对于一些变量的初始化,使用全局变量的默认值为0,同样定义指针,再在函数内calloc申请内存,得到的默认也是0.
-
对于一些变量的置位,如dis[max_id]=INF,sigma[max_id]=0,使用menset函数进行置位,相比于遍历赋值更快
1 2 3 4 5 6 7 8 9
for(unsigned int i=0;i<max_id;i++){ dis[i] = INF; delta[i] = 0; } len_double=max_id*sizeof(double); len_l=max_id*sizeof(long long); memset(dis,0x3f,len_l); memset(delta,0,len_double);
-
-
多线程
搜索上的剪枝优化
-
0入度1出度的结点:
-
统计了juesai1数据集,发现79万个结点,有75万入度为0,其中71万结点0入度1出度。
-
在位置关键中心性的计算中,若s1,s2,s3…sn这n个结点入度为0出度为1,且都指向唯一结点u,所以在计算以u为起点的位置关键中心性值后,u的位置关键中心性值(n-1),其他值n即可省去计算s1…sn这n个结点为起点的搜索。
1 2 3 4 5 6 7 8 9
//one_prv指的就是这个倍数n,默认值为1 while(sizeStk){ unsigned int w=Stk[--sizeStk]; double coeff2=(1.0+delta[w])/sigma[w]; for(unsigned int v:prv[w]){ delta[v] += sigma[v]*coeff2; } sum_[w].first += delta[w] * one_prv; }
-
-
1出度的结点:
-
若结点u的出度数为1,结点v为u的唯一指向的结点,则在使用DIJ算法计算其u,v为起点的sigma值是相同的,所以使用brandes算法的位置关键中心性计算公式计算delta时,则可以共同使用一套sigma值。所以只需要以v为起点计算一次sigma值即可(不能使用以u为起点,存在u-v-…-u这种环的情况导致sigma[u]不正确)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
//以v为起点执行时获取sigma //s = u,one_prv = v while(!Stk[tid].empty()){ unsigned int w=Stk[tid].top(); Stk[tid].pop(); //one_prv默认值为max_id,不等于max_id说明存在1出度的结点 if(one_prv!=max_id){ //更新以v为起点的delta和sum double coeff=(1.0+delta[tid][w])/sigma[tid][w]; for(unsigned int v:prv[tid][w]){ delta[tid][v] += sigma[tid][v]*coeff; } if(w!=one_prv){ sum[tid][w].first += delta[tid][w]; } } //更新以u为起点的delta和sum(需要另外申请delta2) if(w==s) continue; double coeff2=(1.0+delta2[tid][w])/sigma[tid][w]; for(unsigned int v:prv[tid][w]){ delta2[tid][v] += sigma[tid][v]*coeff2; } sum[tid][w].first += delta2[tid][w]; } -
但是可能由于在juesai1中,1出度结点的情况只有1万种情况,且使用时只能两个结点合并,而不能与其他可合并结点再合并,故实际上可能只有六千左右,在使用时额外花费的delta2访问与置位,符合条件判断的代价更大一些,测试得到的结果是还慢了1分钟。
1 2 3 4 5 6 7 8 9 10 11 12
for(unsigned int i = 0; i < max_id; i++){ if(finish[i]==max_id&&out_du_num[i]==1){ unsigned int tmp_ = G[tmp_out_du[i]].v; if(finish[tmp_]==max_id){ finish[i] = tmp_; finish[tmp_] = tmp_; // cnt[0]++; // cout<<i<<" "<<tmp_<<endl; } } }
-
-
0出度的结点:
-
对于0出度的结点,其位置关键中心性必然为0,因此也可以省去这些结点为起点的运算。
1 2 3 4 5
for(unsigned int i = 0; i < max_id; i++){ if(out_du_num[i]==0){ finish[i] = i; } }
-