
(2018.01-简书)让你“又爱又恨”的推荐系统–程序猿篇
**深度学习的推荐系统**申请学员(以下简称学员)填写报名申请表并附上简历,电话或远程面试通过后,才视为报名成功,然后学员和七月在线(以下简称机构)双方签订培训合同。
课程开始前,提供预习视频预习,课程开始后,每周安排直播、录播、实训、答疑,然后每两周考试一次,顺利通过阶段考试的学员,才能进入下一阶段的学习。未能通过考核的重新学习,做查漏补缺。
在线视频:推荐业务、feed流产品及推荐算法策略架构解析
* 1-推荐业务和推荐feed流产品详解
* 2-推荐策略架构分解
* 3-基于point wise 的stacking model 如何做用于推荐业务,以及相应的效果评估和模型如何升级(针对相应算法,提供data和code)在线视频:召回算法和业界最佳实践
* 1-BAT里常用的CF算法以及变种(User/Item CF等变种)
* 2-Hybrid CF 算法
* 3-Model Based CF(LFM矩阵分解、NMF、SVD)
* 4-基于改进版协同过滤算法实战在线视频:搜索和推荐的matching技术
* 1-NLP的基础知识,BOW, TF-IDF, BM25
* 2-word2vec, topic model
* 3-向量召回,embedding基础在线实训:改进版协同过滤算法实战
在线视频:Deep recall算法解析、主流技术方向思考及相应model的改进方案
* 1-推荐系统的主流技术深度方向讨论及相关算法思考
* 2-如何通过deep learning model抽取推荐系统中的high-order feature
* 3-recall算法簇review,Deep recall模型解析和优化(针对相应算法,提供data和code)在线实训:隐语义模型实战
在线视频:用户建模(召回、排序都会用到)
* 1-BAT公司里常见的用户建模
* 2-特征工程、分类模型开发在线实训:倒排索引项目实战
在线直播:召回算法进阶实战
* 1-多路召回策略实战(热门、兴趣标签、内容属性、协同过滤、业务规则等)
* 2-Youtube召回实战在线直播:用户特征和Item特征的常用方法
* 1-Embedding的数学本质和计算方法
* 2-用户特征和人群画像
* 3-手动和自动特征工程在线视频:排序算法&深度学习模型
* 1-BAT里基础建模流程构造(涉及样本、特征、模型、系统设计和实践)
* 2-深度召回模型最新进展(向量检索、深度学习等)
* 3-深度排序最新进展(WDL、DeepFM、DeepCross等)
* 4-用户序列建模(LSTM、GRU, word2vec等)在线视频:Learn to Rank
* 1-Pointwise/Pairwise/Listwise排序(全局排序)
* 2-多目标优化(ESMM等)
* 3-多样性排序(BAT真实场景用户体验优化)在线实训:谷歌wide&deep模型实战
在线视频:商品推荐方案讨论、E&&E算法以及deep learning如何作用于推荐系统中的排序
* 1-电商推荐系统的难点
* 2-业界推荐系统的公开数据集和开源经典算法以及用于解决coldstart和exploit-explore问题的bandit算法簇
* 3-deep learning模型算法作用于排序及相应优化方案(针对相应算法,提供data和code)在线视频:CTR预估和采样
* 1-CTR概率矫正技术
* 2-多目标和ESMM
* 3-多种多样的采样算法在线直播:CTR预估进阶实战(上)
* 1-GBDT+LR 代码实战
* 2-wide&deep 代码实战在线直播:CTR预估进阶实战(下)
* 1-DeepFm 代码实战
* 2-DIN 代码实战在线视频:分布式机器学习系统及其在排序模型中的应用
* 1-分布式机器学习系统综述
* 2-Parameter Server介绍
* 3-基于Paramer Server的大规模离线LR/FM实现介绍在线视频: 实时化技术升级
* 1-Online Learning 算法(FTRL、增量学习等)
* 2-Online Learning 在BAT的系统架构在线实训 :Online Learning 最新算法实现
在线视频:在线学习和相关技术
* 1-L1, L2和FTRL优化算法
* 2-流式计算和流式数据
* 3-在线模型和实时特征在线直播:基于flink和scala的实时计算
* 1-flink相关知识点介绍
* 2-scala的相关知识,flink scala API初步上手
* 3-flink JOIN,MAP,TIMEWINDOW等算子的使用,checkpoints等高级特性的简介
* 4-实时数据进入tensorflow,tensorflow实时reader在线直播:单机和分布式深度学习tensorflow实践
* 1-掌握tensorflow单机和分布式操作
* 2-熟悉tensorflow serving
* 3-掌握对于数据进行分析和模型进行评估在线视频:学术界最新算法在BAT的应用
* 1-电商推荐中的Delayed reward强化学习算法
* 2-GAN等技术在推荐系统的实践在线视频:掌握真实业务场景下的推荐算法
* 1-社交推荐算法
* 2-短视频推荐算法
* 3-音乐推荐
* 4-新闻推荐
* 5-电商推荐在线直播:多目标排序
* 1-推荐系统中的CTR、CVR任务如何共同建模
* 2-多目标排序的问题点
* 3-如何通过算法将推荐系统中的用户显式反馈行为和隐式反馈行为(浏览、点击、购买和评论)进行表征同时作用于个性化推荐(针对相应算法,提供data和code)在线直播:推荐系统最新技术、场景、方向解析
* 1-推荐新场景
* 2-推荐系统可解释性
* 3-推荐系统多样性
* 4-推荐系统公平性
* 5-冷启动问题的最新解法在课程进行的后半段,学员根据自己的兴趣和求职的方向选择实战项目:
在线直播:项目1 单机和分布式深度学习TensorFlow实践的介绍
在线直播:项目2 基于Flink和Scala的实时计算实践的介绍
在线直播:项目3 电商平台的商品推荐系统的介绍
在线直播:项目1 单机和分布式深度学习TensorFlow实践的特征工程
在线直播:项目2 基于Flink和Scala的实时计算实践的特征工程
在线直播:项目3 电商平台的商品推荐系统的特征工程
在线直播:项目1 单机和分布式深度学习TensorFlow实践的模型构建
在线直播:项目2 基于Flink和Scala的实时计算实践的模型构建
在线直播:项目3 电商平台的商品推荐系统的模型构建
在线直播:项目1 单机和分布式深度学习TensorFlow实践的整体实现
在线直播:项目2 基于Flink和Scala的实时计算实践的整体实现
在线直播:项目3 电商平台的商品推荐系统的整体实现
在线直播:项目4 游戏推荐系统的整体流程和核心技能点
在线直播:项目5 猜你喜欢场景下的推荐系统整体流程和核心技能点
在线直播:项目6 Netflix推荐竞赛整体流程和核心技能点
深度学习由于在图像和语音等连续信号上取得了不可置否的成绩,但CV、NLP就业现状却不容乐观。首先,其在工业界落地困难,除了一些成熟的方向(如人脸识别)外找到一个可以推广应用的技术有一定难度,而且变现能力不够。其次,其不可解释性能加增加了其在一些敏感领域的应用难度。
因此如果想要提升自己的竞争力,也给自己多一些选择,回退学习机器学习及其典型应用——推荐、广告系统等势在必行。加强实践能力,参加些比赛提升理解及应用落地能力。
发挥自身优势,将深度学习应用到推荐系统,广告系统,风控系统或者搜索引擎等。
如今,我们这代人正经历从信息时代(Information Technology,IT)到数据时代(Data Technology,DT)的变迁,DT时代比较明显的标志就是:信息过载。
在DT时代,充斥着海量的信息,如何从海量的信息中快捷的帮助特定用户找到感兴趣的信息呢?有两种相关的解决技术:搜索引擎与推荐系统。
搜索引擎与推荐系统有什么区别?
搜索引擎:实现人找信息,eg.百度搜索…
推荐系统:实现信息找人,eg.亚马逊的图书推荐列表…
与搜索引擎不同,推荐系统不需要用户准确地描述出自己的需求,而是根据分析历史行为建模,主动提供满足用户兴趣和需求的信息。

简单来说,对于消费者而言,他们喜欢用2个小时去看一部感兴趣的电影,却不愿意花20分钟去挑选,这就是个性化推荐系统存在的意义。
推荐系统通过分析、挖掘用户行为,发现用户的个性化需求与兴趣特点,将用户可能感兴趣的信息或商品推荐给用户。一个优秀的推荐系统,能够很好的串联起用户、商家以及平台方,并让三方都收益。
本质上来讲,推荐系统就是对所有商品针对特定用户进行按照一定策略进行排序,然后筛选出若干商品推荐给用户的过程。
协同过滤推荐(Collaborative Filtering Recommendation):该方法收集分析用户历史行为、活动、偏好,计算一个用户与其他用户的相似度,利用目标用户的相似用户对商品评价的加权评价值,来预测目标用户对特定商品的喜好程度。优点是可以给用户推荐未浏览过的新产品;缺点是对于没有任何行为的新用户存在冷启动的问题,同时也存在用户与商品之间的交互数据不够多造成的稀疏问题,会导致模型难以找到相近用户。
基于内容过滤推荐[**1](Content-based Filtering Recommendation):该方法利用商品的内容描述,抽象出有意义的特征,通过计算用户的兴趣和商品描述之间的相似度,来给用户做推荐。优点是简单直接,不需要依据其他用户对商品的评价,而是通过商品属性进行商品相似度度量,从而推荐给用户所感兴趣商品的相似商品;缺点是对于没有任何行为的新用户同样存在冷启动**的问题。
组合推荐[2](Hybrid Recommendation):运用不同的输入和技术共同进行推荐,以弥补各自推荐技术的缺点。
基于协同过滤推荐算法的思想是:通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的项。在计算推荐结果的过程中,不依赖于项的任何附加信息或者用户的任何附加信息,只与用户对项的评分有关。
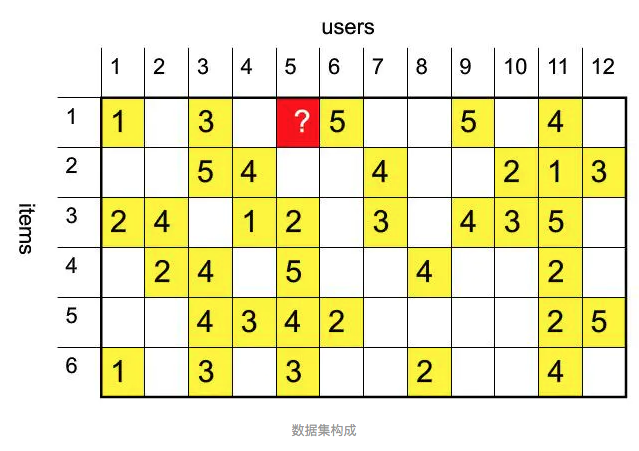
基于用户的:User-based Collaborative Filtering,为用户推荐和他兴趣相似的用户喜欢的商品。 基于项(商品)的:tem-based Collaborative Filtering,为用户推荐与他之前喜欢的商品相似度高的商品.
这个算法的核心,就是如何衡量用户与用户之间的相似度或者商品与商品之间的相似度。
相似性的度量方法有很多种,比如:欧式距离、皮尔森相关系数、余弦相似度等。
UserCF: 看重用户相似的小群体的热点,偏重社会化,一般适用于新闻推荐
缺点
改进:UserCF-IIF:(类似于TF-IDF的作用):实际业务中用户数量太多,很难对推荐结果做出解释。
ItemCF: 以物找物。
看重个性化,反应用户个人兴趣的传承性,此外商品的更新不能太快,因为实时计算物品相似度矩阵非常耗时,这也是为啥新闻一般不用ItemCF。 ItemCF在实际业务中用的比较多,可以基于用户的历史购买商品行为对推荐结果做出可理解的解释。
同时,从技术上考虑,UserCF需要维护一个用户相似度的矩阵,而ItemCF需要维护一个物品 相似度矩阵。从存储的角度说,如果用户很多,那么维护用户兴趣相似度矩阵需要很大的空间, 同理,如果物品很多,那么维护物品相似度矩阵代价较大。

企业级的数据一般都是G量级起步的数据量,很难使用我们参加一些小型竞赛的数据处理方式,python的Pandas等库一般使用很难操作这些业务数据,所以很多推荐系统都是搭建在集群之上的,数据存储可能是基于Hadoop的HDFS等,计算框架一般是Spark或者企业自研的数据平台(阿里的PAI平台…主要任务就是写SQL…羡慕吧)。所以,入职的第一步就是学习hadoop平台与spark的使用
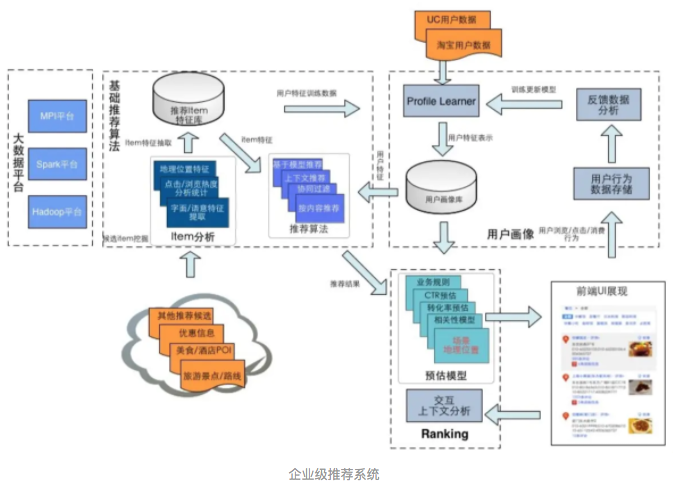
参加过一些数据竞赛的推荐系统,一般平台会给出一个评价函数,可能是准确率、召回率等常见评价函数的调和函数。但在实际的业务场景中,却很难给出一个准确的评价函数来评价我们推荐系统的效果。这其中就涉及到推荐系统中多样性与精确性的两难困境
推荐用户喜欢商品最保险的方式就是很流行或者分数很高的商品。但是这种推荐产生的用户体验不一定好:因为既然用户已知其热销,故信息量少且让用户不觉得是个性化推荐
Mcnee等人已经警告大家,盲目崇拜精确性指标可能会伤害推荐系统,因为这样可能会导致用户得到一些信息量为0的“精准推荐”并且视野变得越来越狭窄。让用户视野变得狭窄是协同过滤算法的一个主要缺陷,这会进一步加剧长尾效应。与此同时,应用个性化推荐技术的商家,也希望推荐中有更多的品类出现,从而激发用户新的购物需求。
遗憾的是,推荐多样性与推荐的精确性之间存在矛盾,因为前者风险很大—推荐一个没人看过或者打分较低的东西,很可能被用户憎恶,从而效果更差。很多时候,这是一个两难的问题,只能通过牺牲多样性来提高精确性,或者牺牲精确性来提高多样性。一种可行之策是直接对推荐列表进行处理,从而提升其多样性。这种方法固然在应用上是有效的,但没有任何理论的基础和优美性可言,只能算一种实用的招数。
其实,上面所讲协同过滤的方法是一种比较传统的方式,仍旧在工业界具有广泛的应用。如今,伴随着机器学习的兴起了非常多的技术被应用到推荐系统中**,从传统的机器学习方式LR、GBDT、XGBoost到LightGBM,深度学习从最初利用word2vec用于评估用户的相似度,到CNN、RNN等模型也开始被很多的推荐小组尝试。**
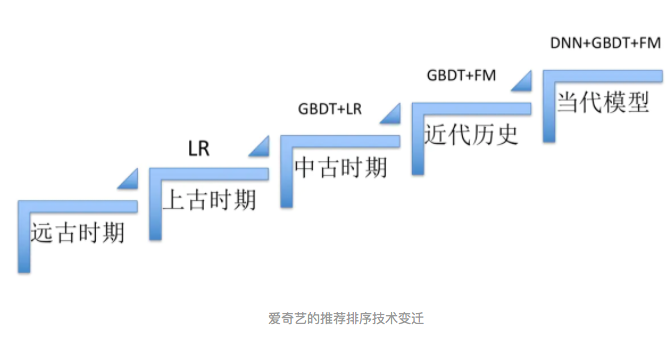
深度学习具有优秀的自动提取特征的能力,能够学习多层次的抽象特征表示,并对异质或跨域的内容信息进行学习,可以一定程度上处理推荐系统冷启动问题。
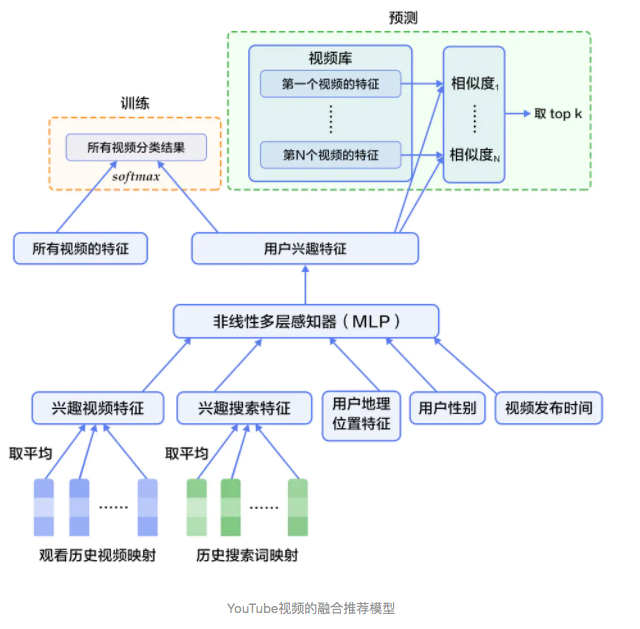
在融合推荐模型的电影推荐系统中:
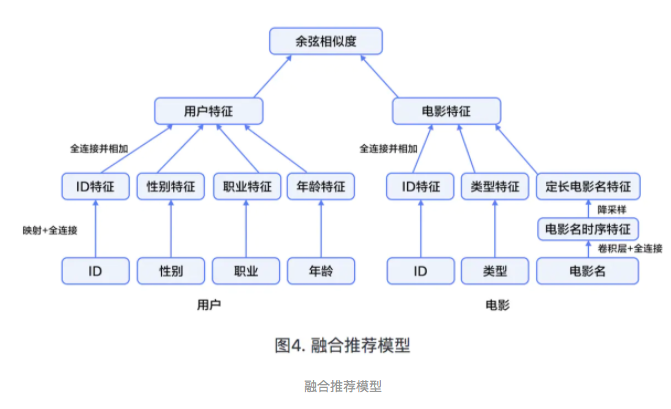
身处工业界,最基础的就是使用协同过滤配合其它的一些排序方法,例如GBDT,基本就能完成推荐的基本功能,基于深度学习的方式现在应用的还没有那么成熟,希望自己今后也能有业务需要我深入的研究一下如何在实际的业务场景中大规模的使用深度学习的推荐系统
首先计算用户-用户之间的相似度 w 找出该用户u没买过的商品I`候选推荐数据集 遍历所有用户[所有买过I商品的用户U]:求和{ 用户U与用户u的相似度 * 用户U对商品I的评分 } <利用所有买过候选集商品的**用户评分*用户与该用户的相似度**–>得出j候选集的得分>
计算商品-商品之间的相似度 找出该用户u没买过的商品I`>候选推荐数据集 遍历所有商品J[该用户u买过的商品J]`>求和{ 商品I与商品J的相似度 * 用户u对商品J的评分 } <只利用u自己的购买过的商品,然后根据**商品之间的相似度*自己对该商品的评分**—得到该候选商品的得分>
# coding:utf-8
import numpy as np
from math import *
"""
相似度计算函数
"""
# 第一种计算相似度:余弦相似度, 计算两者之间相似度【计算相似度的方法有很多,这里使用余弦相似度】
def cos_sim(x, y):
"""
:param x(mat): 行向量,可以是用户或商品
:param y(mat): 行向量,可以是用户或商品
:return: x 和 y 之间的余弦相似度
"""
# x 与 y 之间的内积
inner_product = x * y.T
norm = np.sqrt(x * x.T) * np.sqrt(y * y.T)
# 余弦相似度的结果
return (inner_product / norm)[0, 0]
def similarity(data):
"""
:param data: 矩阵
:return: w(mat): 任意两行之间的相似度,相似度矩阵w是一个对称矩阵。在相似度矩阵中约定自身相似度为0。
[[0. 0.76912242 0.39678004 0.49377072 0.02503131],
[0.76912242 0. 0.84770118 0.5696552 0.44279924],
[0.39678004 0.84770118 0. 0.45714286 0.46348977],
[0.49377072 0.5696552 0.45714286 0. 0.64888568],
[0.02503131 0.44279924 0.46348977 0.64888568 0. ]]
"""
# 用户/商品【行数决定方阵的维度】
m =np.shape(data)[0]
# 初始化相似度矩阵
w =np.mat(np.zeros((m, m)))
for i in range(m):
for j in range(i, m):
if j != i:
# 计算两行之间的相似度[用户-用户 或者 商品-商品]
w[i, j] = cos_sim(data[i], data[j]) # 使用余弦距离
w[j, i] = w[i, j]
else:
w[i, j] = 0
return w
# 第二种计算相似度:对数似然函数
def obtainK(a,b):
k11=0
k12=0
k21=0
k22=0
for i in range(len(a)):
if a[i]`b[i]!=0:
k11 +=1
if a[i]`b[i]`0:
k22 +=1
if a[i]!=0 and b[i]`0:
k12 +=1
if a[i]`0 and b[i]!=0:
k21 +=1
return k11,k12,k21,k22
def Entropy(*x):
sum=0.0
for i in x:
sum +=i
result=0.0
for j in x:
if j<0:
pass
pinghua=1 if j`0 else 0
result += j*log((j+pinghua)/sum)
return result
def loglikelihood(N,a,b):
k11,k12,k21,k22 = obtainK(a, b)
rowEntropy=Entropy(k11,k12)+Entropy(k21,k22)
colEntropy= Entropy(k11,k21)+Entropy(k12,k22)
matEntropy=Entropy(k11,k12,k21,k22)
sim=-2*(matEntropy-colEntropy-rowEntropy)
return sim
"""
基于用户的协同过滤算法
"""
def user_based_recommend(data, w, user):
"""
:param data(mat): 用户商品矩阵
:param w(mat): 用户相似度矩阵
:param user(int): 用户编号
:return: predict(list): 推荐列表
"""
m, n = np.shape(data) # m是用户,n是商品数
user_product = data[user, ] # 用 user=0 这一行:商品信息
print("用user的买过商品信息:",user_product,m,n) # user0的商品信息: [[4 3 0 5 0]],这说明只有商品3,商品5他没买过
"""找到用户user没有打分的商品,这是候选的推荐项"""
not_score = []
for i in range(n):
if user_product[0, i] ` 0:
not_score.append(i)
"""对没有打分的商品进行预测"""
predict = {}
for x in not_score:
item = data[:, x] # 所有用户对该商品的打分信息 x=0: item = [[0], [0], [0], [3], [4]]
for i in range(m): # 遍历每一个用户对该商品的评分【这里包含了被推荐人,因为他的权重是0,所以不影响最终的加权权重】
if item[i, 0] != 0:
if x not in predict:
""" 用户i与该用户相似度*用户i对该商品的评分 """
predict[x] = w[user, i] * item[i, 0]
else:
predict[x] = predict[x] + w[user, i] * item[i, 0]
"""按照预测值大小排序"""
return sorted(list(predict.items()), key=lambda p: p[1], reverse=True)
"""
基于用户的协同过滤算法
"""
def item_based_recommend(data, w, user):
"""
:param data(mat): 用户商品矩阵
:param w(mat): 用户相似度矩阵
:param user(int): 用户编号
:return: predict(list): 推荐列表
"""
m, n = np.shape(data) # m为商品数量, n为用户数量
user_product = data[:, user].T # 用user的商品信息
not_score = [] # 找到用户user没有打分的商品 [在他未购买的里面选出推荐项]
"""变量该用户对应的商品,找到没有评分的"""
for i in range(m):
if user_product[0, i] ` 0:
not_score.append(i)
"""对没有打分的商品进行预测"""
predict = {}
for x in not_score:
# 该user对该商品的打分信息
item = user_product
# 遍历所有g商品
for i in range(m):
# 该用户买过这个商品
if item[0, i] != 0:
if x not in predict:
"""推荐权值 = 该商品与这个商品之间相似度*该用户过的商品的评分"""
predict[x] = w[x, i] * item[0, i]
else:
predict[x] = predict[x] + w[x, i] * item[0, i]
# 按照预测值大小排序
return sorted(list(predict.items()), key=lambda p: p[1], reverse=True)
# 1、定义:我们获取并处理后的数据的格式
# 一行,表示某用户对各商品的评分
# 一列,代表不同用户对同一个商品的打分情况,若给用户没有评价过该商品,则表示这个是未购买过
'''
商品1,商品2,商品3,商品4,商品5
用户A [4, 3, 0, 5, 0],
用户B [5, 0, 4, 4, 0],
[4, 0, 5, 0, 3],
[2, 3, 0, 1, 0],
[0,4, 2, 0, 5]
'''
"""
一、UserCF 基于用户的协同过滤算法:
首先计算用户-用户之间的相似度 w
找出该用户u没买过的商品I`候选推荐数据集
遍历所有用户[所有买过I商品的用户U]:求和{ 用户U与用户u的相似度 * 用户U对商品I的评分 }
<利用所有买过候选集商品的用户评分*用户与该用户的相似度-->得出j候选集的得分>
"""
User1 = np.mat([ # 用户-商品-评分矩阵
[4, 0, 0, 5,1,0,0],
[5, 0, 4, 4,2,1,3],
[4, 0, 5, 0,2,0,2],
[2, 3, 0, 1,3,1,1],
[0, 4, 2, 0,1,1,4],
])
w = similarity(np.mat(User1)) # 用户之间相似性矩阵:计算任意用户之间的余弦距离
print("用户之间相似度:\n",w)
predict = user_based_recommend(User1, w, 0) # 给U0用户推荐商品(计算出未评分商品的顺序):
print(predict)
"""
二、ItemCF
基于项的协同过滤算法:是通过基于项的相似性来进行计算的
计算商品-商品之间的相似度
找出该用户u没买过的商品I`候选推荐数据集
遍历所有商品J[该用户u买过的商品J]`>求和{ 商品I与商品J的相似度 * 用户u对商品J的评分 }
<只利用u自己的购买过的商品,然后根据商品之间的相似度*自己对该商品的评分---得到该候选商品的得分>
"""
data = User1.T # 首先将用户-商品矩阵,转置成 商品-用户矩阵
print("ItemCF:商品-用户-评分:\n",data)
w = similarity(data) # 然后计算 商品之间相似性矩阵
print("商品之间相似度:\n",w)
predict = item_based_recommend(data, w, 0) # 给U0用户推荐商品:
print(predict)