有了这些选择,我们可以假设,不失去普遍性, that . We also follow [8] and choose
We discretize the equations of motion with the trapezoidal rule(梯形法则), and a uniform mesh with nhintervals. Data for this problem appears in Table 10.1.
戈达德火箭问题数据
Variables
Constraints
Bounds
Linear equality constraints
0
Linear inequality constraints
0
Nonlinear equality constraints
Nonlinear inequality constraints
0
Nonzeros in
0
Nonzeros in
Performance
Results for the AMPL implementation are shown in Table 10.2. For starting points we use $ t_f = 1 $and the functions $ h = 1 $,
evaluated at the grid points. The initial value for the thrust(推力) is $ T = T_{}/2 $.
For the rocket problem with nh = 200, 400, MINOS makes no progress, declaring it to be an unbounded (or badly scaled) problem.
Solver
LANCELOT
violation
iterations
LOQO
3.34 s
3.38 s
4.65 s
12.42 s
1.01281e+00
1.01283e+00
1.01283e+00
1.01283e+00
violation
2.1e-10
4.5e-10
8.2e-10
7.5e-10
iterations
123
64
43
48
MINOS
1.69 s
4.48 s
1.12 s
3.93 s
1.01280e+00
1.01278e+00
9.85326e+03
6.11246e+03
violation
4.8e-13
6.1e-16
3.6e+03
1.1e+03
iterations
11
11
2
2
SNOPT
3.04 s
9.5 s
31.5 s
64.48 s
1.01281e+00
1.01280e+00
1.01281e+00
1.01238e+00
violation
1.9e-09
4.1e-08
3.5e-09
5.2e-07
iterations
37
29
43
39
Errors or warnings. Timed out.
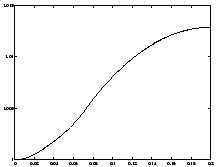
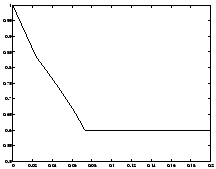
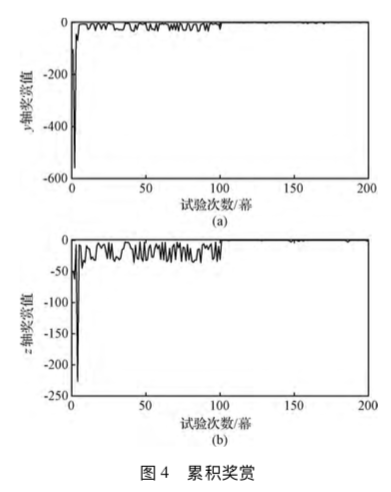
Figure 10.1 shows the altitude and mass of the rocket as a function of time. Note that altitude increases until a maximum altitude of $ h = 1.01 $ is reached, while the mass of the rocket steadily decreases until the final mass of $ m(t_f) = 0.6 isreachedat. t = 0.073 $
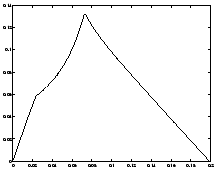
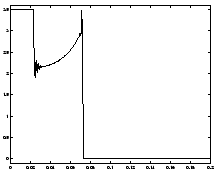
Figure 10.2 shows the velocity and thrust as a function of time. The thrust is bang-singular-bang, with the region of singularity occurring when
This figure shows that the optimal flight path involves using maximal thrust until , and no thrust for , at which point the final mass is reached, and the rocket coasts to its maximal altitude. The oscillations that appear at the point of discontinuity in the thrust parameter can be removed by using more grid points.

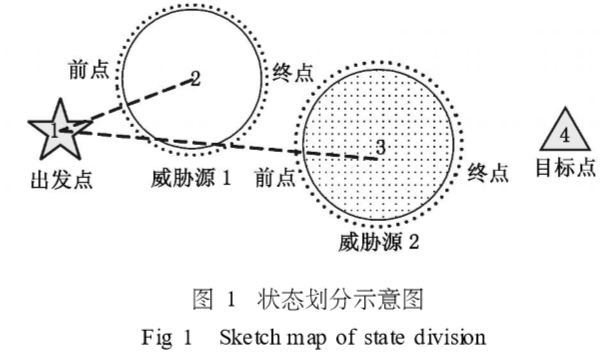
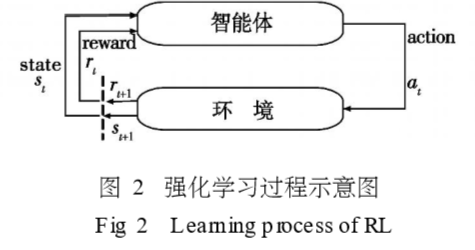
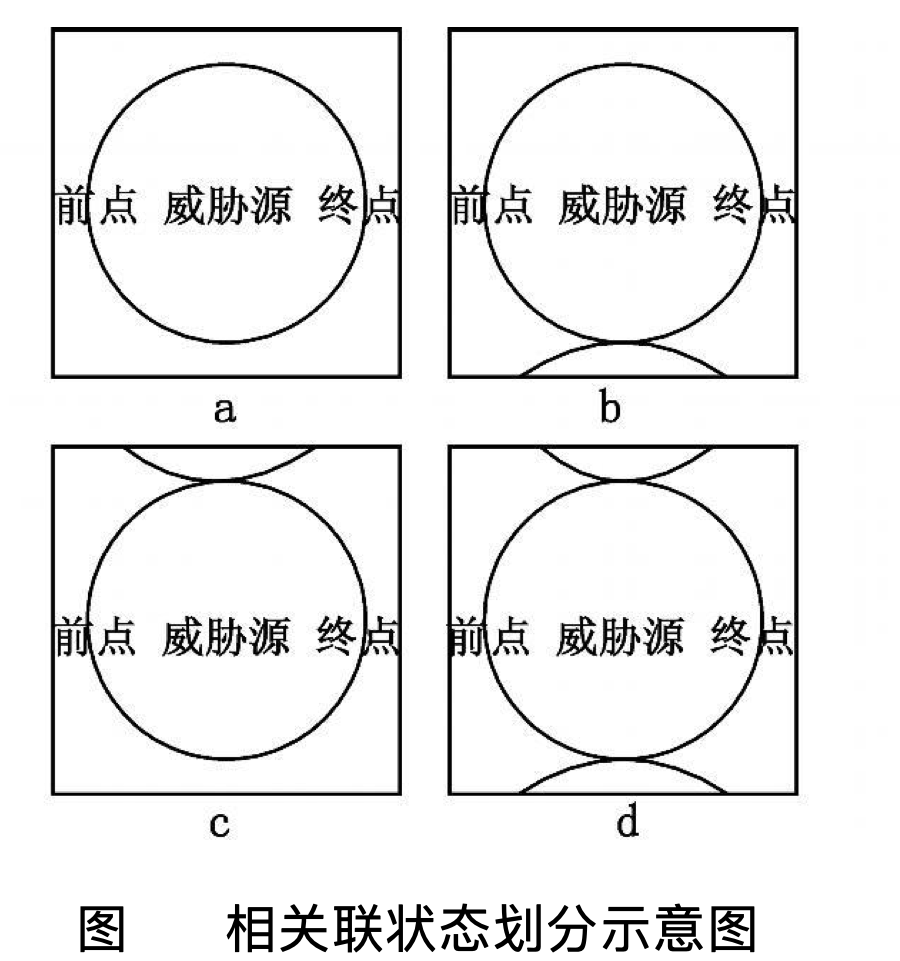

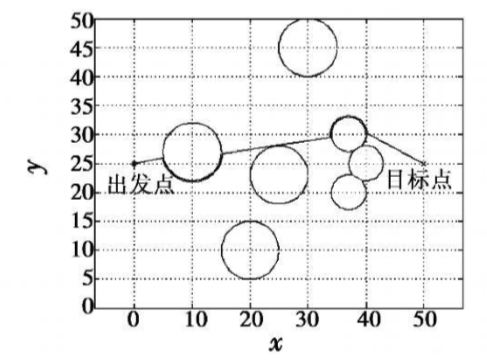
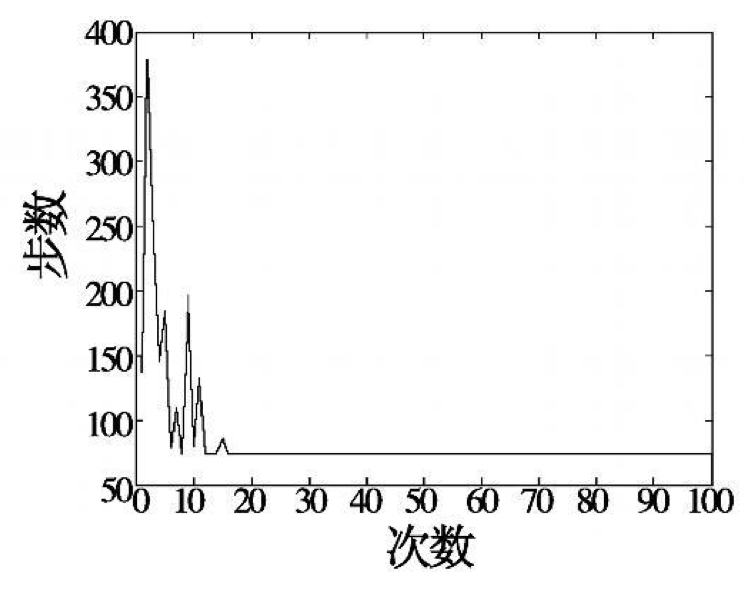
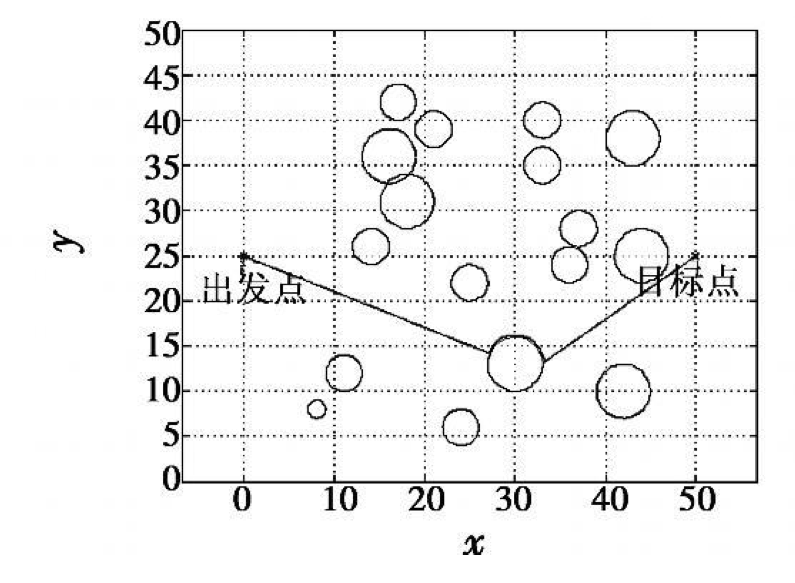
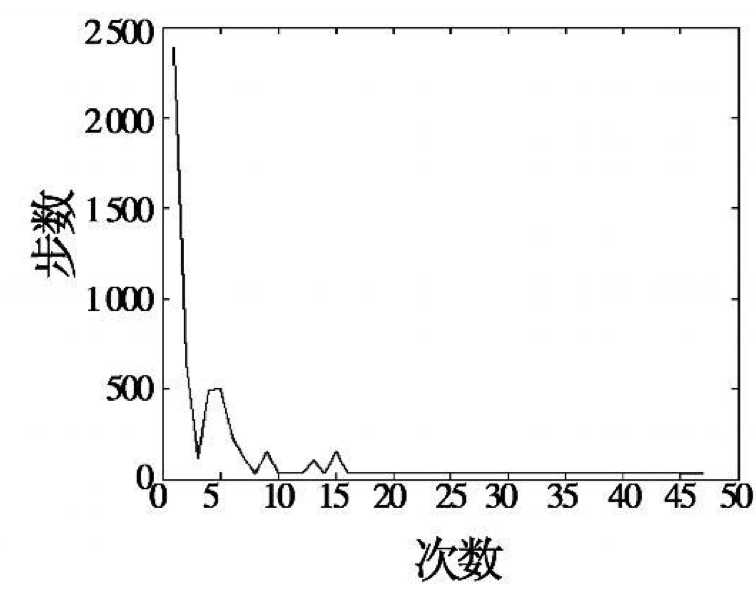


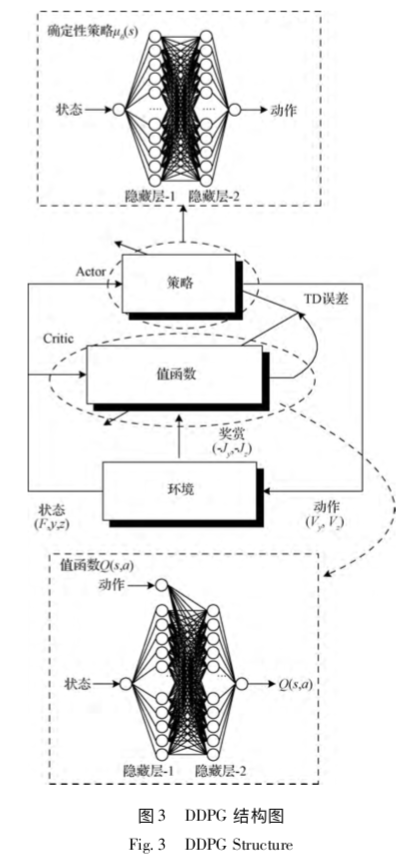
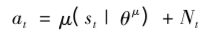
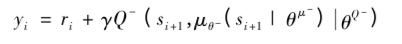 13)更新Critic的网络参数使得
13)更新Critic的网络参数使得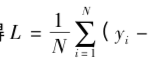
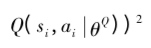 最小
最小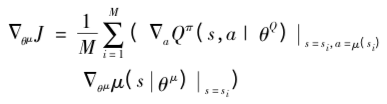
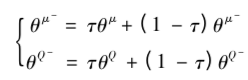

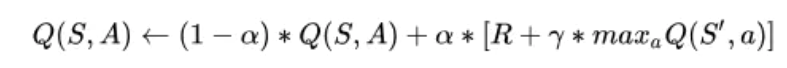
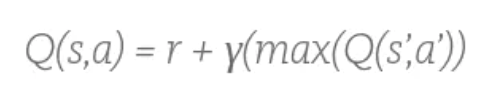


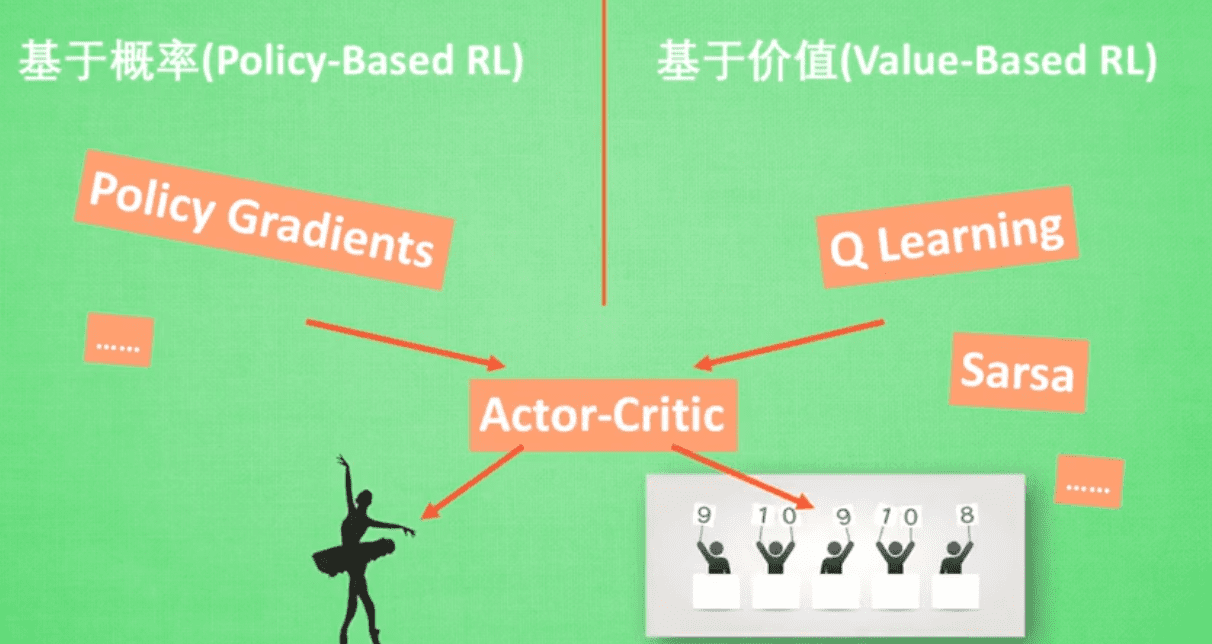
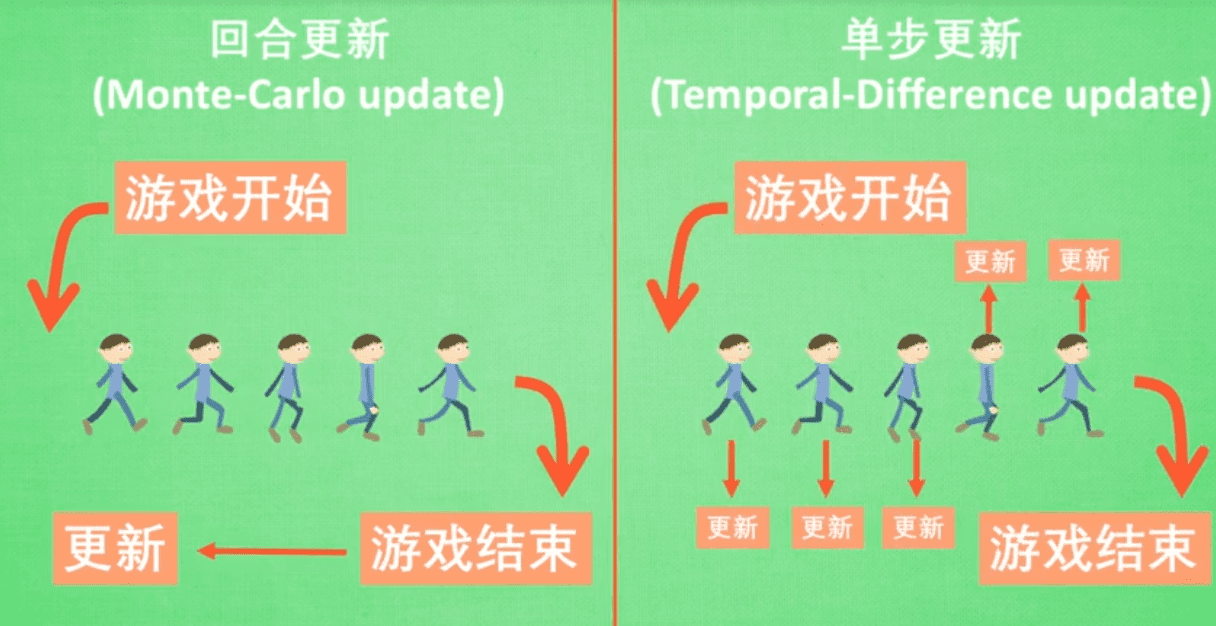



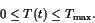
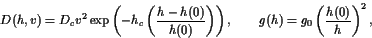
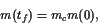
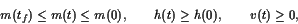
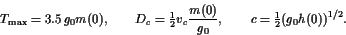
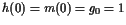 . We also follow [8] and choose
. We also follow [8] and choose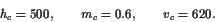
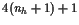
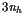
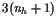
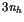
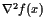
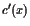
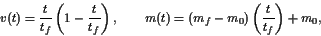
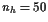
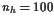
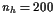
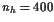
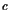 violation
violation
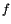
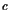 violation
violation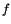
 violation
violation
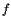
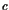 violation
violation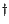 Errors or warnings.
Errors or warnings. 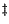 Timed out.
Timed out.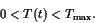
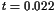 , and no thrust for
, and no thrust for 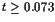 , at which point the final mass is reached, and the rocket coasts to its maximal altitude. The oscillations that appear at the point of discontinuity in the thrust parameter can be removed by using more grid points.
, at which point the final mass is reached, and the rocket coasts to its maximal altitude. The oscillations that appear at the point of discontinuity in the thrust parameter can be removed by using more grid points.