
$ g++ -vg++ helloworld.cpp运行
$ ./a.outgcc
gcc main.cpp -lstdc++ -o maing++
g++ helloworld.cpp -o helloworld有四个必须部分:
大多数情况main()的返回值作为状态指示器: 其中返回0表示执行完毕, 返回非0值则有错误出现
IO库
iostream库处理格式化输入输出的库
类型: istream, ostream: 输入流, 输出流
4个io对象:
int main() {
// 前缀 std:: 表明 cout 和 endl 是定义在命名空间 std 中的。
// 操作数必须是 ostream 对象;右操作数是要输出的值。操作符将其右操作数写到作为其左操作数的 ostream 对象
std::cout << "Enter Your Number To Sum" << std::endl; //std 是包含了cin, cout 成员的类 std::endl 是换行
int x,y;
// 输入操作符返回其左操作数作为结果。
std::cin >> x >> y;
std::cout << "The Result is " << x+y << std::endl;
return 0;
}whileforif标准库的头文件用尖括号 < > 括起来,非标准库的头文件用双引号 " " 括起来。
一般而言,对象就是内存中具有类型的区域。说得更具体一些,计算左值表达式就会产生对象
| 类型 | 关键字 |
|---|---|
| 布尔型 | bool |
| 字符型 | char |
| 整形 | int |
| 浮点型 | float |
| 双浮点型 | double |
| 无类型 | void |
| 宽字符型 | wchar_t |
一些基本类型可以使用一个或多个类型修饰符进行修饰:
| 类型 | 位 | 范围 |
|---|---|---|
| char | 1 个字节 | -128 到 127 或者 0 到 255 |
| unsigned char | 1 个字节 | 0 到 255 |
| signed char | 1 个字节 | -128 到 127 |
| int | 4 个字节 | -2147483648 到 2147483647 |
| unsigned int | 4 个字节 | 0 到 4294967295 |
| signed int | 4 个字节 | -2147483648 到 2147483647 |
| short int | 2 个字节 | -32768 到 32767 |
| unsigned short int | 2 个字节 | 0 到 65,535 |
| signed short int | 2 个字节 | -32768 到 32767 |
| long int | 8 个字节 | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 |
| signed long int | 8 个字节 | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 |
| unsigned long int | 8 个字节 | 0 到 18,446,744,073,709,551,615 |
| float | 4 个字节 | 精度型占4个字节(32位)内存空间,+/- 3.4e +/- 38 (~7 个数字) |
| double | 8 个字节 | 双精度型占8 个字节(64位)内存空间,+/- 1.7e +/- 308 (~15 个数字) |
| long double | 16 个字节 | 长双精度型 16 个字节(128位)内存空间,可提供18-19位有效数字。 |
| wchar_t | 2 或 4 个字节 | 1 个宽字符 |
作用域是程序的一个区域,一般来说有三个地方可以定义变量:
C++ 中的标识符都是大小写敏感的。
| 类型 | 描述 |
|---|---|
| bool | 存储值 true 或 false。 |
| char | 通常是一个字符(八位)。这是一个整数类型。 |
| int | 对机器而言,整数的最自然的大小。 |
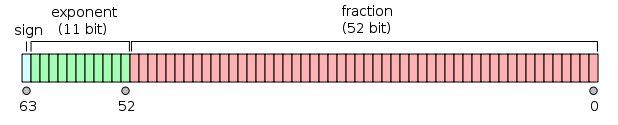
| float | 单精度浮点值。单精度是这样的格式,1位符号,8位指数,23位小数。 |
| double | 双精度浮点值。双精度是1位符号,11位指数,52位小数。 |
| void | 表示类型的缺失。 |
| wchar_t | 宽字符类型。 |
当局部变量被定义时,系统不会对其初始化,您必须自行对其初始化。定义全局变量时,系统会自动初始化为下列值:
| 数据类型 | 初始化默认值 |
|---|---|
| int | 0 |
| char | ‘\0’ |
| float | 0 |
| double | 0 |
| pointer | NULL |
30u // 无符号整数
30l // 长整数
30ul // 无符号长整数存储类定义 C++ 程序中变量/函数的范围(可见性)和生命周期。这些说明符放置在它们所修饰的类型之前。下面列出 C++ 程序中可用的存储类:
从 C++ 17 开始,auto 关键字不再是 C++ 存储类说明符,且 register 关键字被弃用。
自 C++ 11 以来,auto 关键字用于两种情况:声明变量时根据初始化表达式自动推断该变量的类型、声明函数时函数返回值的占位符。
C++98标准中auto关键字用于自动变量的声明,但由于使用极少且多余,在C++11中已删除这一用法。
根据初始化表达式自动推断被声明的变量的类型,如:
auto f=3.14; //double auto s(“hello”); //const char* auto z = new auto(9); // int* auto x1 = 5, x2 = 5.0, x3=‘r’;//错误,必须是初始化为同一类型

每个定义都是以类型说明符开始, 后面紧跟着以逗号分开的含有一个或多个说明符的列表。分号结束定义。
复制初始化复制初始化和直接初始化。

警告:未初始化的变量引起运行问题,建议每个内置类型的对象都要初始化。
为了让多个文件访问相同的变量,C++ 区分了声明和定义。
变量的定义用于为变量分配存储空间,还可以为变量指定初始值。在一个程序中,变量有且仅有一个定义。
声明用于向程序表明变量的类型和名字。定义也是声明:当定义变量时我们声明了它的类型和名字。可以通过使用 extern 关键字声明变量名而不定义它。
不定义变量的声明包括对象名、对象类型和对象类型前的关键字 extern:
extern int i; // declares but does not define i
int i; // declares and defines i
extern 声明不是定义,也不分配存储空间。事实上,它只是说明变量定义在程序的其他地方。程序中变量可以声明多次,但只能定义一次。
**如果声明有初始化式,那么它可被当作是定义**,即使声明标记为 extern:
extern double pi = 3.1416; // definition
魔数 (magic number): 会产生可读性和可维护性的问题
解决这两个问题的方法是使用一个初始化为 512 的对象:
int bufSize = 512; // input buffer size
for (int index = 0; index != bufSize; ++index) {
// ...
}提供了一个解决办法,它把一个对象转换成一个 不可修改的常量, const int bufSize = 512; // input buffer size
const默认为局部变量,非const变量默认为全局变量, 在做了合适的声明时其他文件也可用, 如下
// file_1.cc
int counter; // definition
// file_2.cc
extern int counter; // uses counter from file_1
++counter; // increments counter defined in file_1
通过指定 const 变更为 extern,就可以在整个程序中访问 const 对象:
extern const int bufSize = fcn();
// file_2.cc
extern const int bufSize; // uses bufSize from file_1引用就是对象的另一个名字。 在实际程序中, 引用主要用作函数的形式参数。
引用是一种复合类型,通过在变量名前添加“&”符号来定义。
复合类型是指用其他类型定义的类型。 在引用的情况下, 每一种引用类型都“关联到”某一其他类型。不能定义引用类型的引用,但可以定义任何其他类型的引用。
引用必须用与该引用同类型的对象初始化:
int ival = 1024;
int &refVal = ival; // ok: refVal refers to ival
int &refVal2; // error: a reference must be initialized int &refVal3 = 10; // error: initializer must be an object因为引用只是它绑定的对象的另一名字,作用在引用上的所有操作事实上都是作用在该引用绑定的对象上
可以在一个类型定义行中定义多个引用。必须在每个引用标识符前添加“&”符号:
const 引用是指向 const 对象的引用: 必须加上const
const int ival = 1024;
const int &refVal = ival; // ok: both reference and object are const
int &ref2 = ival; // error: non const reference to a const objecttypedef 可以用来定义类型的同义词:
typedef double wages; // wages is a synonym for double
枚举的定义包括关键字 enum,其后是一个可选的枚举类型名,和一个用花括号括起来、用逗号分开的枚举成员列表。
// input is 0, output is 1, and append is 2
enum open_modes {input, output, append};每个 enum 都定义一种唯一的类型
class Sales_item {
public:
// operations on Sales_item objects will go here
private:
std::string isbn;
unsigned units_sold;
double revenue;
}; // 注意有;
类体定义了组成该类型的数据和操作。这些操作和数据是类的一部分,也称为类的成员。操作称为成员函数(第 1.5.2 节),而数据则称为数据成员。
访问标号负责控制使用该类的代码是否可以使用给定的成员。类的成员函数可以使用类的任何成员,而不管其访问级别。访问标号 public、private 可以多次出现在类定义中。给定的访问标号应用到下一个访问标号出现时为止。
类中 public 部分定义的成员在程序的任何部分都可以访问。
不是类的组成部分的代码不能访问 private 成员。Sales_item 类型的对象可以执行那些操作,但是不能直接修改这些数据。
C++ 支持另一个关键字 struct,它也可以定义类类型。
可以等效地定义 Sales_item 类为:
struct Sales_item {
// no need for public label, members are public by default // operations on Sales_item objects
private:
std::string isbn;
unsigned units_sold;
double revenue;
};注意:
用 class 和 struct 关键字定义类的唯一差别在于默认访问级别:默认情况下,struct 的成员为 public,而 class 的成员为 private。我们已经从第 1.5 节了解到,一般类定义都会放入头文件。编写自己的头文件 我们已经从第 1.5 节了解到,一般类定义都会放入头文件。
$ CC -c main.cc Sales_item.cc -o main
当设计头文件时, 记住定义和声明的区别是很重要的。 定义只可以出现一次, 而声明则可以出现多次(第 2.3.5 节)。下列语句是一些定义,所以不应该放在头文件里:
extern int ival = 10; // initializer, so it's a definition double fica_rate; // no extern, so it's a definition对于头文件不应该含有定义这一规则,有三个例外。头文件可以定义类、值在编译时就已知道的 const 对象和 inline 函数(第 7.6 节介绍 inline 函数)。这些实体可在多个源文件中定义,只要每个源文件中的定义是相同的。
C++ 中的任何变量都只能定义一次(第 2.3.5 节)。定义会分配存储空间,而所有对该变量的使用都关联到同一存储空间。
如果 const 变量不是用常量表达式初始化,那么它就不应该在头文件中定义。相反,和其他的变量一样,该 const 变量应该在一个源文件中定义并初始化。应在头文件中为它添加 extern 声明,以使其能被多个文件共享。
#include 设施是 C++ 预处理器的一部分。预处理器处理程序的源代码,在编译器之前运行。
在编写头文件之前,我们需要引入一些额外的预处理器设施。预处理器允许我们自定义变量。 预处理器变量 的名字在程序中必须是唯一的。任何与预处理器变量相匹配的名字的使用都关联到该预处理器变量。
为了避免名字冲突,预处理器变量经常用全大写字母表示
可以使用这些设施来预防多次包含同一头文件:
#ifndef SALESITEM_H
#define SALESITEM_H
// Definition of Sales_itemclass and related functions goes here #endif使用自定义的头文件
#include 指示接受以下两种形式:
#include <standard_header>
#include "my_file.h" 如果头文件名括在尖括号(< >)里,那么认为该头文件是标准头文件。编译器将会在预定义的位置集查找该头文件, 这些预定义的位置可以通过设置查找路径环境变量或者通过命令行选项来修改。
如果头文件名括在一对引号里, 那么认为它是非系统头文件, 非系统头文件的查找通常开始于源文件所在的路径。
类型可以为 const 或非 const;const 对象必须要初始化,且其值不能被修改。
C++ 是一种静态类型语言:变量和函数在使用前必须先声明。变量可以声明多次但是只能定义一次。定义变量时就进行初始化几乎总是个好主意。
int main() {
// 前缀 std:: 表明 cout 和 endl 是定义在命名空间 std 中的。
std::cout << "Hello, World!" << std::endl; //std 是包含了cin, cout 成员的类 std::endl 是换行
f();
return 0;
// 好的呀
}两种最重要的标准库类型是 string 和 vector。
使用 using 声明可以在不需要加前缀 namespace_name:: 的情况下访问命名空间中的名字。using 声明的形式如下:
using std::cin;
using std::string;
int main()
{
string s; // ok: string is now a synonym for std::string
cin >> s; // ok: cin is now a synonym for std::cin一次只能声明一个命名空间成员:
#include <iostream> // using declarations for names from the standard library
using std::cin;
using std::cout;
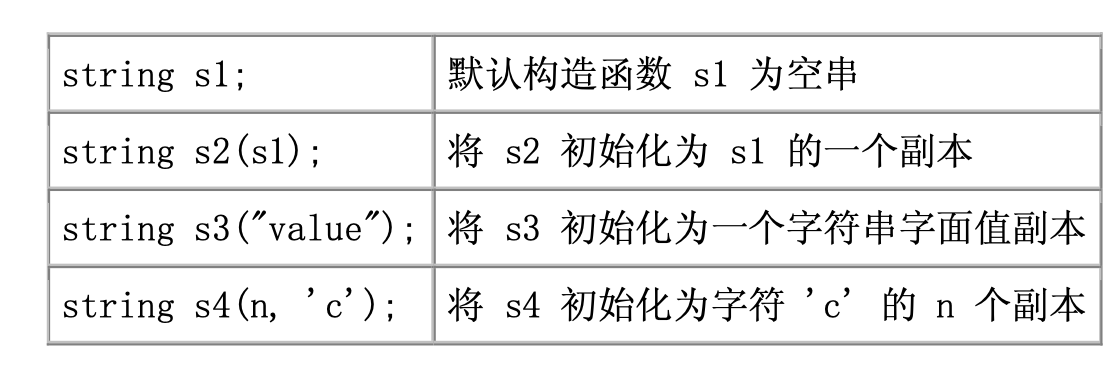
using std::endl;表 3.1. 几种初始化 string 对象的方式
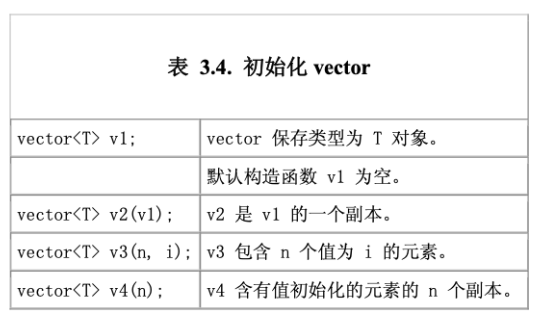
vector 是同一种类型的对象的集合,每个对象都有一个对应的整数索引值。 和 string 对象一样, 标准库将负责管理与存储元素相关的内存。 我们把 vector 称为容器, 是因为它可以包含其他对象。 一个容器中的所有对象都必须是同一种类型的。我们将在第九章更详细地介绍容器。
vector 是一个类模板(class template)。使用模板可以编写一个类定义或函数定义,而用于多个不同的数据类型。
在 C++ 中要声明一个数组,需要指定元素的类型和元素的数量,如下所示:
type arrayName [ arraySize ];这叫做一维数组。arraySize 必须是一个大于零的整数常量,type 可以是任意有效的 C++ 数据类型。例如,要声明一个类型为 double 的包含 10 个元素的数组 balance,声明语句如下:
double balance[10];初始化数组
在 C++ 中,您可以逐个初始化数组,也可以使用一个初始化语句,如下所示:
double balance[5] = {1000.0, 2.0, 3.4, 7.0, 50.0}; string str1 = "runoob";map()map<int, vector<int> > graph;
C++中map提供的是一种键值对容器,里面的数据都是成对出现的,如下图:
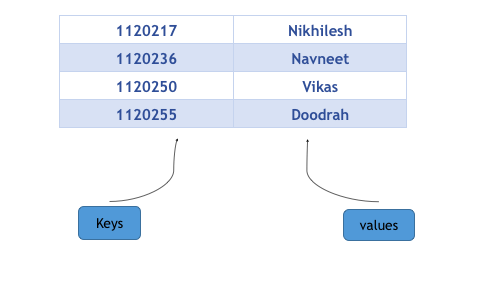
用find函数来定位数据出现位置,它返回的一个迭代器,当数据出现时,它返回数据所在位置的迭代器,如果map中没有要查找的数据,它返回的迭代器等于end函数返回的迭代器。
#include<iostream>
#include<map>
#include<string>
#include <vector>
#include <iterator>
//#include <algorithm>
using namespace std;
int main() {
map<int, vector<int> > t;
t[0] = {1};
t[1] = {18, 1};
map<int, vector<int>>::iterator iter;
int c = getchar(); // 显示暂停程序 注意
for (iter = t.begin(); iter != t.end(); iter++) {
// cout << iter->first << "->" << iter->second << endl;
cout << iter->first << "->" ;
copy (iter->second.begin(), iter->second.end(), ostream_iterator<int> (cout, ","));
cout << "\n";
}
return 0;
}vector<int> single_result;
向量是一个封装了动态大小数组的顺序容器, 与其他类型容器相同, 它可以存放各种类型的对象
简单认为, 向量是一个能够存放任意类型的动态数组
copy (res1.begin(), res1.end(), ostream_iterator<int> (cout, ",")); //打印向量vector<int> res1
cout << "\n";增加函数
void push_back(const T& x):向量尾部增加一个元素X
1.push_back 在数组的最后添加一个数据
2.pop_back 去掉数组的最后一个数据
3.at 得到编号位置的数据
4.begin 得到数组头的指针
5.end 得到数组的最后一个单元+1的指针
6.front 得到数组头的引用
7.back 得到数组的最后一个单元的引用
8.max_size 得到vector最大可以是多大
9.capacity 当前vector分配的大小
10.size 当前使用数据的大小
11.resize 改变当前使用数据的大小,如果它比当前使用的大,者填充默认值
12.reserve 改变当前vecotr所分配空间的大小
13.erase 删除指针指向的数据项
14.clear 清空当前的vector
15.rbegin 将vector反转后的开始指针返回(其实就是原来的end-1)
16.rend 将vector反转构的结束指针返回(其实就是原来的begin-1)
17.empty 判断vector是否为空
18.swap 与另一个vector交换数据
#include < vector>
using namespace std;当程序看不到输出直接返回code0时,在前面加上
// "entering any character to continue."
cout << "entering any character to continue." << endl;
int c = getchar(); // 显示暂停程序 注意auto tmp = inputs;
//以下2行: 删除重复项 -- ①sort()排序 ②unique()重复项移至末尾并返回地址 ③容器操作,删除元素
sort(tmp.begin(), tmp.end()); //对输入排序
tmp.erase(unique(tmp.begin(), tmp.end()), tmp.end()); //erase(): 容器操作, 删除元素 unique(): 去重函数, 将重复项移至最后, 并返回最后一个元素的地址unordered_map哈希表是根据关键码值(key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度,这个映射函数叫做散列函数。
哈希表的一个重要问题就是如何解决映射冲突的问题。常用的有两种:开放地址法 和 链地址法。
STL中,map 对应的数据结构是 红黑树。红黑树是一种近似于平衡的二叉查找树,里面的数据是有序的。在红黑树上做查找操作的时间复杂度为 O(logN)。而unordered_map 对应 哈希表,哈希表的特点就是查找效率高,时间复杂度为常数级别 O(1), 而额外空间复杂度则要高出许多。
所以对于需要高效率查询的情况,使用 unordered_map 容器。而如果对内存大小比较敏感或者数据存储要求有序的话,则可以用 map 容器。
C++ 提供了两种指针运算符
指针是一个包含了另一个变量地址的变量,您可以把一个包含了另一个变量地址的变量说成是“指向”另一个变量。变量可以是任意的数据类型,包括对象、结构或者指针。
& – 取地址运算符& 是一元运算符,返回操作数的内存地址。例如,如果 var 是一个整型变量,则 &var 是它的地址。
您可以把 & 运算符读作“取地址运算符”,这意味着,&var 读作“var 的地址”。
* – 取地址的内容 (间接寻址)第二个运算符是间接寻址运算符 ,它是 & 运算符的补充。 是一元运算符,返回操作数所指定地址的变量的值。
调用时变量前加 “&” ——-返回该变量的地址
**声明时变量前加 "基本类型 *" ——-该指针变量表示另一个普通变量的地址** eg:int * 或 char *
调用时变量前加 "*"——-表示取该地址的内容
声明时变量前加 "基本类型 **“——-该二级指针变量表示另一个一级”基本类型 *"指针变量地址
(int &x : path) // int &x -- path的变量地址