leetcode题目按类型
排序算法
总结
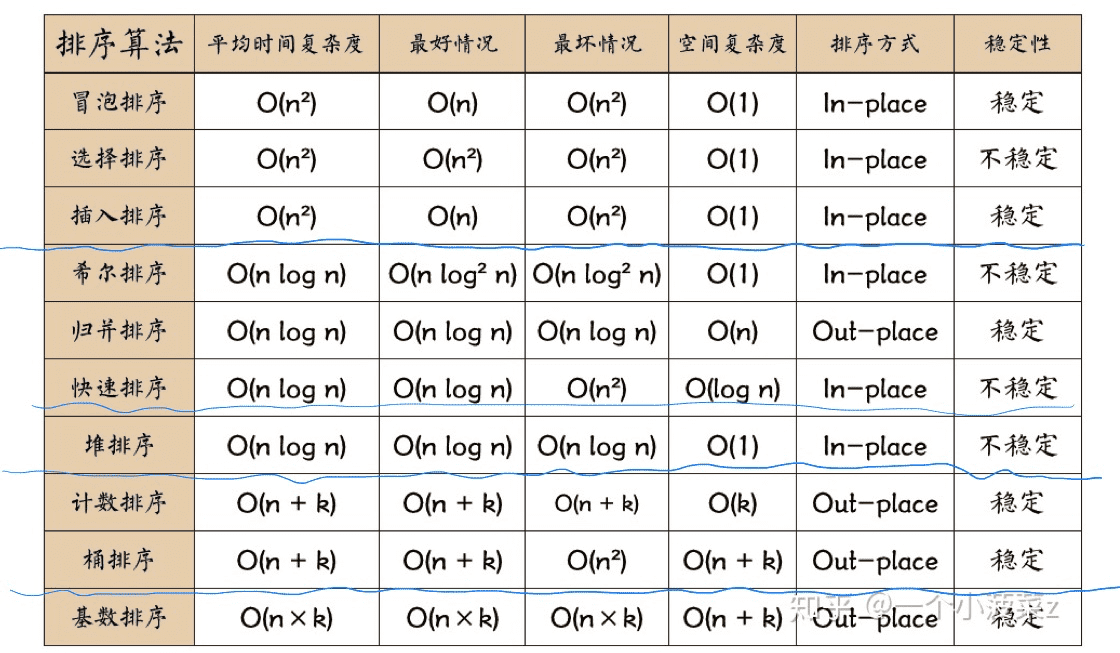
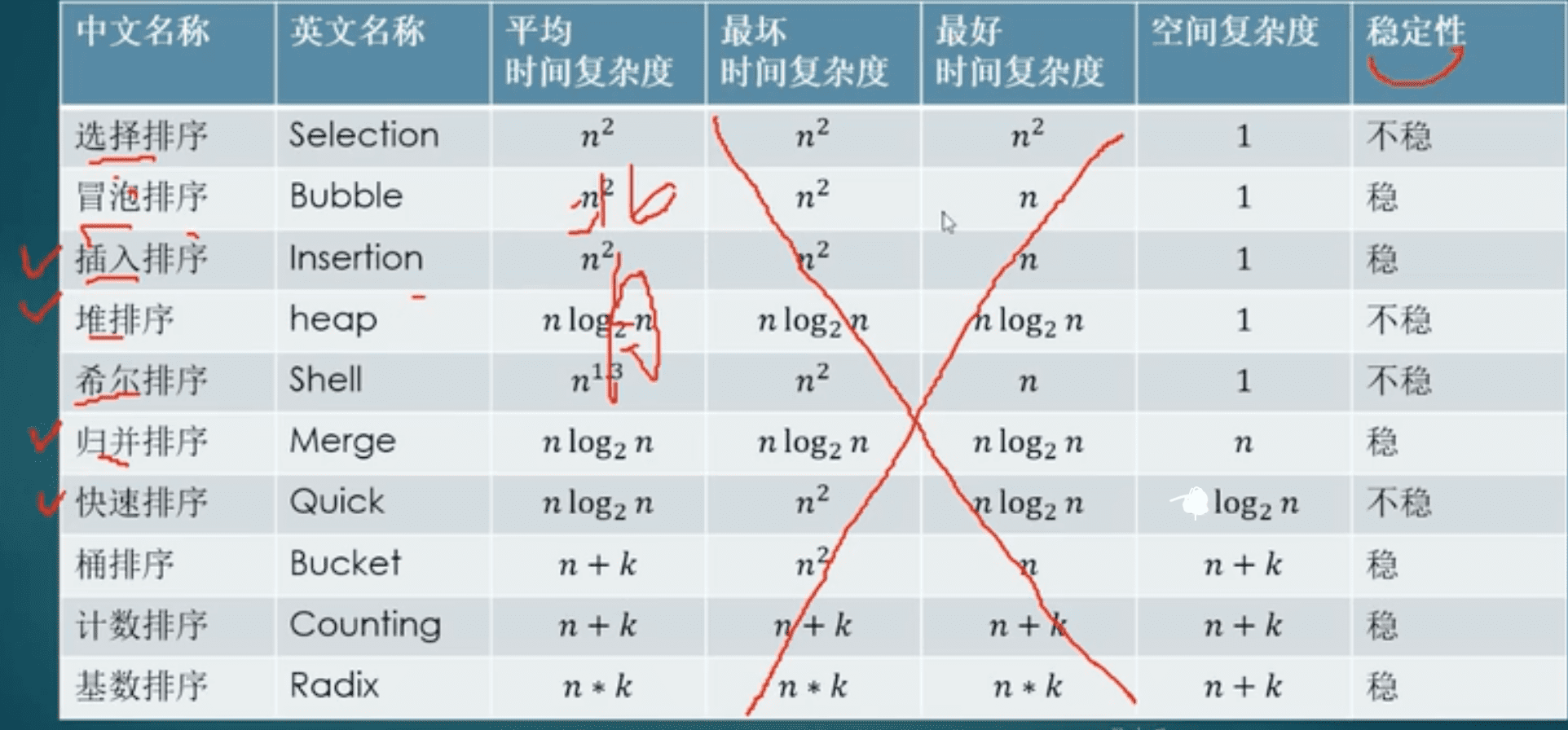
- 简单排序里,插入排序最好(样本小且基本有序时,效率较高)

🚩冒泡排序 — 逐个比较,最大的后移
1
2
3
4
5
6
def bubbleSort(nums):
for i in range(len(nums)):
# Last i elements are already in place
for j in range(len(nums)-i-1):
if nums[j] > nums[j+1]:
nums[j], nums[j+1] = nums[j+1], nums[j]
选择排序 — 遍历选择最小的,放到最前
🚩插入排序(熟悉) — 发现小数字,向前交换
简单排序里,插入排序最好(样本小且基本有序时,效率较高,效果好)
1
2
3
4
5
6
7
8
class Solution:
def sortArray(self, nums: List[int]) -> List[int]:
for ind in range(1,len(nums)):
i = ind
while i > 0 and nums[i] < nums[i-1]:
nums[i], nums[i-1] = nums[i-1], nums[i]
i -= 1
return nums
希尔排序 — 改进的插入排序,间隔由大到小排序
🚩 归并排序(掌握)
最坏情况效果最好
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class Solution:
def merge_sort(self, nums, l, r):
if l == r:
return
mid = (l + r) // 2
self.merge_sort(nums, l, mid)
self.merge_sort(nums, mid + 1, r)
tmp = []
i, j = l, mid + 1
while i <= mid or j <= r:
if i > mid or (j <= r and nums[j] < nums[i]):
tmp.append(nums[j])
j += 1
else:
tmp.append(nums[i])
i += 1
nums[l: r + 1] = tmp
def sortArray(self, nums: List[int]) -> List[int]:
self.merge_sort(nums, 0, len(nums) - 1)
return nums
🚩 快速排序 (掌握)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class Solution:
def sortArray(self, nums: List[int]) -> List[int]:
def partition(nums, left_bound, right_bound):
pivot = nums[right_bound]
l,r = left_bound, right_bound - 1
while l <= r:
while l <= r and nums[l] <= pivot:
l += 1
while l <= r and nums[r] > pivot:
r -= 1
if l < r:
nums[l], nums[r] = nums[r], nums[l]
# 注意要把轴放在中间, 因为最后一次循环一定是走的l++,即当前l和r指向的是大值,互换l和锚点
nums[l], nums[right_bound] = nums[right_bound], nums[l]
return l
def quick_sort(nums, left_bound, right_bound):
if left_bound>=right_bound:
return
mid = partition(nums, left_bound, right_bound)
quick_sort(nums, left_bound, mid - 1)
quick_sort(nums, mid + 1, right_bound) # 注意是mid+1
quick_sort(nums, 0, len(nums)-1)
return nums
快速排序是每个程序员都应当掌握的排序算法。当然我们接触的第一个排序算法可能是插入排序或者冒泡排序,但数据量一旦超过几万,插入和冒泡的性能会非常差。这时时间复杂度的渐进优势就表现出来了。 平均情况下快速排序的时间复杂度是Θ(𝑛lg𝑛),最坏情况是𝑛2,但通过随机算法可以避免最坏情况。由于递归调用,快排的空间复杂度是Θ(lg𝑛)。时间复杂度$O(nlogn)$,空间复杂度$O(logn)$。
步骤:
- 找基准
- 分区
- 递归
快速排序算法其实很简单,采用分治策略。步骤如下:
- 选取一个基准元素(pivot)
- 比pivot小的放到pivot左边,比pivot大的放到pivot右边
- 对pivot左边的序列和右边的序列分别递归的执行步骤1和步骤2
基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。 算法描述: 快速排序使用分治法来把一个串(list)分为两个子串(sub-lists)。具体算法描述如下:
- 从数列中挑出一个元素,称为 “基准”(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
快速排序时间复杂度:
平均情况下快速排序的时间复杂度是Θ(𝑛\lgn),最坏情况是Θ(𝑛2)。
当划分产生的两个子问题分别包含 n-1 和 0 个元素时,最坏情况发生。划分操作的时间复杂度为Θ(𝑛),𝑇(0)=Θ(1),这时算法运行时间的递归式为 𝑇(𝑛)=𝑇(𝑛−1)+𝑇(0)+Θ(𝑛)=𝑇(𝑛−1)+Θ(𝑛),解为𝑇(𝑛)=Θ(𝑛2)T(n)=Θ(n2)。
当划分产生的两个子问题分别包含⌊𝑛/2⌋和⌈𝑛/2⌉−1个元素时,最好情况发生。算法运行时间递归式为 𝑇(𝑛)=2𝑇(𝑛/2)+Θ(𝑛),解为𝑇(𝑛)=Θ(𝑛lg𝑛)。
事实上只要划分是常数比例的,算法的运行时间总是𝑂(𝑛lg𝑛)。 假设按照 9:1 划分,每层代价最多为 cn,递归深度为 log10/9𝑛=Θ(lg𝑛),故排序的总代价为𝑂(𝑛lg𝑛)。
快排的空间复杂度是Θ(lgn),因为快排的实现是递归调用的, 而且每次函数调用中只使用了常数的空间,因此空间复杂度等于递归深度Θ(lgn)。
随机算法
可以通过在算法中引入随机性,使得算法对所有输入都能获得较好的期望性能。比如我们随机地选择pivot,这样上述的最坏情况就很难发生。 伪码描述是这样的:
1
2
3
4
5
//新的划分程序,只是在真正进行划分前进行一次交换
RANDOMIZED-PARTITION(A, p, r)
i = RANDOM(p, r)
exchange A[r] with A[i]
return PARTITION(A, p, r)
C++实现也很简单,只需要在排序前随机去一个元素和末端元素交换。
1
2
3
4
5
6
7
8
void rand-quicksort(vector<int>& v, int begin, int end){
if(end-begin<=1) return;
int pindex = rand()%(end-begin) + begin;
swap(v[end-1], v[pindex]);
quicksort(v, begin, end);
}
随机算法保证了对任何的输入而言,都可以保证Θ(𝑛lg𝑛)的时间复杂度。
python示例:
1
2
3
4
5
6
7
8
9
def quicksort(array):
if len(array) < 2:
return array
else:
pivot = array[0]
less = [i for i in array[1:] if i <= pivot]
greater = [i for i in array[1:] if i > pivot]
return quicksort(less) + [pivot] + quicksort(greater)
print((quicksort([10, 5, 2, 3])))
C++实现
按照上述PARTITION过程,实现quicksort方法,用来排序数组v中的[𝑏𝑒𝑔𝑖𝑛,𝑒𝑛𝑑)[begin,end)部分。
1
2
3
4
5
6
7
8
9
10
11
void quicksort(vector<int>& v, int begin, int end){
if(end - begin<=1) return;
int pivot = v[end-1], less_end = begin;
for(int i=begin; i<end-1; i++)
if(v[i]<pivot) swap(v[i], v[less_end++]);
swap(v[end-1], v[less_end]);
quicksort(v, begin, less_end);
quicksort(v, less_end + 1, end);
}
实现思路是这样的:
- 当只有一个元素时,它总是已经排好序的直接返回。
- 取最后一个为
pivot,比pivot小的元素存储在[0,𝑙𝑒𝑠𝑠𝑒𝑛𝑑)中。 - 遍历[𝑏𝑒𝑔𝑖𝑛,𝑒𝑛𝑑−1),如果它小于
pivot就把它添加到[0,𝑙𝑒𝑠𝑠𝑒𝑛𝑑)中,同时让less_end++。 - 将
pivot放到[0,𝑙𝑒𝑠𝑠𝑒𝑛𝑑)的结尾。 - 为[𝑏𝑒𝑔𝑖𝑛,𝑙𝑒𝑠𝑠𝑒𝑛𝑑)排序,此时
less_end处的元素是pivot;同样为右边的[𝑙𝑒𝑠𝑠𝑒𝑛𝑑+1,𝑒𝑛𝑑)也排序。

计数排序— 适合量大但是范围小的情况,桶思想
基数排序 — 多关键词排序,桶思想
🚩215. 数组中的第K个最大元素
难度中等891
在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
示例 1:
1
2
输入: [3,2,1,5,6,4] 和 k = 2
输出: 5
示例 2:
1
2
输入: [3,2,3,1,2,4,5,5,6] 和 k = 4
输出: 4
总结:
-
快速排序思想
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
class Solution: def findKthLargest(self, nums: List[int], k: int) -> int: # # 暴力 O(nlogn) # nums.sort(reverse=True) # return nums[k-1] # 快排思想 k = len(nums) - k # 升序排列后,index为len(nums)-k low = 0 high = len(nums) - 1 while low <= high: p = self.patition(nums, low, high) # 中点坐标 if k < p: high = p-1 elif k > p: low = p+1 else: # k == p, 该中点位置即要找的第K大的值 return nums[p] return -1 # 进行一次分治排序 def patition(self, alist, low, high): mid_value = alist[low] # 初始化中间值为最左边的值 while low < high: while low < high and alist[high] >= mid_value: high -= 1 alist[low] = alist[high] # 因为初始化中间值为最左边的值,所以直接赋值即可 while low < high and alist[low] <= mid_value: low += 1 alist[high] = alist[low] # 右侧的一定操作过了 alist[low] = mid_value return low # 返回中点坐标
-
考点

- 可以利用快排优化O(nlogn)到O(n)
- 时间O(n),最差O(nlogn),空间复杂度:O(log n),递归使用栈空间的空间代价的期望为 O(logn)。
-
快速排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
# 时间复杂度:o(nlogn) def quick_sort(alist, start, end): if start >= end: return mid_value = alist[start] low = start hight = end while low < hight: while low<high and alist[high] >= mid_value: high -= 1 alist[low] = alist[high] while low < high and alist[low] <= mid_value: low += 1 alist[high] = alist[low] alist[low] = mid_value quick_sort(alist, start, low-1) quick_sort(alist, low+1, end) if __name__ == '__main__': li = [54, 26, 93, 17, 77, 31, 44, 55, 20, 13] quick_sort(li, 0, len(li)-1) print(li)
✅ (6m) 215. 数组中的第K个最大元素
在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
1
2
3
4
5
6
7
8
9
10
11
示例 1:
输入: [3,2,1,5,6,4] 和 k = 2
输出: 5
示例 2:
输入: [3,2,3,1,2,4,5,5,6] 和 k = 4
输出: 4
说明:
你可以假设 k 总是有效的,且 1 ≤ k ≤ 数组的长度。
1
2
3
4
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
nums.sort(reverse=True)
return nums[k-1]
1
2
3
4
5
6
from typing import List
nums = [3,2,1,5,6,4]
solution = Solution()
result = solution.findKthLargest(nums ,2)
result