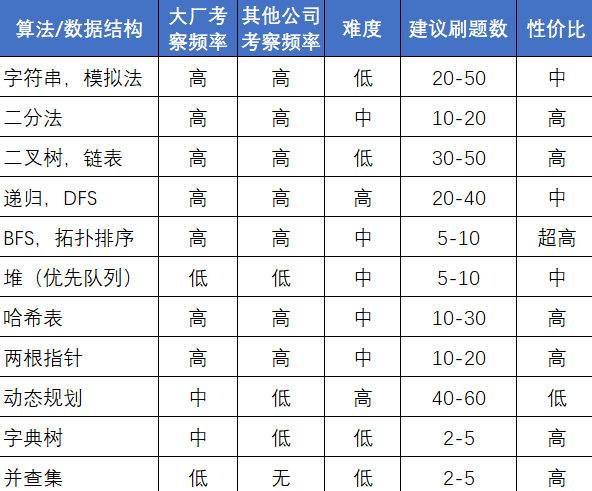
知识点概要
相关笔记
相关资料
做题规范
- 每个题不超过15min思考时间,整个题做题时间不超过30min。
- 按类别刷题时,可以先看书和相关知识点再刷题。
- 只要看见过答案或者提示,就不算自己做出来的题,一定要留到下次完全独立作出才可标记通过。
刷题方法
1、√ 建议未刷过题的新人按着顺序来。
2、[-] 基本熟悉知识点后,可以一类类标签强攻。
3、[-] 面试前的一个月可以只做『Hard』标签的题目,因为一般两遍之后对于大部分『Medium』难度以下的题目都是肌肉记忆了。多练习『Hard』类题目可以让自己的思路更开阔,因为很多题目使用的奇淫巧技让人惊讶
4、善用收藏夹,要养成『一道题第二次练习尚不能解就加入收藏夹』的习惯,且需要定期清空收藏夹:每道题不需提示下通过两次后才能移出收藏夹。
5、面试前可以购买会员,按照公司的标签来练习,也可以结合白板练习。练习的优先级分别是:即将面试公司的题目、收藏夹里的旧题目、剩余的新题。
6、冲刺阶段的练习请尽量不要打开题型标签,给自己思考的空间。
7、如果真的刷了三遍以上还没法达到理想目标,那么一定是学习方法出了问题,请多总结
算法思想
各种数据结构的遍历 + 访问无非两种形式:线性的和非线性的。线性就是 for/while 迭代为代表,非线性就是递归为代表。再具体一步,无非几种框架。
所谓框架,就是套路。不管增删查改,这些代码都是永远无法脱离的结构, 你可以把这个结构作为大纲,根据具体问题在框架上添加代码就行。
刷题建议
- 先刷二叉树
- 因为二叉树是最容易培养框架思维的,而且大部分算法技巧,本质上都是树的遍历问学习算法和刷题的框架思维。
- 对于一个理解二叉树的人来说,刷一道二叉树的题目花不了多⻓时间。那么如果你对刷题无从下手或者有畏惧心理,不妨从二叉树下手,前 10 道也许有点难受;结合框架再做 20 道,也许你就有点自己的理解了;刷完整个专题,再去做什么回溯动规分治专题,你就会发现只要涉及递归的问题,都是树的问题
知识点总结图解
时间复杂度(大O时间)

散列表去重和缓存数据
- Python中的散列表为字典,散列表将键映射到值
1
2
3
4
5
6
7
8
9
10
"""
防止重复
"""
voted = {}
def check_voter(name):
if voted.get(name):
print ("kick them out!")
else:
voted[name] = True
print ("let them vote!")
1
2
3
4
5
In [3]: check_voter('tom')
let them vote!
In [4]: check_voter('tom')
kick them out!
1
2
3
4
5
6
7
8
9
10
11
"""
缓存数据
"""
cache = {}
def get_page(url):
if cache.get(url):
return cache[url]
else:
data = get_data_from_server(url)
cache[url] = data
return data
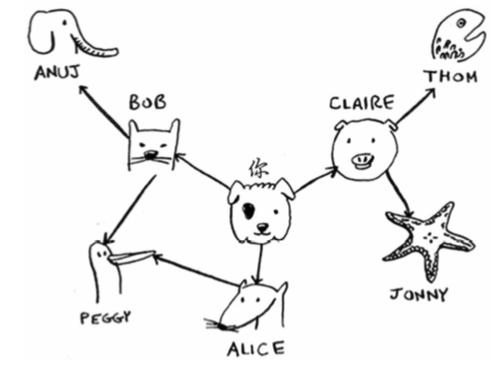
广度优先搜索(图)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
"""
实现图
"""
# map "you" to a list
graph = {}
graph["you"] = ["alice", "bob", "claire"]
graph["bob"] = ["anuj", "peggy"]
graph["alice"] = ["peggy"]
graph["claire"] = ["thom", "jonny"]
graph["anuj"] = []
graph["peggy"] = []
graph["thom"] = []
graph["jonny"] = []
graph
1
2
3
4
5
6
7
8
{'you': ['alice', 'bob', 'claire'],
'bob': ['anuj', 'peggy'],
'alice': ['peggy'],
'claire': ['thom', 'jonny'],
'anuj': [],
'peggy': [],
'thom': [],
'jonny': []}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
"""
实现算法
"""
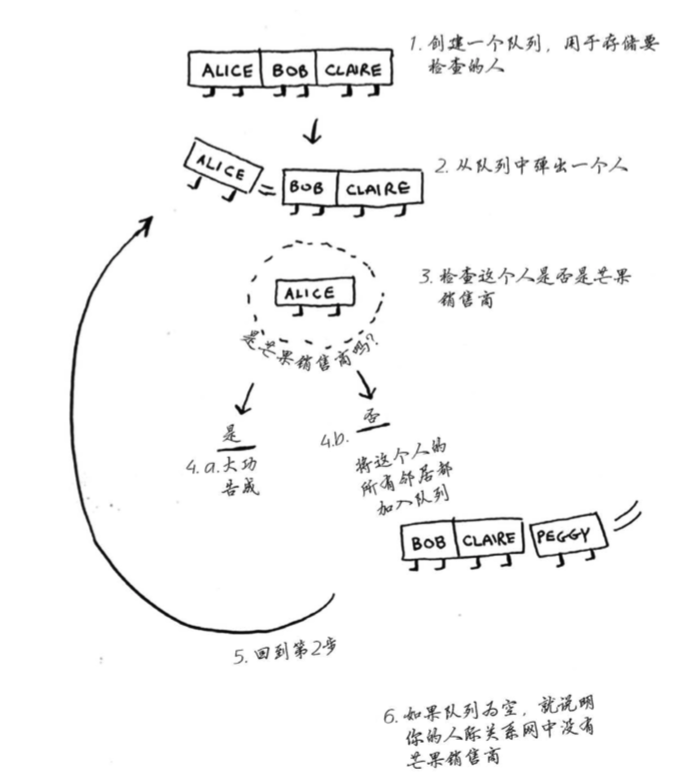
from collections import deque
def person_is_seller(name):
return name[-1] == 'm' # a seller whose name finashed by 'm'
def search(name):
search_queue = deque() # 可使用函数deque来创建一个双端队列
search_queue += graph["you"]
searched = [] # use to record the person who have searched -- it is important
while search_queue:
person = search_queue.popleft()
if not person in searched: # only inspect while did not have searched
if person_is_seller(person):
print(person + " is a mango seller!" )
return True
else:
search_queue += graph[person]
searched.append(person)
return False
search("you")
1
2
3
thom is a mango seller!
True
算法原理
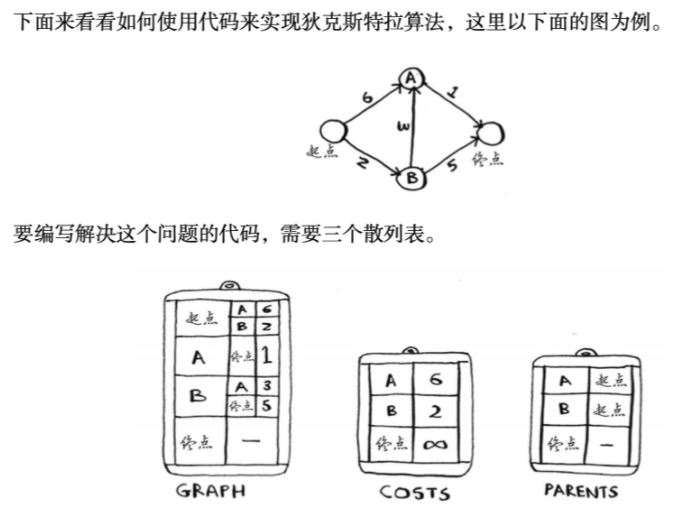
狄克斯特拉算法(计算有权图)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
"""
Graph hash table
"""
graph = {}
graph["start"] = {}
graph["start"]["a"] = 6
graph["start"]["b"] = 2
graph["a"] = {}
graph["a"]["fin"] = 1
graph["b"] = {}
graph["b"]["a"] = 3
graph["b"]["fin"] = 5
graph["fin"] = {} # 终结点无邻居
1
2
3
4
5
6
7
In [9]: # 获取起点的所有邻居
...: graph["start"].keys()
Out[9]: dict_keys(['a', 'b'])
In [10]: # 获得权重
...: graph["start"]["a"]
Out[10]: 6
1
2
3
4
5
6
7
8
9
10
11
"""
Costs hash table
"""
infinity = float("inf")
costs = {}
costs["a"] = 6
costs["b"] = 2
# 不知道到终点需要多长时间。对于还不知道的开销,你将其设置为无穷大。
costs["fin"] = infinity
costs["fin"]
1
inf
1
2
3
4
5
6
7
8
9
"""
Parents hash table
"""
parents = {}
parents["a"] = "start"
parents["b"] = "start"
parents["fin"] = None
# 最后需要一个数组,用于记录处理过的节点,你不用处理多次。
processed = []
算法原理
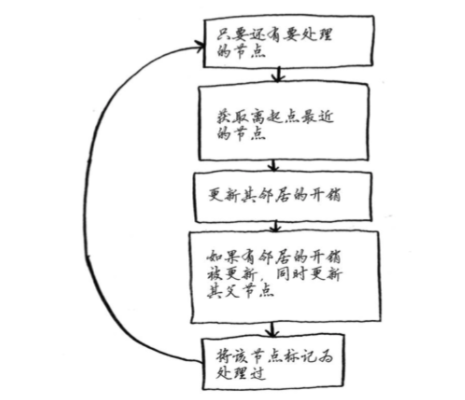
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
def find_lowest_cost_node(costs):
lowest_cost = float("inf")
lowest_cost_node = None
for node in costs:
cost = costs[node]
if cost < lowest_cost and node not in processed:
lowest_cost = cost
lowest_cost_node = node
return lowest_cost_node
node = find_lowest_cost_node(costs)
while node is not None:
cost = costs[node]
neighbors = graph[node]
for n in neighbors.keys():
new_cost = cost + neighbors[n]
if costs[n] > new_cost:
costs[n] = new_cost
parents[n] = node
processed.append(node)
node = find_lowest_cost_node(costs)
print(cost)
1
6
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
# A -- 不对
"""
Graph hash table
"""
graph = {}
graph["start"] = {}
graph["start"]["a"] = 5
graph["start"]["b"] = 2
graph["a"] = {}
graph["a"]["c"] = 4
graph["a"]["d"] = 2
graph["b"] = {} # init, important
graph["b"]["a"] = 8
graph["b"]["d"] = 7
graph["c"] = {}
graph["c"]["d"] = 6
graph["c"]["fin"] = 3
graph["d"] = {}
graph["d"]["fin"] = 1
graph["fin"] = {} # 终结点无邻居
"""
Costs hash table:cost to start
"""
infinity = float("inf")
costs = {}
costs["a"] = infinity
costs["b"] = 2
# 不知道到终点需要多长时间。对于还不知道的开销,你将其设置为无穷大。
costs["c"] = infinity
costs["d"] = infinity
costs["fin"] = infinity
"""
Parents hash table: only record the cost that knows
"""
parents = {}
parents["a"] = None
parents["b"] = "start"
parents["c"] = None
parents["d"] = None
parents["fin"] = None
# 最后需要一个数组,用于记录处理过的节点,你不用处理多次。
processed = []
def find_lowest_cost_node(costs):
lowest_cost = float("inf")
lowest_cost_node = None
for node in costs:
cost = costs[node]
if cost < lowest_cost and node not in processed:
lowest_cost = cost
lowest_cost_node = node
return lowest_cost_node
node = find_lowest_cost_node(costs)
while node is not None:
cost = costs[node]
neighbors = graph[node]
for n in neighbors.keys():
new_cost = cost + neighbors[n]
if costs[n] > new_cost:
costs[n] = new_cost
parents[n] = node
print(costs[n])
processed.append(node)
node = find_lowest_cost_node(costs)
1
2
3
4
5
6
7
10
9
10
14
9
9
10
贪婪算法
- 处理没有快速算法的问题 – NP完全问题
- 每步都寻找局部最优解
集合覆盖问题
具体方法如下。
(1) 列出每个可能的广播台集合,这被称为幂集(power set)。可能的子集有2n个。
(2) 在这些集合中,选出覆盖全美50个州的最小集合。
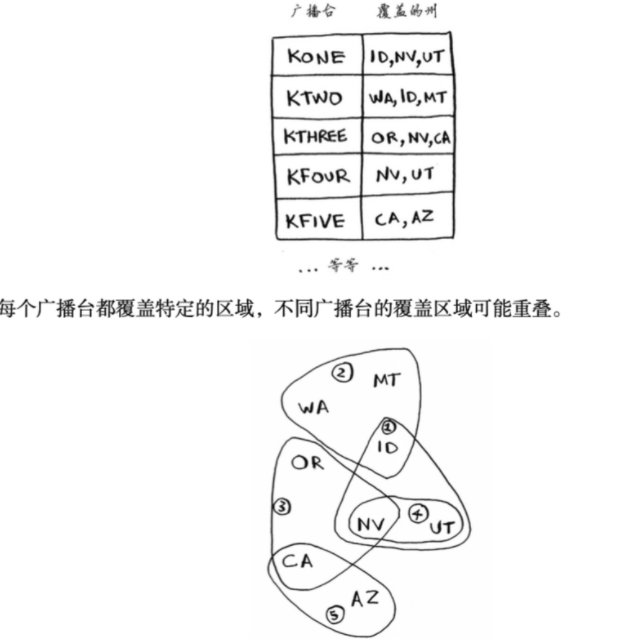
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 不对
states_needed = set(["mt", "wa", "or", "id", "nv", "ut", "ca", "az"])
# 有可供选择的广播台清单,我选择使用散列表来表示它。
stations = {}
stations["kone"] = set(["id", "nv", "ut"])
stations["ktwo"] = set(["wa", "id", "mt"])
stations["kthree"] = set(["or", "nv", "ca"])
stations["kfour"] = set(["nv", "ut"])
stations["kfive"] = set(["ca", "az"])
final_stations = set()
while states_needed:
best_station = None # 存储最优
states_covered = set()
for station, states_for_station in stations.items():
covered = states_needed & states_for_station
if len(covered) > len(states_covered):
best_station = station
states_covered = covered
states_needed -= states_covered
final_stations.add(best_station)
print(final_stations)
动态规划
- 只能处理没有相互依赖关系
- 横向:加入新增商品价值 与 没加入该商品时最大价值(上一行) 比较,选择大的
树
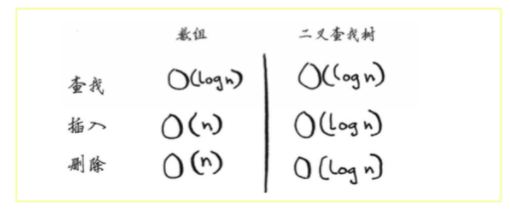
- 不能随机访问
- 平衡时效果才好
分布式算法(MapReduce)
-
并行算法的一种
- 可通过流行的开源工具Apache Hadoop来使用
- 基于两个简单的理念: 映射(map)函数和 归并(reduce)函数。
1
2
3
4
5
6
# 映射函数 map
# 如果有100台计算机,而map能够自动将工作分配给这些计算机去完成就好了。
# 这样就可同时下载100个页面,下载速度将快得多!这就是MapReduce中“映射”部分基于的理念。
arr1 = [1, 2, 3, 4, 5]
arr2 = map(lambda x: 2 * x, arr1)
arr2
1
map?
1
2
3
# 归并reduce()
arr1 = [1, 2, 3, 4, 5]
reduce(lambda x,y: x+y, arr1)
1
2
3
# nums = [3,4,5,1,2]
nums = [2,2,2,0,1]
# nums = [10,1,10,10,10]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class Solution:
def minArray(self, numbers) -> int:
a = 0
b = len(numbers)-1
while a<b:
# prior: numbers[a] > numbers[b]
i = (a+b)//2
# Notice compare the value of b
# Notice need to add 1 to avoid endless loop
if numbers[i] > numbers[b]:
a = i + 1
elif numbers[i] < numbers[b]:
b = i
# Notice this situation
else:
b -= 1
return numbers[b]
1
2
3
solution = Solution()
result = solution.minArray(nums)
result
要注意的知识点
注意 == 和 =
注意如果使用 append(var) 或 = var, 如果var会改变,不能引用!而要用深拷贝或var[:]
如回溯算法、dfs算法、全排列里的路径
注意子函数里的变量有两种定义方式: 1. 传入参数 2.全局变量
查找时可以考虑用 $set$:定义更容易;复杂度比较低,为$O(log(n))$。虽然 $dict$复杂度为 $O(1)$,但是由于有哈希化的过程,所以时间通常也没有少。
如果遇到很难的动态规划题很难想到动态规划方程,可以考虑用回溯方法来做。(实际dp ≈ 回溯+大幅剪枝,如dp表,备忘录)
DFS 可理解为回溯
BFS 一般用队列存储节点周围的结点
extend 使用方式:list.extend([1,2,3])
转换类型:1. [int(i) for i in strings] 2. list(map(lambda x:int(x),deadends))
yield 用法:
1
2
3
4
5
6
7
8
9
10
def fab(max):
n, a, b = 0, 0, 1
while n < max:
yield b # 使用 yield
# print b
a, b = b, a + b
n = n + 1
for n in fab(5):
print n
yield 的作用就是把一个函数变成一个 generator,带有 yield 的函数不再是一个普通函数,Python 解释器会将其视为一个 generator,调用 fab(5) 不会执行 fab 函数,而是返回一个 iterable 对象。可以调用next方法。
Counter函数:
我们先看一个简单的例子:
1
2
3
4
5
6
7
8
9
10
11
#统计词频
colors = ['red', 'blue', 'red', 'green', 'blue', 'blue']
result = {}
for color in colors:
if result.get(color)==None:
result[color]=1
else:
result[color]+=1
print (result)
#{'red': 2, 'blue': 3, 'green': 1}
12345678910
下面我们看用
怎么实现:
1
2
3
4
5
from collections import Counter
colors = ['red', 'blue', 'red', 'green', 'blue', 'blue']
c = Counter(colors)
print (dict(c))
1234
显然代码更加简单了,也更容易读和维护了。