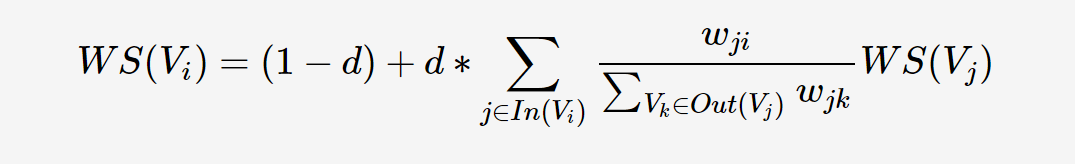
此种算法的一个重要特点是可以脱离语料库的背景,仅对单篇文档进行分析就可以提取该文档的关键词。基本思想来源于Google的PageRank算法。
与PageRank不同的是,PageRank中是有向边,而TextRank中是无向边,或者说是双向边。
可以看出,该公式仅仅比PageRank多了一个权重项Wji,用来表示两个节点之间的边连接有不同的重要程度。考虑到不同词对可能有不同的共现(co-occurrence),TextRank将共现作为无向图边的权值。
提取关键词短语的方法基于关键词提取,可以简单认为:如果提取出的若干关键词在文本中相邻,那么构成一个被提取的关键短语。
将文本中的每个句子分别看做一个节点,如果两个句子有相似性,那么认为这两个句子对应的节点之间存在一条无向有权边。考察句子相似度的方法是下面这个公式:
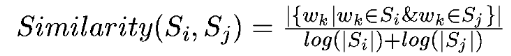
公式中,Si,Sj分别表示两个句子词的个数总数,Wk表示句子中的词,那么分子部分的意思是同时出现在两个句子中的同一个词的个数,分母是对句子中词的个数求对数之和。分母这样设计可以遏制较长的句子在相似度计算上的优势。
我们可以根据以上相似度公式循环计算任意两个节点之间的相似度,根据阈值去掉两个节点之间相似度较低的边连接,构建出节点连接图,然后计算TextRank值,最后对所有TextRank值排序,选出TextRank值最高的几个节点对应的句子作为摘要。
PageRank (PR)是一种用于计算网页权重的算法。我们可以把所有的网页看做一个有向图。在这个图中,一个节点是一个网页。如果网页A有到网页B的链接,则可以表示为A到B的一条有向边。
在我们构造完整个图之后,我们可以用下面的公式为网页分配权重。

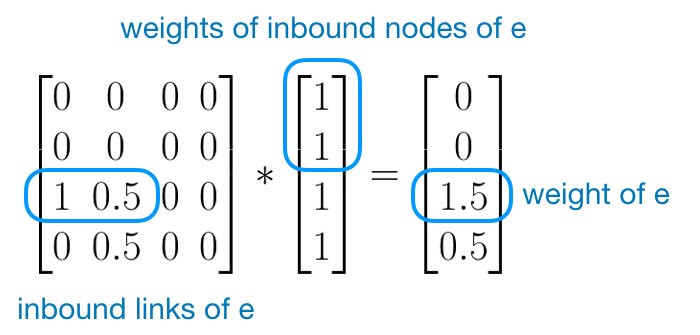
$$ \sum_{所有进入链接j}\frac{j的权重}{j的出链数量} $$我们可以看到网页的权重e取决于其入站页面的权重。我们需要运行这个迭代很多时间来获得最终的权重。初始化时,每个网页的重要性为1。
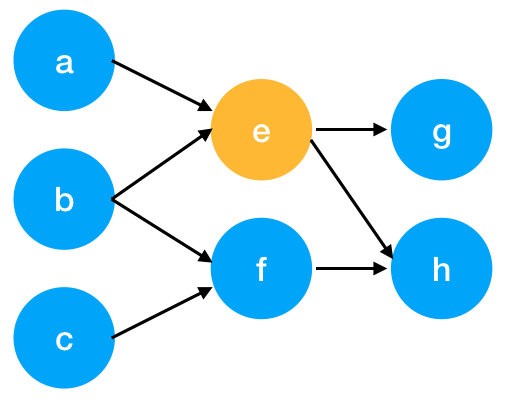
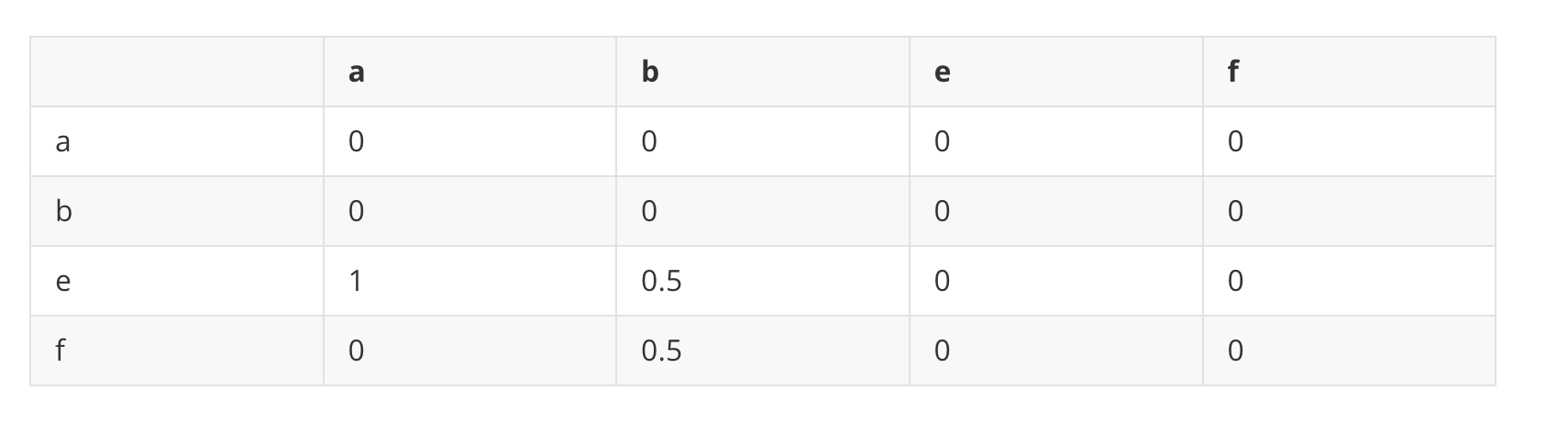
use a matrix to represent the inbound and outbound links
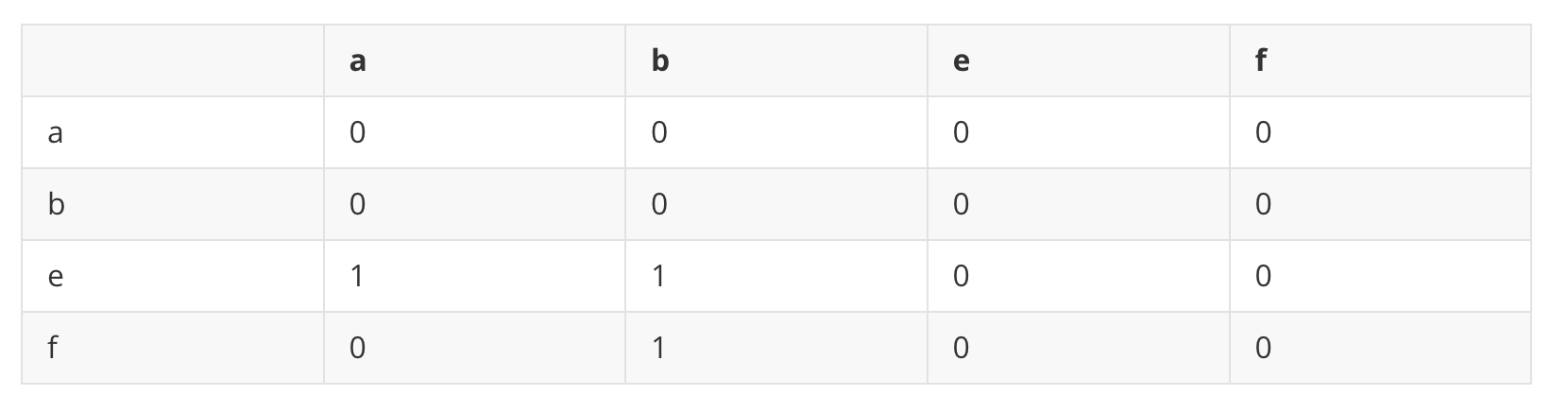
According to the 1/|Out(Vi)| from the function, we should normalize each column.
We use this matrix to multiply with the weight of all nodes.
We can use Python to iterate many times.
import numpy as np
g = [[0, 0, 0, 0],
[0, 0, 0, 0],
[1, 0.5, 0, 0],
[0, 0.5, 0, 0]]
g = np.array(g)
pr = np.array([1, 1, 1, 1]) # initialization for a, b, e, f is 1
d = 0.85
for iter in range(10):
pr = 0.15 + 0.85 * np.dot(g, pr)
print(iter)
print(pr)0
[0.15 0.15 1.425 0.575]
1
[0.15 0.15 0.34125 0.21375]
2
[0.15 0.15 0.34125 0.21375]
3
[0.15 0.15 0.34125 0.21375]
4
[0.15 0.15 0.34125 0.21375]
5
[0.15 0.15 0.34125 0.21375]
6
[0.15 0.15 0.34125 0.21375]
7
[0.15 0.15 0.34125 0.21375]
8
[0.15 0.15 0.34125 0.21375]
9
[0.15 0.15 0.34125 0.21375]
10
[0.15 0.15 0.34125 0.21375]We also can change the code correspondingly.
PageRank是网页排名,TextRank是文本排名。PageRank中的网页就是TextRank中的文本,所以基本思路是一样的。
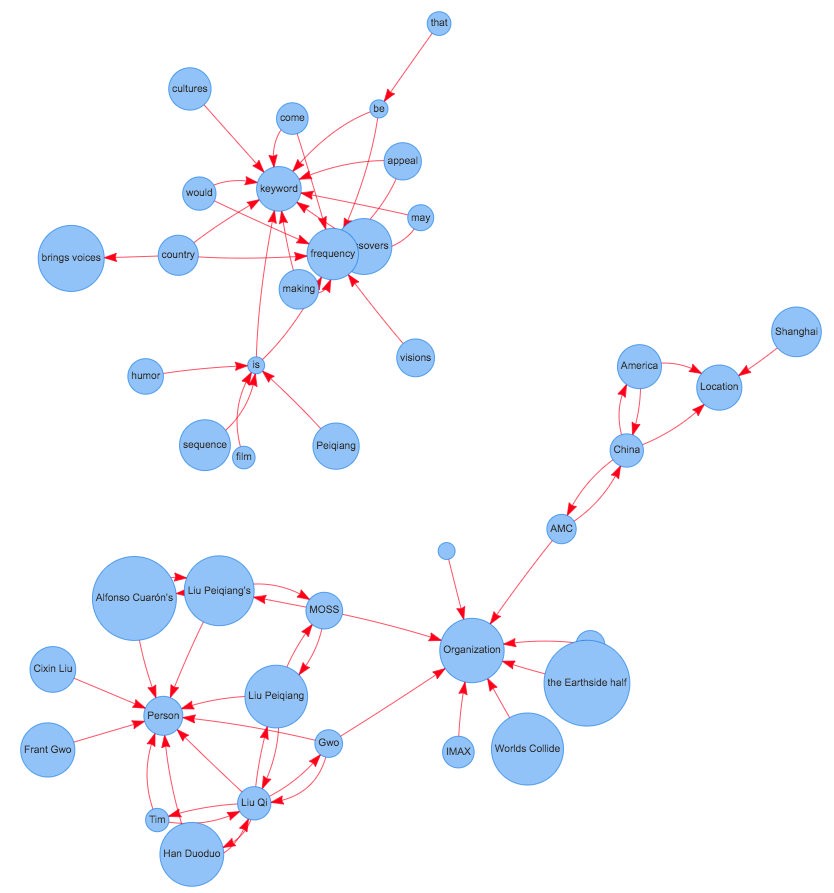
我们将文档分成几个句子,并且只存储带有特定POS标签的单词。我们使用spaCy进行词性标注。
我们把这一段分成三句话。
因为句子中的大多数单词对确定重要性没有用处,我们只考虑带有名词、PROPN、动词词性标签的单词。这是可选的,你也可以使用所有的单词。
Output
[[Wandering, Earth, described, China, budget, science, fiction, thriller, screens, AMC, theaters, North, America, weekend, shows, filmmaking, focused, spectacles, China, epics], [time, Wandering, Earth, feels, throwback, eras, filmmaking], [film, cast, setting, tone, science, fiction, fans, going, lot, screen, reminds, movies]]每个单词都是PageRank中的一个节点。我们将窗口大小设为k。
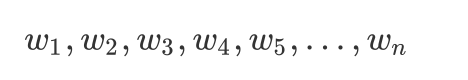
[w1, w2, wk]、[w2, w3, wk + 1], [w3, w4, wk + 2]为windows。我们认为窗口中的任何两字对都有无向边。
我们以[time, Wandering, Earth, feels, throwback, eras, filmmaking]为例,将窗口大小设为k=4,所以我们得到了4个窗口,[time, Wandering, Earth, feels, throwback], [Earth, feels, throwback, eras], [feels, throwback, eras, filmmaking]。
对于[time, Wandering, Earth, feels],任何两个词对都有一个无向边。我们得到(time, Wandering), (time, Earth), (time, feels), (Wandering, Earth), (Wandering, feels), (Earth, feels)
根据这个图,我们可以计算每个节点(单词)的权重。最重要的词可以用作关键词。🚩
在这里,我用Python实现了一个完整的示例,我们使用spaCy来获取单词的POS标记。
text = '''
The Wandering Earth, described as China’s first big-budget science fiction thriller, quietly made it onto screens at AMC theaters in North America this weekend, and it shows a new side of Chinese filmmaking — one focused toward futuristic spectacles rather than China’s traditionally grand, massive historical epics. At the same time, The Wandering Earth feels like a throwback to a few familiar eras of American filmmaking. While the film’s cast, setting, and tone are all Chinese, longtime science fiction fans are going to see a lot on the screen that reminds them of other movies, for better or worse.
'''
tr4w = TextRank4Keyword()
tr4w.analyze(text, candidate_pos = ['NOUN', 'PROPN'], window_size=4, lower=False)
tr4w.get_keywords(10)Output
science - 1.717603106506989
fiction - 1.6952610926181002
filmmaking - 1.4388798751402918
China - 1.4259793786986021
Earth - 1.3088154732297723
tone - 1.1145002295684114
Chinese - 1.0996896235078055
Wandering - 1.0071059904601571
weekend - 1.002449354657688
America - 0.9976329264870932
budget - 0.9857269586649321
North - 0.9711240881032547