重点:
Guido的一条重要的见解是代码阅读比写更加频繁。这里提供的指导原则主要用于提升代码的可读性,使得在大量的Python代码中保持一致。就像PEP 20提到的,“Readability counts”。
每一级缩进使用4个空格。
所有行限制的最大字符数为79。
较长的代码行选择Python在小括号,中括号以及大括号中的隐式续行方式。通过小括号内表达式的换行方式将长串折成多行。这种方式应该优先使用,而不是使用反斜杠续行。
from os.path import (curdir, pardir, sep, pathsep, defpath, extsep, altsep,
devnull)当然了,反斜杠有时依然很有用。比如较长的多个with状态语句,不能使用隐式续行,所以反斜杠是可以接受的:
with open('/path/to/some/file/you/want/to/read') as file_1, \
open('/path/to/some/file/being/written', 'w') as file_2:
file_2.write(file_1.read())遵循数学的传统能产出更多可读性高的代码:
# 推荐:运算符和操作数很容易进行匹配
income = (gross_wages
+ taxable_interest
+ (dividends - qualified_dividends)
- ira_deduction
- student_loan_interest)顶层函数和类的定义,前后用两个空行隔开。类里的方法定义用一个空行隔开。
相关的功能组可以用额外的空行(谨慎使用)隔开。一堆相关的单行代码之间的空白行可以省略(例如,一组虚拟实现 dummy implementations)。
Python标准库中的所有标识符必须使用ASCII标识符,并在可行的情况下使用英语单词(在许多情况下,缩写和技术术语是非英语的)。此外,字符串文字和注释也必须是ASCII。
导入通常在分开的行
推荐使用绝对路径导入,如果导入系统没有正确的配置(比如包里的一个目录在sys.path里的路径后),使用绝对路径会更加可读并且性能更好(至少能提供更好的错误信息):
import mypkg.sibling
from mypkg import sibling
from mypkg.sibling import example
显示的指定相对导入路径是使用绝对路径的一个可接受的替代方案,特别是在处理使用绝对路径导入不必要冗长的复杂包布局时:
from . import sibling
from .sibling import example标准库要避免使用复杂的包引入结构,而总是使用绝对路径。 不应该使用隐式相对路径导入,并且在Python 3中删除了它。
当从一个包含类的模块中导入类时,常常这么写:
from myclass import MyClass from foo.bar.yourclass import YourClass如果上述的写法导致名字的冲突,那么这么写:
import myclass import foo.bar.yourclass然后使用“myclass.MyClass”和“foo.bar.yourclass.YourClass”。
**避免通配符的导入(from import *)**,因为这样做会不知道命名空间中存在哪些名字,会使得读取接口和许多自动化工具之间产生混淆。对于通配符的导入,有一个防御性的做法,即将内部接口重新发布为公共API的一部分(例如,用可选加速器模块的定义覆盖纯Python实现的接口,以及重写那些事先不知道的定义)。 当以这种方式重新发布名称时,以下关于公共和内部接口的准则仍然适用。
冒号在切片中就像二元运算符,在两边应该有相同数量的空格(把它当做优先级最低的操作符)。在扩展的切片操作中,所有的冒号必须有相同的间距。例外情况:当一个切片参数被省略时,空格就被省略了。 推荐:
ham[1:9], ham[1:9:3], ham[:9:3], ham[1::3], ham[1:9:]
ham[lower:upper], ham[lower:upper:], ham[lower::step]
ham[lower+offset : upper+offset]
ham[: upper_fn(x) : step_fn(x)], ham[:: step_fn(x)]
ham[lower + offset : upper + offset]i = i + 1
submitted += 1
x = x*2 - 1
hypot2 = x*x + y*y
c = (a+b) * (a-b)def complex(real, imag=0.0):
return magic(r=real, i=imag)
def munge(input: AnyStr): ...
def munge() -> AnyStr: ...def munge(sep: AnyStr = None): ...
def munge(input: AnyStr, sep: AnyStr = None, limit=1000): ...
if foo == 'blah':
do_blah_thing()
do_one()
do_two()
do_three()与代码相矛盾的注释比没有注释还糟,当代码更改时,优先更新对应的注释! 注释应该是完整的句子。如果一个注释是一个短语或句子,它的第一个单词应该大写,除非它是以小写字母开头的标识符(永远不要改变标识符的大小写!)。 如果注释很短,结尾的句号可以省略。块注释一般由完整句子的一个或多个段落组成,并且每句话结束有个句号。 在句尾结束的时候应该使用两个空格。 当用英文书写时,遵循Strunk and White (译注:《Strunk and White, The Elements of Style》)的书写风格。 在非英语国家的Python程序员,请使用英文写注释,除非你120%的确信你的代码不会被使用其他语言的人阅读。
块注释通常适用于跟随它们的某些(或全部)代码,并缩进到与代码相同的级别。块注释的每一行开头使用一个#和一个空格(除非块注释内部缩进文本)。 块注释内部的段落通过只有一个#的空行分隔。
# Some platforms don't support lchmod(). Often the function exists
# anyway, as a stub that always returns ENOSUP or perhaps EOPNOTSUPP.
# (No, I don't know why that's a good design.) ./configure will detect
# this and reject it--so HAVE_LCHMOD still won't be defined on such
# platforms. This is Very Helpful.
#
# However, sometimes platforms without a working lchmod() *do* have
# fchmodat(). (Examples: Linux kernel 3.2 with glibc 2.15,
# OpenIndiana 3.x.) And fchmodat() has a flag that theoretically makes
# it behave like lchmod(). So in theory it would be a suitable
# replacement for lchmod(). But when lchmod() doesn't work, fchmodat()'s
# flag doesn't work *either*. Sadly ./configure isn't sophisticated
# enough to detect this condition--it only determines whether or not
# fchmodat() minimally works.有节制地使用行内注释。 行内注释是与代码语句同行的注释。行内注释和代码至少要有两个空格分隔。注释由#和一个空格开始。 事实上,如果状态明显的话,行内注释是不必要的,反而会分散注意力。比如说下面这样就不需要:
x = x + 1 # Increment x但有时,这样做很有用:
x = x + 1 # Compensate for border编写好的文档说明(也叫“docstrings”)的约定在PEP 257中永恒不变。
"""Return a foobang
Optional plotz says to frobnicate the bizbaz first.
""""""Get an environment variable, return None if it doesn't exist."""
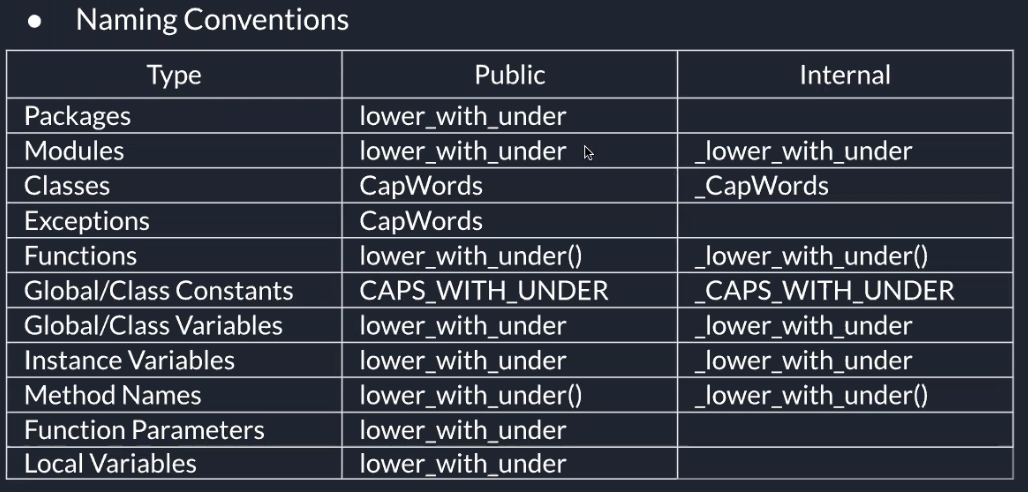
Python库的命名规范很乱,从来没能做到完全一致。但是目前有一些推荐的命名标准。新的模块和包(包括第三方框架)应该用这套标准,但当一个已有库采用了不同的风格,推荐保持内部一致性。
那些暴露给用户的API接口的命名,应该遵循反映使用场景而不是实现的原则。
有许多不同的命名风格。这里能够帮助大家识别正在使用什么样的命名风格,而不考虑他们为什么使用。 以下是常见的命名方式:
也有用唯一的短前缀把相关命名组织在一起的方法。这在Python中不常用,但还是提一下。比如,os.stat()函数中包含类似以st_mode,st_size,st_mtime这种传统命名方式命名的变量。(这么做是为了与 POSIX 系统的调用一致,以帮助程序员熟悉它。) X11库的所有公共函数都加了前缀X。在Python里面没必要这么做,因为属性和方法在调用的时候都会用类名做前缀,函数名用模块名做前缀。 另外,下面这种用前缀或结尾下划线的特殊格式是被认可的(通常和一些约定相结合):
__double_leading_underscore:(双下划线开头)当这样命名一个类的属性时,调用它的时候名字会做矫正(在类FooBar中,__boo变成了_FooBar__boo;见下文)。__double_leading_and_trailing_underscore__:(双下划线开头,双下划线结尾)“magic”对象或者存在于用户控制的命名空间内的属性,例如:__init__,__import__或者__file__。除了作为文档之外,永远不要命这样的名。永远不要使用字母‘l’(小写的L),‘O’(大写的O),或者‘I’(大写的I)作为单字符变量名。 在有些字体里,这些字符无法和数字0和1区分,如果想用‘l’,用‘L’代替。
模块应该用简短全小写的名字,如果为了提升可读性,下划线也是可以用的。Python包名也应该使用简短全小写的名字,但不建议用下划线。 当使用C或者C++编写了一个依赖于提供高级(更面向对象)接口的Python模块的扩展模块,这个C/C++模块需要一个下划线前缀(例如:_socket)
类名一般使用首字母大写的约定。 在接口被文档化并且主要被用于调用的情况下,可以使用函数的命名风格代替。 注意,对于内置的变量命名有一个单独的约定:大部分内置变量是单个单词(或者两个单词连接在一起),首字母大写的命名法只用于异常名或者内部的常量。
因为异常一般都是类,所有类的命名方法在这里也适用。然而,你需要在异常名后面加上“Error”后缀(如果异常确实是一个错误)。
(我们希望这一类变量只在模块内部使用。)约定和函数命名规则一样。 通过 from M import * 导入的模块应该使用all机制去防止内部的接口对外暴露,或者使用在全局变量前加下划线的方式(表明这些全局变量是模块内非公有)。
函数名应该小写,如果想提高可读性可以用下划线分隔。 大小写混合仅在为了兼容原来主要以大小写混合风格的情况下使用(比如 threading.py),保持向后兼容性。
始终要将 self 作为实例方法的的第一个参数。 始终要将 cls 作为类静态方法的第一个参数。 如果函数的参数名和已有的关键词冲突,在最后加单一下划线比缩写或随意拼写更好。因此 class_ 比 clss 更好。(也许最好用同义词来避免这种冲突)
遵循这样的函数命名规则:使用下划线分隔小写单词以提高可读性。 在非共有方法和实例变量前使用单下划线。 通过双下划线前缀触发Python的命名转换规则来避免和子类的命名冲突。 Python通过类名对这些命名进行转换:如果类 Foo 有一个叫 __a 的成员变量, 它无法通过 Foo.__a 访问。(执着的用户可以通过 Foo._Foo__a 访问。)一般来说,前缀双下划线用来避免类中的属性命名与子类冲突的情况。 注意:关于__names的用法存在争论(见下文)。
常量通常定义在模块级,通过下划线分隔的全大写字母命名。例如: MAX_OVERFLOW 和 TOTAL。
始终要考虑到一个类的方法和实例变量(统称:属性)应该是共有还是非共有。如果存在疑问,那就选非共有;因为将一个非共有变量转为共有比反过来更容易。 公共属性是那些与类无关的客户使用的属性,并承诺避免向后不兼容的更改。非共有属性是那些不打算让第三方使用的属性;你不需要承诺非共有属性不会被修改或被删除。 我们不使用“私有(private)”这个说法,是因为在Python中目前还没有真正的私有属性(为了避免大量不必要的常规工作)。 另一种属性作为子类API的一部分(在其他语言中通常被称为“protected”)。有些类是专为继承设计的,用来扩展或者修改类的一部分行为。当设计这样的类时,要谨慎决定哪些属性时公开的,哪些是作为子类的API,哪些只能在基类中使用。 贯彻这样的思想,一下是一些让代码Pythonic的准则:
Yes: _time ``=` `lst[index]``No: t ``=` `lst[index]推荐:
class` `Student(``object``):`` ``def` `__init__(``self``,name):`` ``self``.name ``=` `name不推荐:
class` `Student(``object``):`` ``def` `__init__(``self``,name):`` ``self``.__name ``=` `name`` ` ` ``def` `get_name(``self``):`` ``return` `self``.__name`` ` ` ``def` `set_name(``self``,name):`` ``self``.__name ``=` `name__getattr__()。然而命名转换的算法有很好的文档说明并且很好操作。 注意3:不是所有人都喜欢命名转换。尽量避免意外的名字冲突和潜在的高级调用。任何向后兼容保证只适用于公共接口,因此,用户清晰地区分公共接口和内部接口非常重要。 文档化的接口被认为是公开的,除非文档明确声明它们是临时或内部接口,不受通常的向后兼容性保证。所有未记录的接口都应该是内部的。 为了更好地支持内省(introspection),模块应该使用__all__属性显式地在它们的公共API中声明名称。将__all__设置为空列表表示模块没有公共API。 即使通过__all__设置过,内部接口(包,模块,类,方法,属性或其他名字)依然需要单个下划线前缀。 如果一个命名空间(包,模块,类)被认为是内部的,那么包含它的接口也应该被认为是内部的。 导入的名称应该始终被视作是一个实现的细节。其他模块必须不能间接访问这样的名称,除非它是包含它的模块中有明确的文档说明的API,例如 os.path 或者是一个包里从子模块公开函数接口的 __init__ 模块。
这时候应该始终用 is 或者 is not,永远不要用等号运算符。
推荐:
url ``=` `'ramaxel'``if` `url ``is` `None``:`` ``do something不推荐:
url ``=` `'ramaxel'``if` `url ``=``=` `None``:`` ``do something另外,如果你在写 if x 的时候,请注意你是否表达的意思是 if x is not None。举个例子,当测试一个默认值为None的变量或者参数是否被设置为其他值的时候。这个其他值应该是在上下文中能成为bool类型false的值。
正确: ``if` `greeting:``糟糕: ``if` `greeting ``=``=` `True``:``更糟: ``if` `greeting ``is` `True``:虽然这两种表达式在功能上完全相同,但前者更易于阅读,所以优先考虑。 推荐:
if` `foo ``is` `not` `None``:不推荐:
if` `not` `foo ``is` `None``:rich comparisons,一种复杂的对象间比较的新机制,允许返回值不为-1,0,1,实现排序操作的时候,最好实现全部的六个操作符(__eq__, __ne__, __lt__, __gt__, __ge__)而不是依靠其他的代码去实现特定的比较。 为了最大程度减少这一过程的开销, functools.total_ordering() 修饰符提供了用于生成缺少的比较方法的工具。 PEP 207 指出Python实现了反射机制。因此,解析器会将 y > x 转变为 x < y,将 y >= x 转变为 x <= y,也会转换x == y 和 x != y的参数。sort() 和 min()方法确保使用<操作符,max()使用>操作符。然而,最好还是实现全部六个操作符,以免在其他地方出现冲突。
始终使用def表达式,而不是通过赋值语句将lambda表达式绑定到一个变量上。 推荐:
def` `f(x): ``return` `2``*``x不推荐:
f ``=` `lambda` `x: ``2``*``x第一个形式意味着生成的函数对象的名称是“f”而不是泛型“< lambda >”。这在回溯和字符串显示的时候更有用。赋值语句的使用消除了lambda表达式优于显式def表达式的唯一优势(即lambda表达式可以内嵌到更大的表达式中)。
高质量代码的检测,主要通过以下3步:
用pycharmproblem里的PEP8提示检查规范问题
用pytest做局部测试
可以用mypy检测类型问题
mypy your_file.py
top-level函数和class定义 — 2行
class里面的函数定义 — 1行
一般都用:
字母+_
Classes和Exception用:大写开头单词
常量用:全大写+_
有利于提升可读性和可维护性,通过type hint可以让类别检查器(如mypy)把run-time error转变为build-time error.
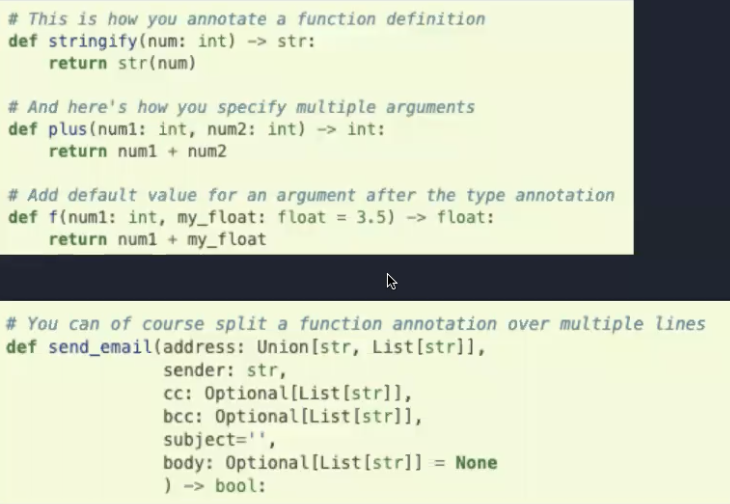
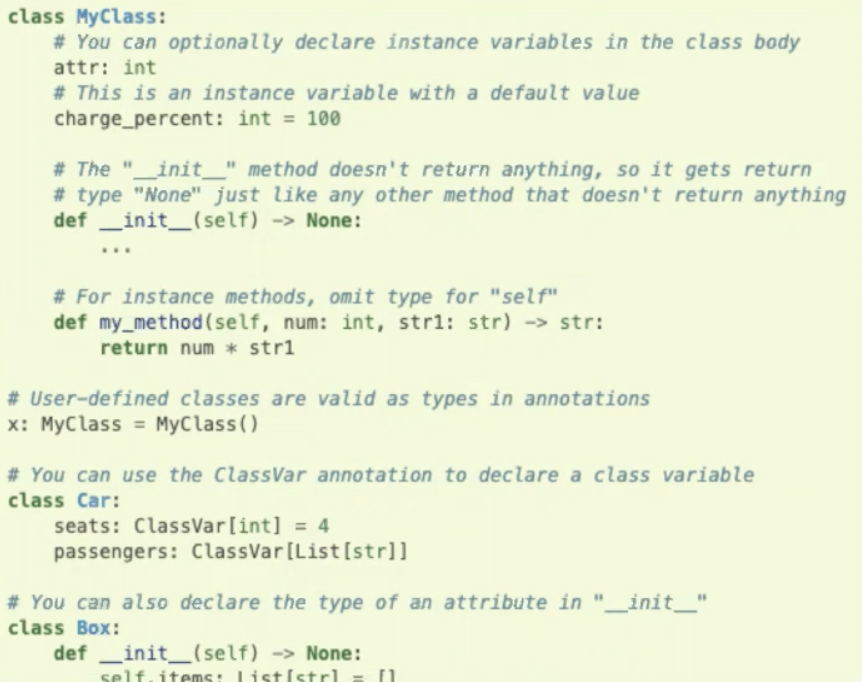
对于代码质量的提升非常有帮助
通过pytest