https://zhuanlan.zhihu.com/p/37522339
使用GBDT的好处:利用GBDT可以自动进行特征筛选和特征组合,进而生成新的离散特征向量。因为回归树中每个节点的分裂是一个自然的特征选择的过程,而多层节点的结构则对特征进行了有效地自动组合。所以可以非常高效地解决棘手的特征选择和特征组合的问题。
实验中设置30棵树,深度为8。每颗树都相当于一个类别特征,每棵树的叶子结点数相当于特征值的个数。
df_train = pd.read_csv('data/train.csv')
df_test = pd.read_csv('data/test.csv')
NUMERIC_COLS = [
"ps_reg_01", "ps_reg_02", "ps_reg_03",
"ps_car_12", "ps_car_13", "ps_car_14", "ps_car_15",
]
print(df_test.head(10))
y_train = df_train['target'] # training label
y_test = df_test['target'] # testing label
X_train = df_train[NUMERIC_COLS] # training dataset
X_test = df_test[NUMERIC_COLS] # testing dataset
# create dataset for lightgbm
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': {'binary_logloss'},
'num_leaves': 64,
'num_trees': 100,
'learning_rate': 0.01,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'verbose': 0
}
# number of leaves,will be used in feature transformation
num_leaf = 64
print('Start training...')
# train
gbm = lgb.train(params,
lgb_train,
num_boost_round=100,
valid_sets=lgb_train)
print('Save model...')
# save model to file
gbm.save_model('model.txt')
print('Start predicting...')
# predict and get data on leaves, training data在训练得到100棵树之后,我们需要得到的不是GBDT的预测结果,而是每一条训练数据落在了每棵树的哪个叶子结点上,因此需要使用下面的语句:
打印上面结果的输出,可以看到shape是(8001,100),即训练数据量*树的棵树
结果为:
(8001, 100)
[[43 26 47 47 47 19 36 19 50 52 29 0 0 0 46 23 13 27 27 13 10 22 0 10
4 57 17 55 54 57 59 42 22 22 22 13 8 5 27 5 58 23 58 14 16 16 10 32
60 32 4 4 4 4 4 46 57 48 57 34 54 6 35 6 4 55 13 23 15 51 40 0
47 40 10 29 24 24 31 24 55 3 41 3 22 57 6 0 6 6 57 55 57 16 12 18
30 15 17 30]]其实实验中到这一步就可以了,得到了每个样本落到每颗树的叶子节点位置,相当于这样样本在每个类别特征中的取值。
print('Writing transformed training data')
transformed_training_matrix = np.zeros([len(y_pred), len(y_pred[0]) * num_leaf],
dtype=np.int64) # N * num_tress * num_leafs
for i in range(0, len(y_pred)):
temp = np.arange(len(y_pred[0])) * num_leaf + np.array(y_pred[I])
transformed_training_matrix[i][temp] += 1y_pred = gbm.predict(X_test, pred_leaf=True)
print('Writing transformed testing data')
transformed_testing_matrix = np.zeros([len(y_pred), len(y_pred[0]) * num_leaf], dtype=np.int64)
for i in range(0, len(y_pred)):
temp = np.arange(len(y_pred[0])) * num_leaf + np.array(y_pred[I])
transformed_testing_matrix[i][temp] += 1lm = LogisticRegression(penalty='l2',C=0.05) # logestic model construction
lm.fit(transformed_training_matrix,y_train) # fitting the data
y_pred_test = lm.predict_proba(transformed_testing_matrix) # Give the probabilty on each label我们这里得到的不是简单的类别,而是每个类别的概率。
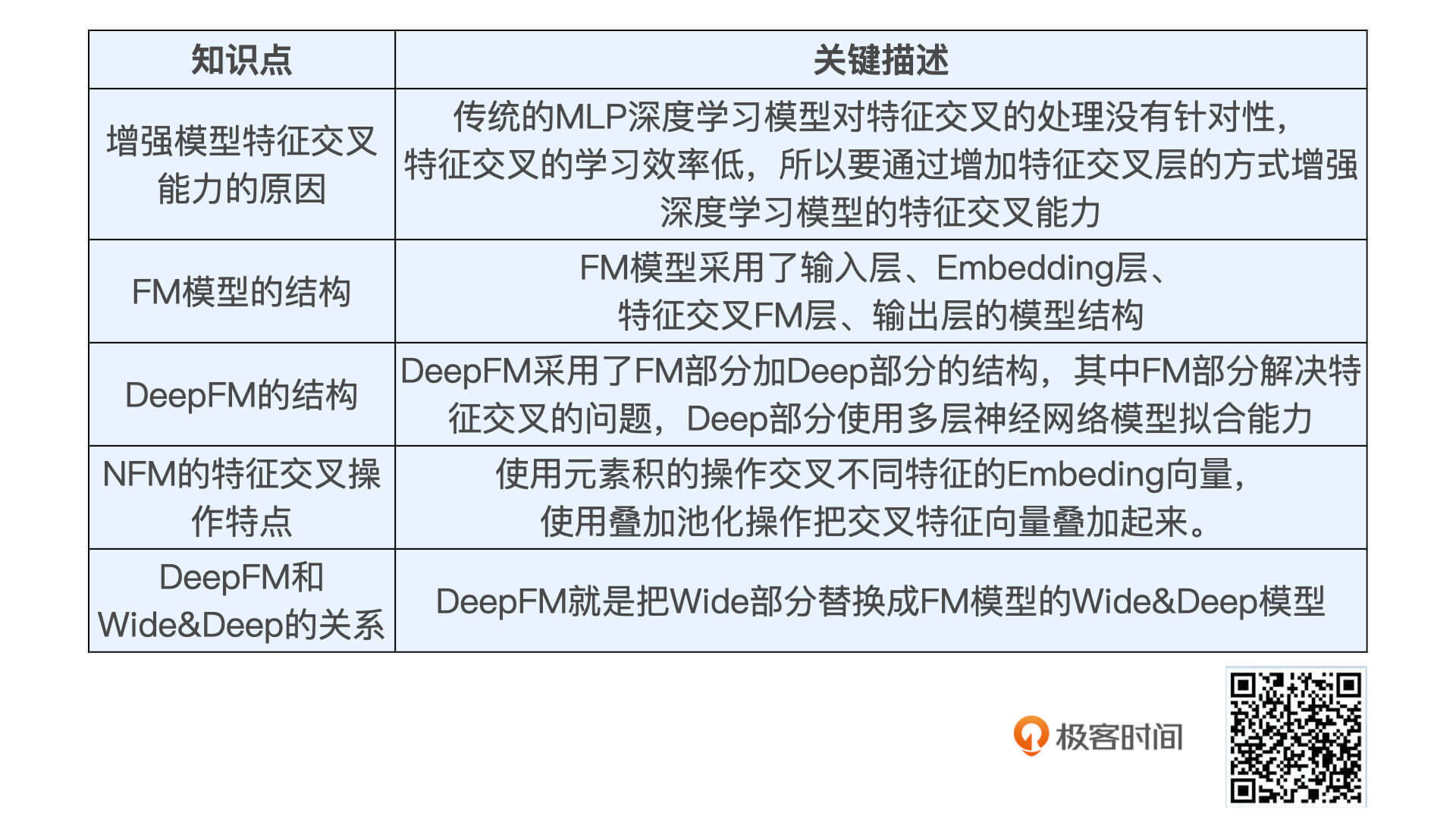
DeepFM 模型在解决特征交叉问题上非常有优势,它会使用一个独特的 FM 层来专门处理特征之间的交叉问题。
具体来说,就是使用点积、元素积等操作让不同特征之间进行两两组合,再把组合后的结果输入的输出神经元中,这会大大加强模型特征组合的能力。因此,DeepFM 模型相比于 Embedding MLP、Wide&Deep 等模型,往往具有更好的推荐效果。
DeepFM包含两部分:因子分解机部分与神经网络部分,分别负责低阶特征的提取和高阶特征的提取。这两部分共享同样的嵌入层输入。
嵌入层: 主要根据特征索引得到对应特征的embedding。
通过嵌入层,尽管不同field的长度不同(不同离散变量的取值个数可能不同),但是embedding之后向量的长度均为K
FM: FM部分是一个因子分解机。因为引入了隐变量的原因,对于几乎不出现或者很少出现的隐变量,FM也可以很好的学习。FM的输出公式包含了线性项和二阶特征项: 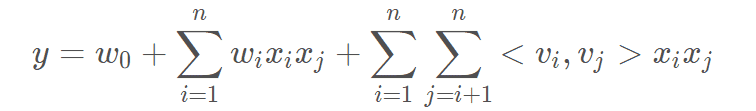
深度部分: 深度部分是一个多层前馈神经网络。其中使用relu作为网络的激活函数,输出层使用sigmoid作为激活函数。
DeepFM的预测结果可以写为:
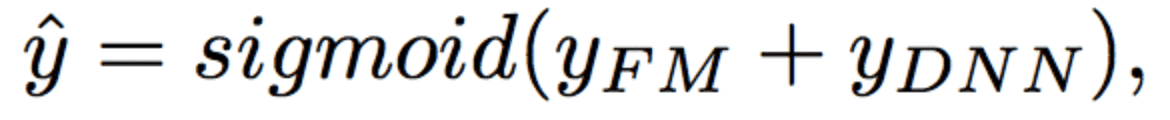
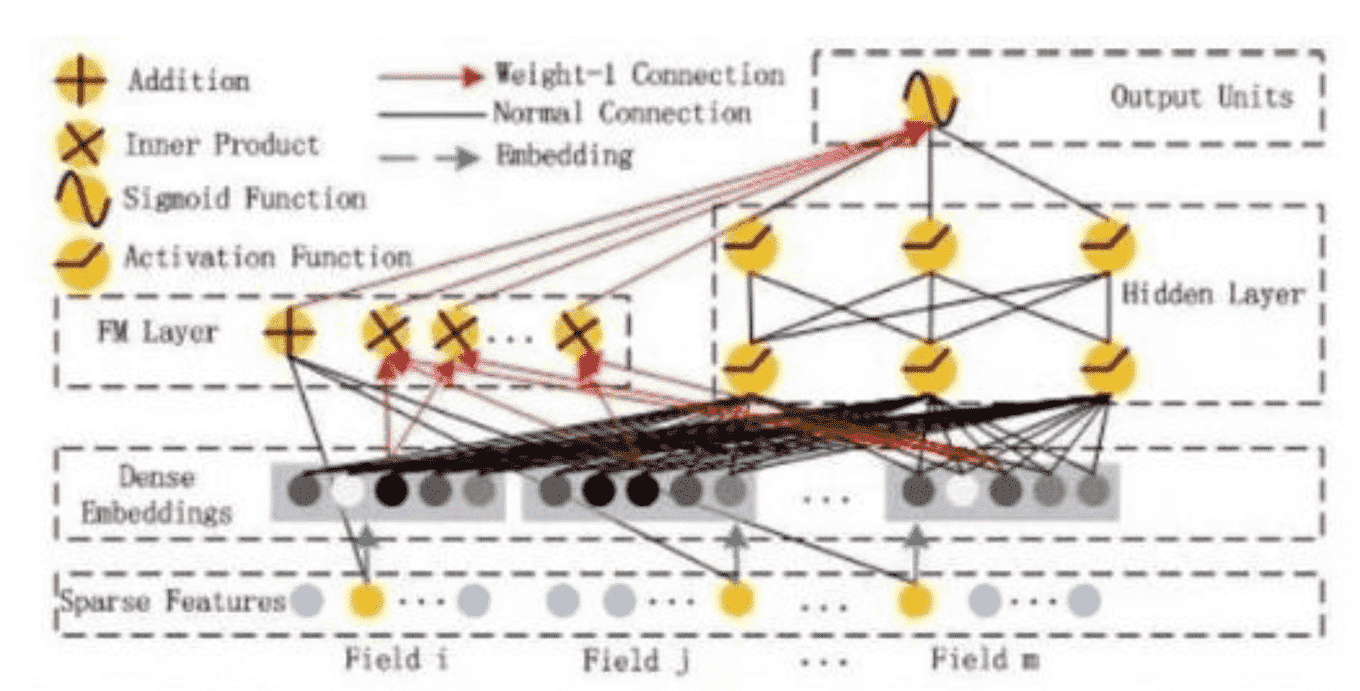
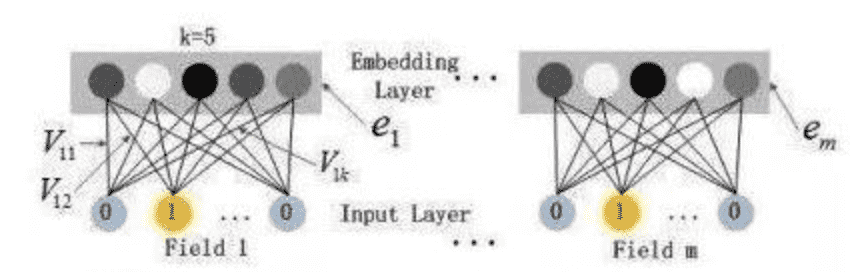
嵌入层(embedding layer)的结构如上图所示。通过嵌入层,尽管不同field的长度不同(不同离散变量的取值个数可能不同),但是embedding之后向量的长度均为K(我们提前设定好的embedding-size)。通过代码可以发现,在得到embedding之后,我们还将对应的特征值乘到了embedding上,这主要是由于fm部分和dnn部分共享嵌入层作为输入,而fm中的二次项如下:🚩
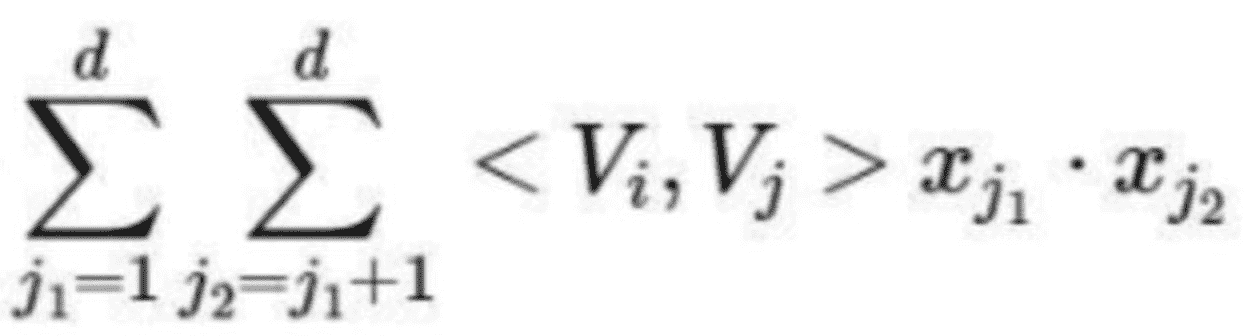
Vi,vj是embedding向量(内积),xj1·xj2是特征值,若:
- 类别向量: xji 是类别向量,xji取1
- 数值特征:按原来取值
DeepFM中,很重要的一项就是embedding操作,所以我们先来看看什么是embedding,可以简单的理解为,将一个特征转换为一个向量。
在推荐系统当中,我们经常会遇到离散变量,如userid、itemid。对于离散变量,我们一般的做法是将其转换为one-hot,但对于itemid这种离散变量,转换成one-hot之后维度非常高,但里面只有一个是1,其余都为0。这种情况下,我们的通常做法就是将其转换为embedding。
embedding的过程是什么样子的呢?它其实就是一层全连接的神经网络,如下图所示:
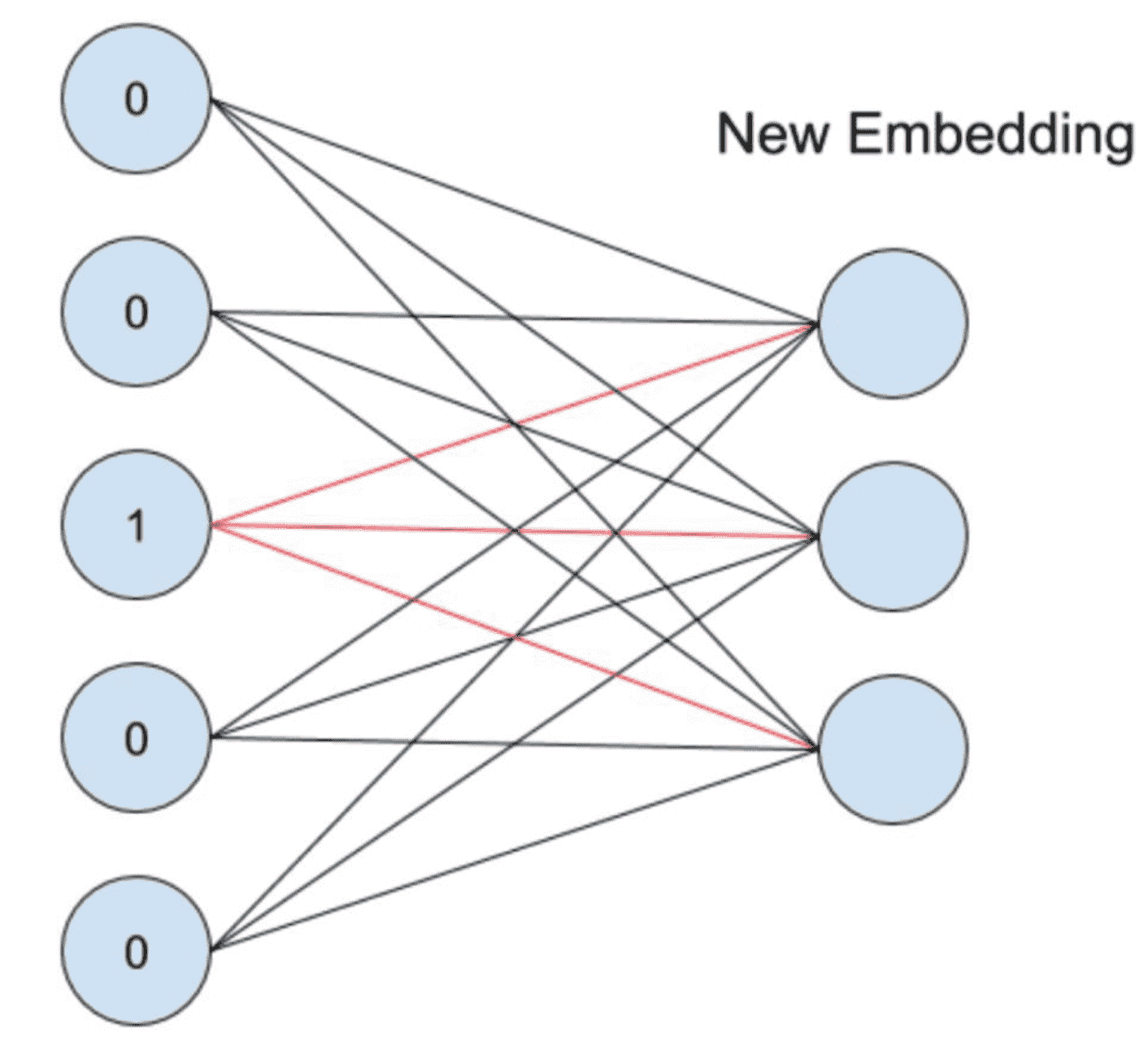
假设一个离散变量共有5个取值,也就是说one-hot之后会变成5维,我们想将其转换为embedding表示,其实就是接入了一层全连接神经网络。由于只有一个位置是1,其余位置是0,因此得到的embedding就是与其相连的图中红线上的权重。
在tf1.x中,我们使用embedding_lookup函数来实现embedding,代码如下:
在embedding_lookup中,第一个参数相当于一个二维的词表,并根据第二个参数中指定的索引,去词表中寻找并返回对应的行。上面的过程为:
因此,使用embedding_lookup的话,我们不需要将数据转换为one-hot形式,只需要传入对应的feature的index即可。
接下来进入代码实战部分。
首先我们来看看数据处理部分,通过刚才的讲解,想要给每一个特征对应一个k维的embedding,如果我们使用embedding_lookup的话,需要得到连续变量或者离散变量对应的特征索引feature index。
可以看到,此时共有5个field,一个连续特征就对应一个field。
但是在FM的公式中,不光是embedding的内积,特征取值也同样需要。对于离散变量来说,特征取值就是1,对于连续变量来说,特征取值是其本身,因此,我们想要得到的数据格式如下:

部分数据集如下:

接下来,想要得到一个feature-map。这个featrue-map定义了如何将变量的不同取值转换为其对应的特征索引feature-index。
定义了total_feature来得到总的特征数量,定义了feature_dict来得到变量取值到特征索引的对应关系,结果如下:
可以看到,对于连续变量,直接是变量名到索引的映射,对于离散变量,内部会嵌套一个二级map,这个二级map定义了该离散变量的不同取值到索引的映射。
下一步,需要将训练集和测试集转换为两个新的数组,分别是feature-index,将每一条数据转换为对应的特征索引,以及feature-value,将每一条数据转换为对应的特征值。
此时的训练集的特征索引:
特征值:离散变量特征取值为1,连续变量特征取值为本身
接下来定义模型的一些参数,如:学习率(0.001)、embedding的大小(8)、深度网络的参数(Epoch:30 batch_size:1024 Optimizer:adam)、激活函数(tf.nn.relu)等等,还有两个比较重要的参数,分别是feature的大小和field的大小:
"""模型参数"""
dfm_params = {
"use_fm":True,
"use_deep":True,
"embedding_size":8,
"dropout_fm":[1.0,1.0],
"deep_layers":[32,32],
"dropout_deep":[0.5,0.5,0.5],
"deep_layer_activation":tf.nn.relu,
"epoch":30,
"batch_size":1024,
"learning_rate":0.001,
"optimizer":"adam",
"batch_norm":1,
"batch_norm_decay":0.995,
"l2_reg":0.01,
"verbose":True,
"eval_metric":'gini_norm',
"random_seed":3
}
dfm_params['feature_size'] = total_feature
dfm_params['field_size'] = len(train_feature_index.columns)而训练模型的输入有三个,分别是刚才转换得到的特征索引和特征值,以及label:
"""开始建立模型"""
feat_index = tf.placeholder(tf.int32,shape=[None,None],name='feat_index')
feat_value = tf.placeholder(tf.float32,shape=[None,None],name='feat_value')
label = tf.placeholder(tf.float32,shape=[None,1],name='label')定义好输入之后,再定义一下模型中所需要的weights:
介绍两个比较重要的参数:
嵌入层,主要根据特征索引得到对应特征的embedding:
"""embedding"""
embeddings = tf.nn.embedding_lookup(weights['feature_embeddings'],feat_index)
reshaped_feat_value = tf.reshape(feat_value,shape=[-1,dfm_params['field_size'],1])
embeddings = tf.multiply(embeddings,reshaped_feat_value)这里注意的是,在得到对应的embedding之后,还乘上了对应的特征值,这个主要是根据FM的公式得到的。过程表示如下:

我们先来回顾一下FM的公式,在传统的一阶线性回归之上,加了一个二次项,可以表达两两特征的相互关系。
在传统的一阶线性回归之上,加了一个二次项,可以表达两两特征的相互关系。

这里的公式可以简化,减少计算量,
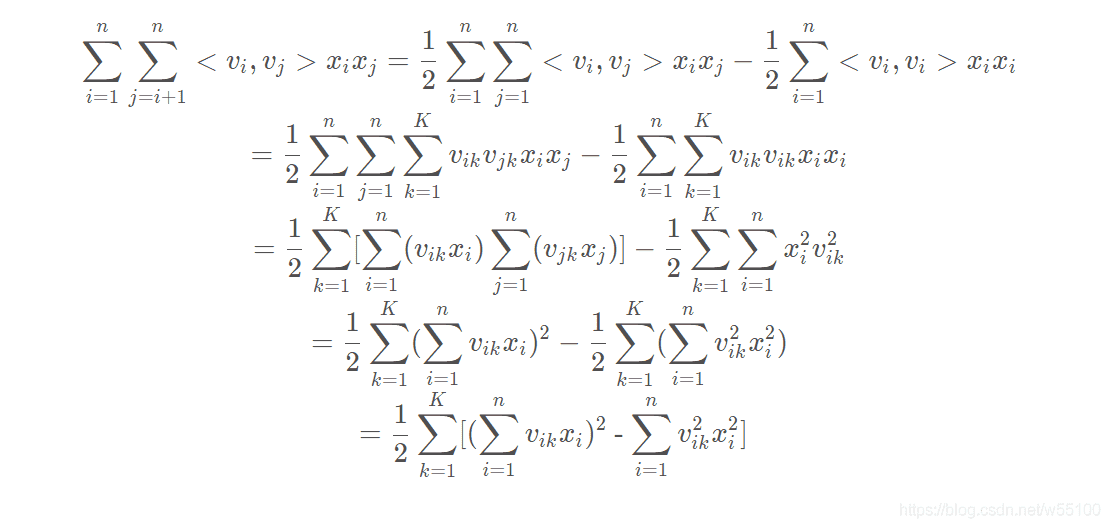
Deep部分很简单了,就是多层全连接网络。
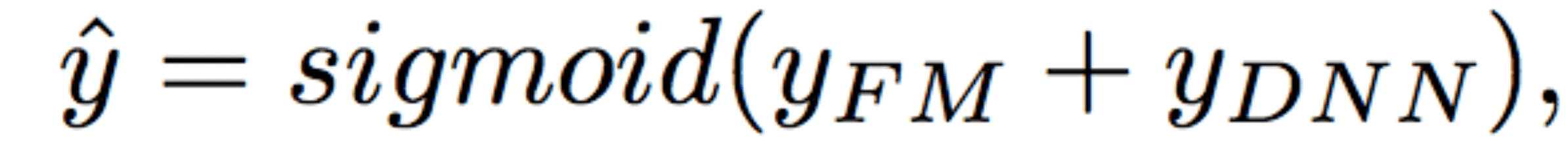
import pandas as pd
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from sklearn.model_selection import train_test_split
from deepctr.models import DeepFM
from deepctr.feature_column import SparseFeat, DenseFeat,get_feature_names
data = pd.read_csv('./criteo_sample.txt') #读取数据
sparse_features = ['C' + str(i) for i in range(1, 27)] #稀疏特征一般是类别特征
dense_features = ['I'+str(i) for i in range(1, 14)]
data[sparse_features] = data[sparse_features].fillna('-1', ) # fillna是对空值的填充处理函数
data[dense_features] = data[dense_features].fillna(0,)
target = ['label'] 稠密特征只有一个取值,疑问:稠密特征怎么计算embedding?答:在得到对应的embedding之后,还乘上了对应的特征值,这个主要是根据FM的公式得到的。对于类别特征乘的值是1,对于稠密特征来说需要乘的值是特征值50/100/…,所以对每个稠密特征相当于构造了一个1*k的embedding向量,只不过不同的取值需要对embedding向量乘特征值。
# 标签编码
fixlen_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].max() + 1,embedding_dim=4) # 设置embedding维度8
for i,feat in enumerate(sparse_features)] \ # 因为之前编码从0开始,所以特征值的个数为data[feat].max()+1
+ [DenseFeat(feat, 1,) for feat in dense_features] # 稠密特征只有一个取值,疑问:稠密特征怎么计算embedding?
# 或者
fixlen_feature_columns = [SparseFeat(feat, data[feat].nunique())
for feat in sparse_features] + [DenseFeat(feat, 1, ) for feat in dense_features]
#生成特征列
dnn_feature_columns = fixlen_feature_columns #用做dnn的输入向量
linear_feature_columns = fixlen_feature_columns #用在线性模型的输入特征
#获取所有特征的名字
feature_names = get_feature_names(linear_feature_columns + dnn_feature_columns) train, test = train_test_split(data, test_size=0.2) #按照8:2的比例划分数据集为训练集合测试集
train_model_input = {name:train[name].values for name in feature_names}
test_model_input = {name:test[name].values for name in feature_names}
model = DeepFM(linear_feature_columns, dnn_feature_columns, embedding_size=8,
use_fm=True, dnn_hidden_units=(256, 256, 256), l2_reg_linear=0.001,
l2_reg_embedding=0.001, l2_reg_dnn=0, init_std=0.0001, seed=1024,
dnn_dropout=0.5, dnn_activation='relu', dnn_use_bn=True, task='binary') #调用deepctr库中的DeepFM模型,执行二分类任务
model.compile("adam", "binary_crossentropy",
metrics=['accuracy', 'AUC'], ) #设置优化器,损失函数类型和评估指标
history = model.fit(train_model_input, train[target].values,
batch_size=256, epochs=10, verbose=2, validation_split=0.2, ) #fit数据
pred_ans = model.predict(test_model_input, batch_size=256) # 预测1、DeepFM(FM Component + Deep Component)包含两部分:因子分解机(FM)部分与(DNN)部分,FM部分负责低阶特征的提取(包括一阶和二阶,虽然FM也可以实现高于二阶的特征提取,但是由于计算复杂度的限制,一般只计算到二阶),DNN部分负责高阶特征的提取,这样可以避免人工构造复杂的特征工程。
2、共享feature embedding。FM和Deep共享输入和feature embedding不但使得训练更快,而且使得训练更加准确。
DeepFM:在Wide&Deep的基础上进行改进,
把wide模型部分的LR替换为FM,借助FM的显示交叉帮助DNN更好的完成Embedding。不需要预训练FM得到隐向量,不需要人工特征工程,能同时学习低阶和高阶的组合特征; 使用FM取代Wide部分的LR,这样可以避免人工构造复杂的特征工程。
FM模块和Deep模块共享Feature Embedding部分,可以更快的训练,以及更精确的训练学习
Wide&Deep:同时学习低阶和高阶组合特征,它混合了一个线性模型(Wide part)和Deep模型(Deep part)。这两部分模型需要不同的输入,而Wide part部分的输入,依旧依赖人工特征工程。
这是google paly 商店的推荐应用,wide模型和deep模型接受了不同的特征。 deep模型直接接收连续特征和embedding后的离散特征。其输出的即 
![[x,(/img/in-post/20_07/math-20210827140521671)]](/img/in-post/20_07/math-20210827140521671)

wide是简单的线性模型,他会记住训练数据中已经出现的模式,并赋予权重。这代表了记忆 deep是深度的复杂模型,会在一层层的网络中计算出训练数据中未出现的模式的权重。这代表了泛化 这里的模式,可以简单理解为特征组合。
google 2013年提出的经典embedding方法,生成对词的向量表达。
用onehot表示,实际词表很大维度很高,所以需要适当的降维方式将向量稠密化。Word2vec 只关心模型训练完后的副产物——模型参数(这里特指神经网络的权重(输入向量)),并将这些参数,作为输入 x 的某种向量化的表示,这个向量便叫做——词向量。
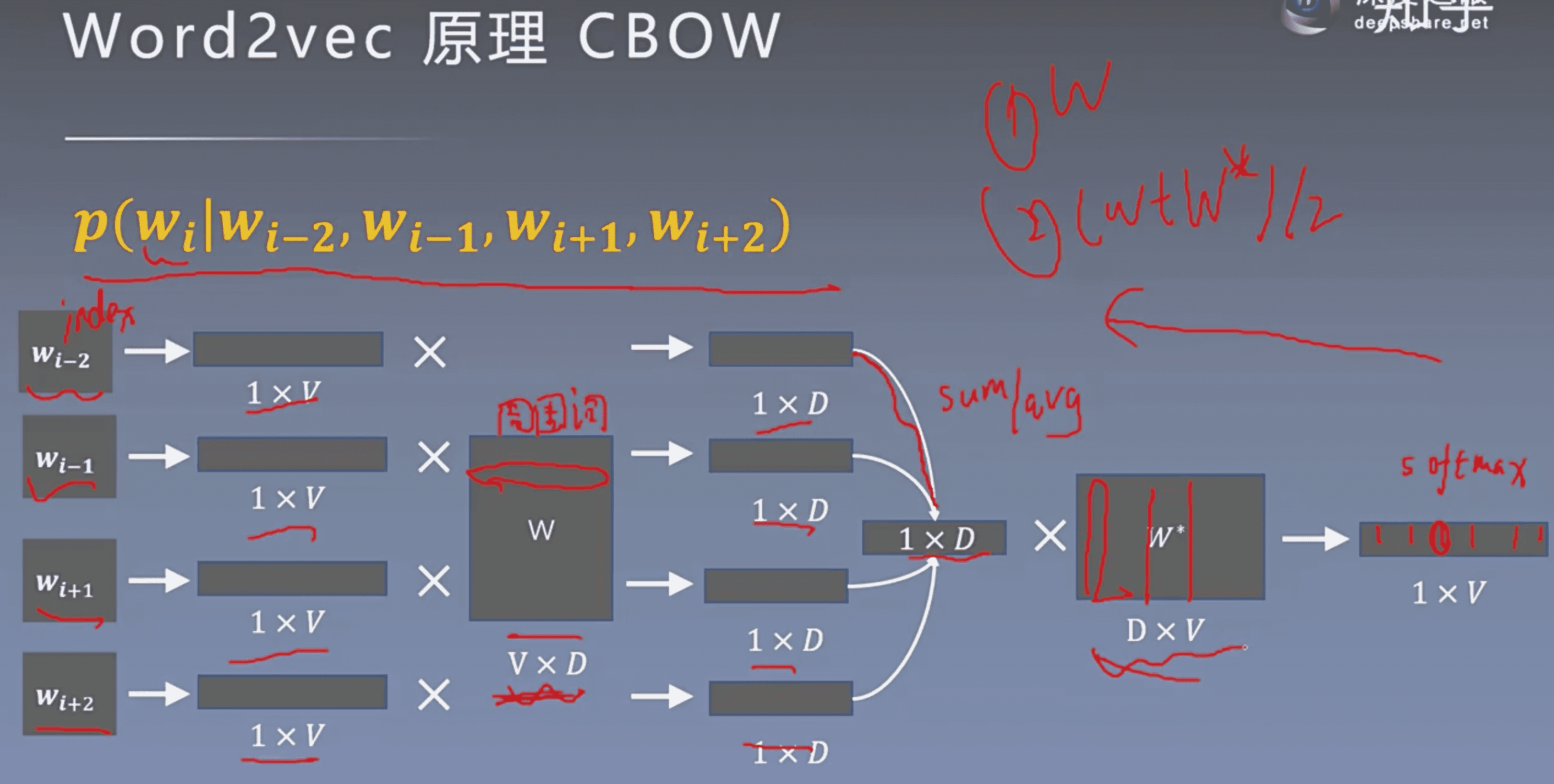
有2种训练模型:Skip-Gram和CBOW。Skip-gram认为每个词决定了相邻的词,所以是由中心词预测周围词,CBOW认为每个词都由相邻的词决定,所以是由周围词预测中心词,一般是用周围词的求和平均预测中心词。
训练样本生成方式:选取滑窗大小,在一个句子中滑动一次即一条训练样本。
因为词意主要由上下文决定,所以联系上下文确定出的词向量的含义更加准确。
🚩 有2种加速训练的方法:层次softmax和负采样。
层次softmax基本思想是:使用Huffman树的结构实现,把softmax转化为多次的sigmoid,复杂度由O(n)变为O(log(n))。
负采样的基本思想是:把多分类问题转化为二分类问题,正样本是(一个中心词和一个周围词),负样本是(一个中心词和一个随机采样的负样本)
负采样: 语料库词太多了,每次迭代更新权重时,都需要计算字典中所有词的预测误差。 负采样只需对采样出的几个负样本(一般小于10)计算预测误差。优化目标退化成一个近似二分类问题。https://zhuanlan.zhihu.com/p/52517050
还有1种优化的技术是:重采样。
模型复杂度上,每次计算所需要的参数:
几个结论 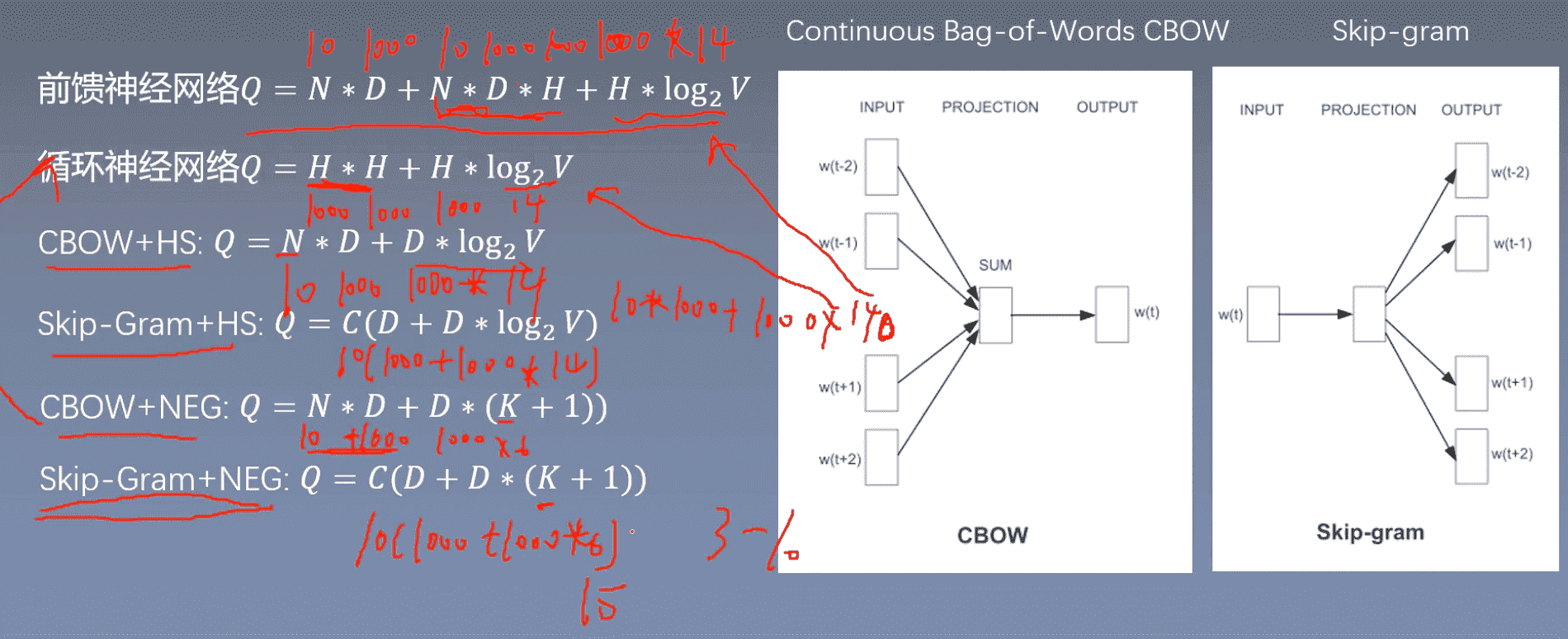
cbow比skip快10倍
主要是反向传播比较花费时间,cbow一共预测V(vocab size)次就够了,复杂度大概是O(V)。skip-gram是O(KV)
cbow和skip都比前馈和循环快
负采样比层次softmax更快(14、15是临界)
模型效果上:
目标函数: 希望所有时间窗口内的样本的条件概率之和最大。(基于极大似然估计) 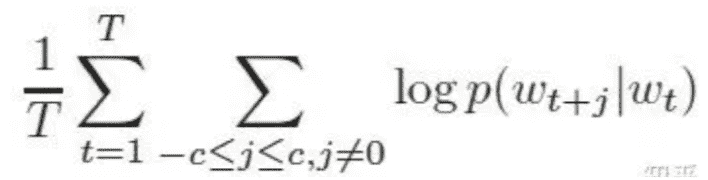
c是窗口大小, 利用梯度下降法则使负的目标函数最小
条件概率的定义: 多分类用softmax函数, 同时用词之间内积距离表示语义的接近程度,所以定义为: 
uw是所有词的周围词的词向量
输入: (doc id,words),得到word Embedding
输入:(user id,itemids),得到item Embedding
用当前词来预测上下文。
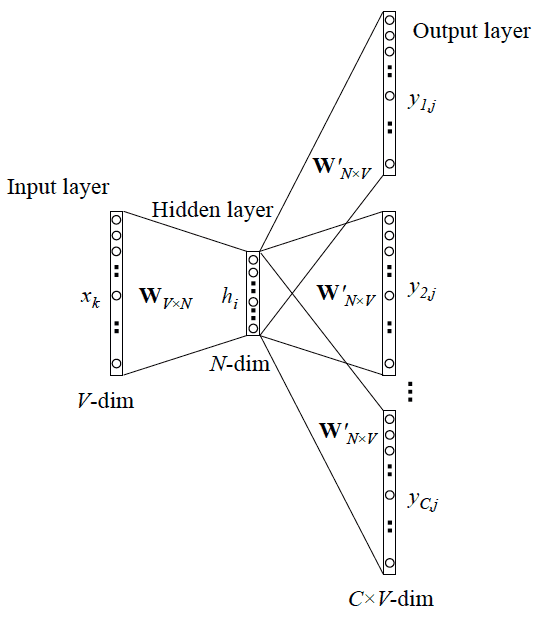
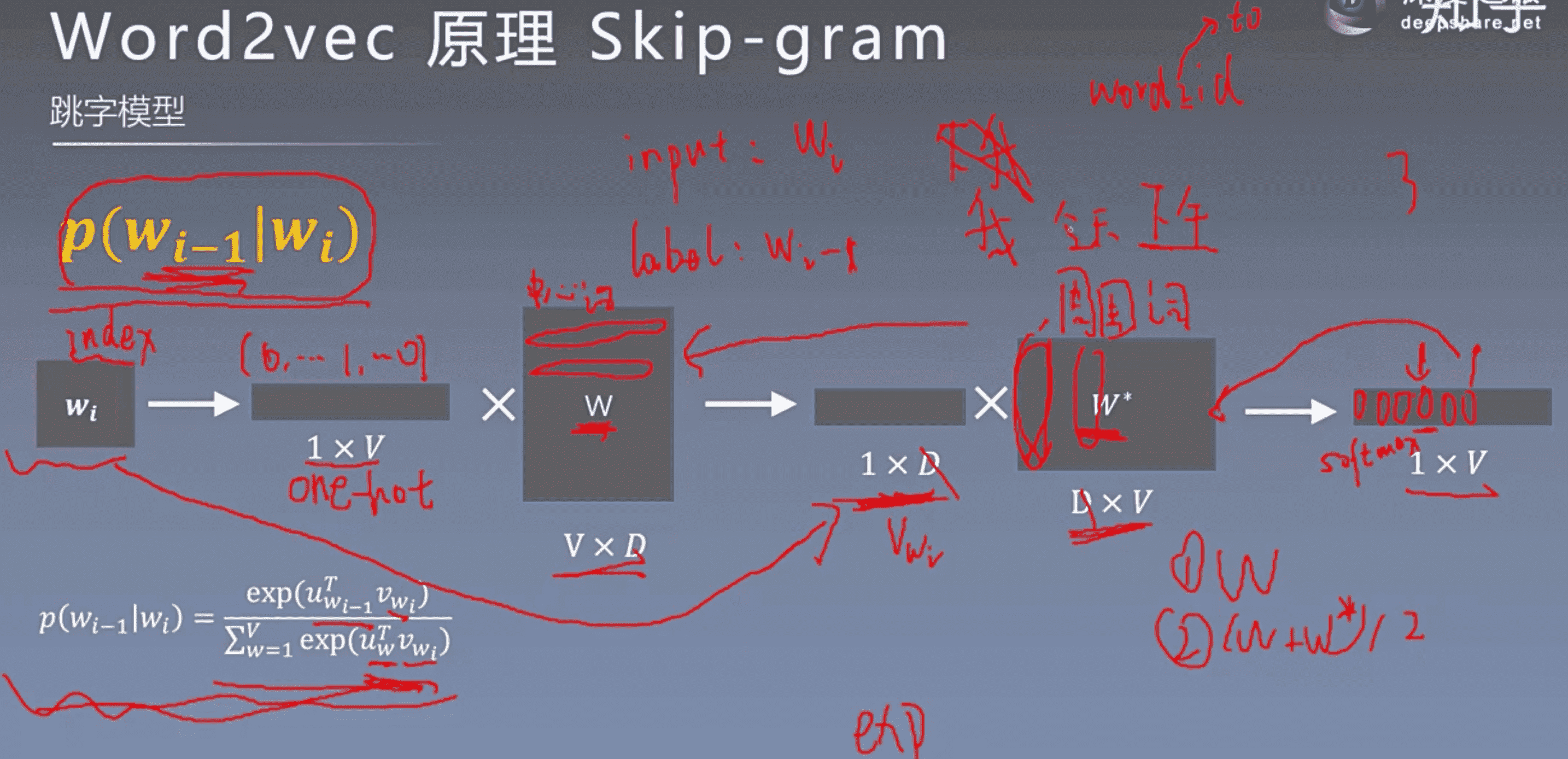

可以看成是 单个x->单个y 模型的并联,cost function 是单个 cost function 的累加(取log之后)
通过上下文来预测当前值。
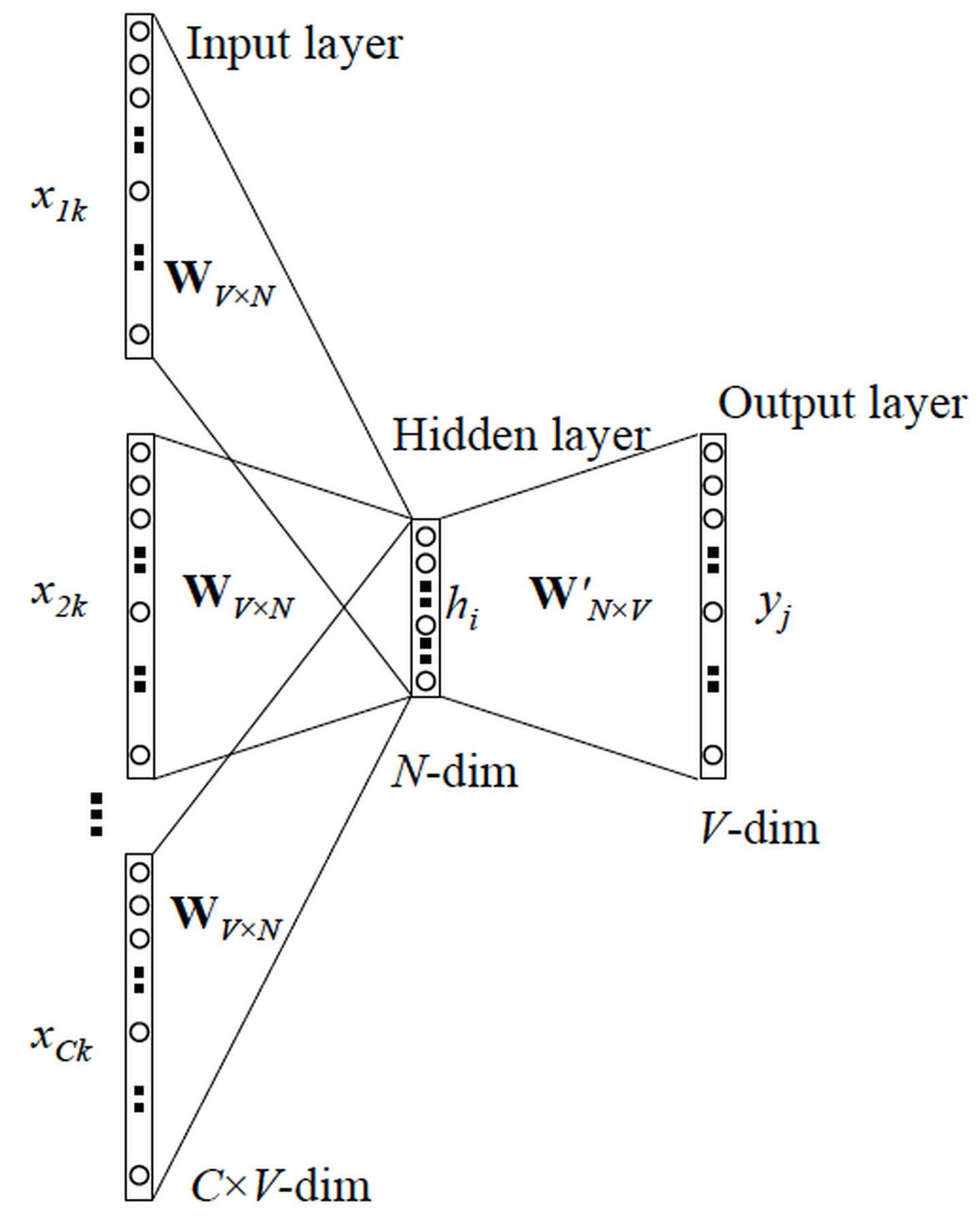
更 Skip-gram 的模型并联不同,这里是输入变成了多个单词,所以要对输入处理下(一般是求和然后平均),输出的 ==cost== function 不变

模型复杂度上,每次计算所需要的参数:
skip-gram
普通skip-gram参数个数: Q = C(D + D * V)
对于每个中心词:中心词向量D,W’的参数:DV,V是词编码维度,周围词个数C 对于每个中心词需要计算的参数的个数为:周围词个数C (中心词向量维度D + 词向量维度D *词编码维度V)
基于层次softmax 的skip-gram参数个数: Q = C(D + D * log2V)
log2V表示基于层次softmax,可以只计算log2V次sigmoid。
基于负采样 的skip-gram参数个数: Q = C(D + D * (K + 1))
(1个正样本+K个负样本)*D维词向量
CBOW训练更快,理论上要快10倍
几个结论
模型效果上:
skip gram的训练时间更长,但是尤其对于一些出现频率不高的词,在CBOW中的学习效果就不如skipgram。反正mikolov自己说的skip准确率比CBOW高
总结来说就是CBOW模型中input是context(周围词)而output是中心词,训练过程中其实是在从output的loss学习周围词的信息也就是embedding,但是在中间层是average的,一共预测V(vocab size)次就够了,复杂度大概是O(V);。
skipgram是用中心词预测周围词,预测的时候是一对word pair,等于对每一个中心词都有K个词作为output,对于一个词的预测有K次,所以能够更有效的从context中学习信息,但是**总共预测K*V次**。时间的复杂度为O(KV)
🚩 但是在skip-gram当中,每个词都要收到周围的词的影响,每个词在作为中心词的时候,都要进行K次的预测、调整。因此, 当数据量较少,或者词为生僻词出现次数较少时, 这种多次的调整会使得词向量相对的更加准确。因为尽管cbow从另外一个角度来说,某个词也是会受到多次周围词的影响(多次将其包含在内的窗口移动),进行词向量的跳帧,但是他的调整是跟周围的词一起调整的,grad的值会平均分到该词上, 相当于该生僻词没有收到专门的训练,它只是沾了周围词的光而已。
从更通俗的角度来说:
在skip-gram里面,每个词在作为中心词的时候,实际上是 1个学生 VS K个老师,K个老师(周围词)都会对学生(中心词)进行“专业”的训练,这样学生(中心词)的“能力”(向量结果)相对就会扎实(准确)一些,但是这样肯定会使用更长的时间;
cbow是 1个老师 VS K个学生,K个学生(周围词)都会从老师(中心词)那里学习知识,但是老师(中心词)是一视同仁的,教给大家的一样的知识。至于你学到了多少,还要看下一轮(假如还在窗口内),或者以后的某一轮,你还有机会加入老师的课堂当中(再次出现作为周围词),跟着大家一起学习,然后进步一点。因此相对skip-gram,你的业务能力肯定没有人家强,但是对于整个训练营(训练过程)来说,这样肯定效率高,速度更快。
在进行最优化的求解过程中:从隐藏层到输出的Softmax层的计算量很大,因为要计算所有词的Softmax概率,再去找概率最大的值。
本质是把 N 分类问题变成 log(N) 次二分类,所以复杂度也从O(n)变成了
把softmax转化为 V个sigmoid
构建huffman树(带权重的路径最短二叉树),只需计算少于log2(V)次的sigmoid,大幅度减少计算
本质是预测总体类别的一个子集。将多分类问题转化为2分类问题。
不同于原本每个训练样本更新所有的权重,负采样每次让一个训练样本仅仅更新一小部分的权重,这样就会降低梯度下降过程中的计算量。 当使用负采样时,我们将随机选择一小部分的negative words(比如选5个negative words)来更新对应的权重。我们也会对我们的“positive” word进行权重更新(在我们上面的例子中,这个单词指的是”quick“)。
一个单词被选作negative sample的概率跟它出现的频次有关,出现频次越高的单词越容易被选作negative words。每个单词被选为“negative words”的概率计算公式与其出现的频次有关, 代码中的公式实现如下:
![[公式]](/img/in-post/20_07/equation-20210827140521676)
每个单词被赋予一个权重f(wi),它代表着单词出现的频次。
因为往往频次高的词不重要,所以要用3/4,使频率小的词概率大一点
文档中的词,出现频率高的信息小,出现频率小的 信息多,比如方法tfidf、BM25就是根据这个思想实现的,在词袋模型里有比较好的效果。
原因:1. 希望更多地训练重要的词对(频率低) 2. 高频词很快就训练好了,低频次需训练很多轮次
方法:训练集中的词w会以 P(wi)的概率被删除:
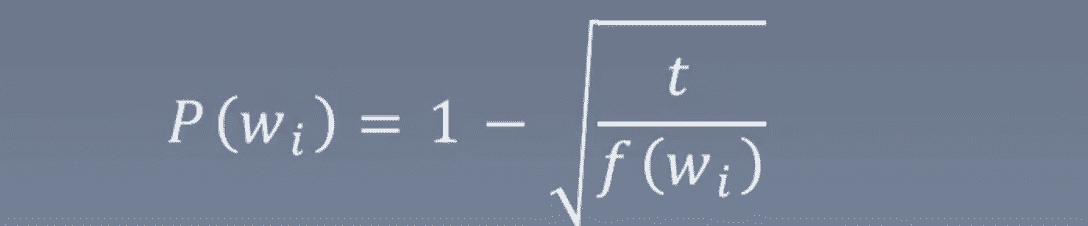
词频越大,P越大;如果词频f小于t(如10**-5),则不会被删除
优点:加速训练,能够得到更好的词向量。
优点:
缺点:
输出层接softmax 函数,隐藏层一般线性激活函数。
最大好处是训练快,
更重要的原因是输入词和预测词,在语料库中往往有共现关系(相邻共同出现)的,用线性激活函数主要保留这层共现关系(训练出来的词大量线性相关🚩)。
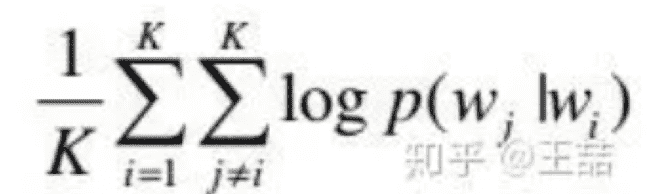
点击预估。
准确的估计 ctr、cvr 对于提高流量的价值,增加广告收入有重要的指导作用。业界常用的方法有人工特征工程 + LR(Logistic Regression)、GBDT(Gradient Boosting Decision Tree) + LR[1][2][3]、FM(Factorization Machine)[2][7]和FFM(Field-aware Factorization Machine)[9]模型。在这些模型中,FM和FFM近年来表现突出,分别在由Criteo和Avazu举办的CTR预测竞赛中夺得冠军[4][5]。
在进行CTR预估时,除了单特征外,往往要对特征进行组合。对于特征组合来说,业界现在通用的做法主要有两大类:FM系列与Tree系列。
旨在解决大规模稀疏数据下的特征组合问题的机器学习模型。
DNN 是 DeepFM 中的一个部分,DeepFM 多一次特征,多一个 FM 层的二次交叉特征
欠拟合:增加deep部分的层数,增加epoch的轮数,增加learningrate,减少正则 化力度
过拟合:在deep层直接增加dropout的率,减少epoch轮数,增加更多的数据,增 加正则化力度,shuffle 数据