TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术,是基于统计特征的关键词提取算法,包含词频TF和逆文本频率指数IDF两部分,字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
就是说,如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,① 则认为此词或者短语,是文章的关键词,② 如果是分类任务,说明具有很好的类别区分能力,适合用来做分类。
TF是词频(Term Frequency)
IDF是逆文本频率指数(Inverse Document Frequency)

具体实现主要分两步:
CountVectorizer类
会将文本中的词语转换为词频矩阵,例如矩阵中包含一个元素a[i][j],它表示j词在i类文本下的词频(个数)。形成一个m类*n维个词的矩阵。
# 通过fit_transform函数计算各个词语出现的次数,
# 通过get_feature_names()可获取词袋中所有文本的关键字,
# 通过toarray()可看到词频矩阵的结果。TfidfTransformer类
用于统计vectorizer中每个词语的TF-IDF值。形成一个m类*n维特征的矩阵。
可用于关键词提取
可以得到每个doc或类别里词的得分,将词进行倒序排序,获取TopK个词作为关键词。
也可提取文本特征+机器学习分类器
直接使用TF-IDF对文本提取特征,并使用分类器进行分类。在分类器的选择上,可以使用SVM、LR、或者XGBoost。
ngram_range # 统计多少个词之间的的特征
max_features # 转化为向量特征长度
可以看出max_features越大模型的精度越高,但是当max_features超过某个数之后,再增加max_features的值对模型精度的影响就不是很显著了。
train_tfidf # Transform 后转化为 样本量特征维度的稀疏矩阵(2000004000) 🚩
优点: 常用于挖掘文章中的关键词,而且算法简单高效,常被工业用于最开始的文本数据清洗。
缺点:
在做文本分类之前,一定会涉及文本的向量化表示。TfidfVectorizer可以把原始文本转化为tf-idf的特征矩阵,从而为后续的文本相似度计算,主题模型(如LSI),文本搜索排序等一系列应用奠定基础。
运用到中文上还需要一些特别的处理介绍:
第一步:分词
采用著名的中文分词库jieba进行分词:
第二步:建模
第三步:参数
CountVectorizer类
会将文本中的词语转换为词频矩阵,例如矩阵中包含一个元素a[i][j],它表示j词在i类文本下的词频(个数)。
# 通过fit_transform函数计算各个词语出现的次数,
# 通过get_feature_names()可获取词袋中所有文本的关键字,
# 通过toarray()可看到词频矩阵的结果。TfidfTransformer类
用于统计vectorizer中每个词语的TF-IDF值。
核心代码:
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
vectorizer=CountVectorizer() #该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
transformer=TfidfTransformer() #该类会统计每个词语的tf-idf权值
tfidf=transformer.fit_transform(vectorizer.fit_transform(corpus)) #第一个fit_transform是计算tf-idf,第二个fit_transform是将文本转为词频矩阵 # coding:utf-8
__author__ = "liuxuejiang"
import jieba
import jieba.posseg as pseg
import os
import sys
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
if __name__ == "__main__":
corpus=["我 来到 北京 清华大学",#第一类文本切词后的结果,词之间以空格隔开
"他 来到 了 网易 杭研 大厦",#第二类文本的切词结果
"小明 硕士 毕业 与 中国 科学院",#第三类文本的切词结果
"我 爱 北京 天安门"]#第四类文本的切词结果
vectorizer=CountVectorizer()#该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
transformer=TfidfTransformer()#该类会统计每个词语的tf-idf权值
tfidf=transformer.fit_transform(vectorizer.fit_transform(corpus))#第一个fit_transform是计算tf-idf,第二个fit_transform是将文本转为词频矩阵
word=vectorizer.get_feature_names()#获取词袋模型中的所有词语
weight=tfidf.toarray()#将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
for i in range(len(weight)):#打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重
print u"-------这里输出第",i,u"类文本的词语tf-idf权重------"
for j in range(len(word)):
print word[j],weight[i][j]TextRank 用于关键词提取的算法流程如下:

可以看出,该公式仅仅比PageRank多了一个权重项Wji,用来表示两个节点之间的边连接有不同的重要程度。考虑到不同词对可能有不同的共现(co-occurrence),TextRank将共现作为无向图边的权值。
d是阻尼系数,防止没有出结点的情况
$$ \sum_{所有进入链接j}\frac{j的权重}{j的出链数量} $$
我们可以看到单词的权重e取决于共现单词的权重。并且与PageRank相比多了一个权重项Wji,用来表示两个节点之间的边连接有不同的重要程度。我们需要运行这个迭代很多时间来获得最终的权重。初始化时,每个单词的重要性为1。
TextRank用于关键词提取
TextRank生成摘要
重要特点是可以脱离语料库的背景,仅对单篇文档进行分析就可以提取该文档的关键词。
RAKE是快速自动关键字提取算法(Rapid Automatic Keyword Extraction algorithm)的简称,是一种独立于域的关键字提取算法,它通过分析文字出现的频率及其与文本中其他词的共现来尝试确定文本主体中的关键短语。
具有相似潜在表征(嵌入)的句子或单词应该具有相似的语义。使用这种方法提取文本关键字的实现是KeyBERT。
首先,使用BERT提取文档向量(嵌入)以获取文档级表示。 然后,针对N元语法词/短语提取词向量。 最后,我们使用余弦相似度来查找与文档最相似的词/短语。 然后,可以将最相似的词识定义为最能描述整个文档的词。
主要有三个部分:单词权重(idf)、单词和文档的相关度(tf)、单词和query(关键词)的相关性。
Okapi BM25:一个非二值的模型
bm25 是一种用来评价搜索词和文档之间相关性的算法,它是一种基于概率检索模型提出的算法。
1.BM25模型
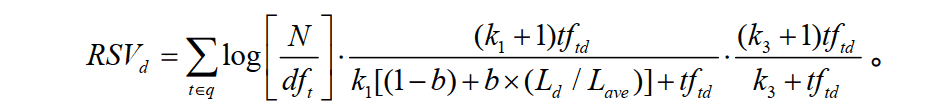
其实,这个公式不难理解,他只有三个部分
1.计算单词权重(idf):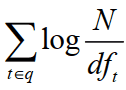
在上面我们已经看到了公式,但是还不是很理解是什么意思,所以这里我们慢慢理解体会: N:是所有的文档数目. dft:是我们的关键词通过倒排算法得出的包含t的文档数目(即为上述例子中,red 在1000个文档中出现的文档次数) 例如,我们在1000个文档中出现red的次数为10,那么N/dft=100,即可算出他的权重。
2.单词和文档的相关度(tf):
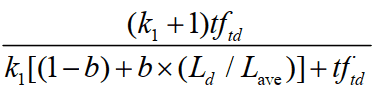
其实,BM25最主要的方面在于 idf*tf,就是查询词的权重*查询词和文档的相关性。
tftd:tftd 是词项 t 在文档 d 中的权重。
Ld 和 Lave :分别是文档 d 的长度及整个文档集中文档的平均长度。
k1:是一个取正值的调优参数,用于对文档中的词项频率进行缩放控制。如果 k 1 取 0,则相当于不考虑词频,如果 k 1取较大的值,那么对应于使用原始词项频率。
b :是另外一个调节参数 (0≤ b≤ 1),决定文档长度的缩放程度:b = 1 表示基于文档长度对词项权重进行完全的缩放,b = 0 表示归一化时不考虑文档长度因素。
3.单词和query(关键词)的相关性:
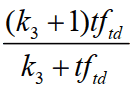
tftq:是词项t在查询q中的权重。
k3: 是另一个取正值的调优参数,用于对查询中的词项tq 频率进行缩放控制。
下面是调用AP90跑出来的数据结果(BM25):
img 同学们可以先了解BIM模型,这是一个较为简单的模型,BM25在很多地方都可以用到。
BM25 是搜索算法中计算权重的一种度量方法,可以理解以 TF-IDF 为基础的一种升级算法,在实际运用中更加灵活和强大,具有更高的实用性。
BM25 在搜索关键词时增加了文档长度与平均长度的比值,以及对比值数的限制,相比 TF-IDF,除了引入长度比值外,BM25 还 normalize 了 TF,可以控制特别高的 TF 对 rank 的影响。
从下图可以看到,文档越短,它逼近上限的速度越快,反之则越慢。 这是可以理解的,对于只有几个词的内容,比如文章标题,只需要匹配很少的几个词,就可以确定相关性。而对于大篇幅的内容,比如一本书的内容,需要匹配很多词才能知道它的重点是讲什么。 🚩??
Okapi BM25
BM25 源自 概率相关模型(probabilistic relevance model) ,而不是向量空间模型
BM25 同样使用词频、逆向文档频率以及字段长归一化,但是每个因子的定义都有细微区别。
非线性词频饱和度
TF/IDF 和 BM25 同样使用 逆向文档频率 来区分普通词(不重要)和非普通词(重要),同样认为(参见 词频 )文档里的某个词出现次数越频繁,文档与这个词就越相关。
不幸的是,普通词随处可见,实际上一个普通词在同一个文档中大量出现的作用会由于该词在 所有 文档中的大量出现而被抵消掉。
曾经有个时期,将 最 普通的词(或 停用词 ,参见 停用词)从索引中移除被认为是一种标准实践,TF/IDF 正是在这种背景下诞生的。TF/IDF 没有考虑词频上限的问题,因为高频停用词已经被移除了。
Elasticsearch 的 standard 标准分析器( string 字段默认使用)不会移除停用词,因为尽管这些词的重要性很低,但也不是毫无用处。这导致:在一个相当长的文档中,像 the 和 and 这样词出现的数量会高得离谱,以致它们的权重被人为放大。
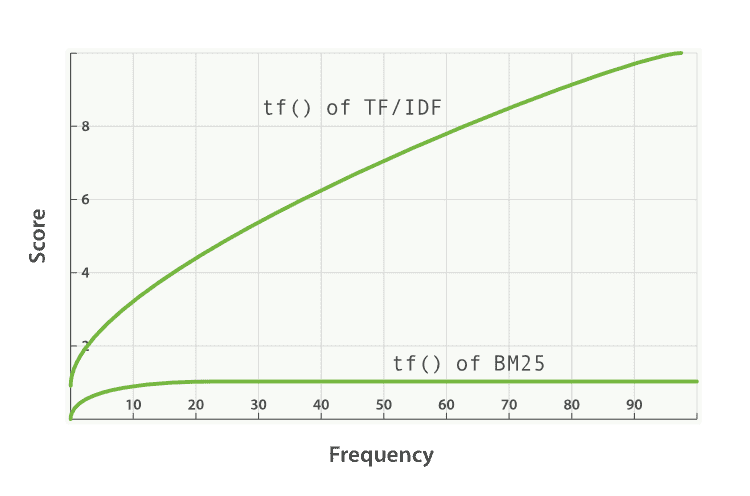
另一方面,BM25 有一个上限,文档里出现 5 到 10 次的词会比那些只出现一两次的对相关度有着显著影响。但是如图 TF/IDF 与 BM25 的词频饱和度 所见,文档中出现 20 次的词几乎与那些出现上千次的词有着相同的影响。 这就是 非线性词频饱和度(nonlinear term-frequency saturation) 。
TF/IDF 与 BM25 的词频饱和度
字段长度归一化(Field-length normalization)
在 字段长归一化 中,我们提到过 Lucene 会认为较短字段比较长字段更重要:字段某个词的频度所带来的重要性会被这个字段长度抵消,但是实际的评分函数会将所有字段以同等方式对待。它认为所有较短的 title 字段比所有较长的 body 字段更重要。
BM25 当然也认为较短字段应该有更多的权重,但是它会分别考虑每个字段内容的平均长度,这样就能区分短 title 字段和 长 title 字段。
在 查询时权重提升 中,已经说过 title 字段因为其长度比 body 字段 自然 有更高的权重提升值。由于字段长度的差异只能应用于单字段,这种自然的权重提升会在使用 BM25 时消失。
BM25 调优
BM25 有一个比较好的特性就是它提供了两个可调参数:
k1 这个参数控制着词频结果在词频饱和度中的上升速度。默认值为 1.2 。值越小饱和度变化越快,值越大饱和度变化越慢。b 这个参数控制着字段长归一值所起的作用, 0.0 会禁用归一化, 1.0 会启用完全归一化。默认值为 0.75 。在实践中,调试 BM25 是另外一回事, k1 和 b 的默认值适用于绝大多数文档集合,但最优值还是会因为文档集不同而有所区别,为了找到文档集合的最优值,就必须对参数进行反复修改验证。
fasttext, word2vec, glove, bert
FastText是入门款的词向量,利用Facebook提供的FastText工具,可以快速构建出分类器。
结构上:类似cbow,
原理是:
第一部分:fastText的模型架构类似于CBOW,两种模型都是基于Hierarchical Softmax,都是三层架构:输入层、 隐藏层、输出层。
第二部分:层次之间的映射。利用了==分层Softmax==
==第三部分:fastText的N-gram特征==
优点:
\1. 速度非常快,并且效果还可以。
\2. 有开源实现,可以快速上手使用。
缺点:
\1. 模型结构简单,所以目前来说,不是最优的模型,效果甚至不如tfidf。
\2. 因为使用词袋思想,所以语义信息获取有限。
FastText其实是对word2vec中 cbow + h-softmax 的灵活使用,其灵活主要体现在两个方面:
两者本质的不同,体现在 h-softmax的使用:
fastText模型的输入是一个词的序列(一段文本或者一句话),输出是这个词序列属于不同类别的概率。
联系:
\1. 都是Log-linear模型,模型非常简单。
\2. 都是对输入的词向量做平均,然后进行 预测。
\3. 模型结构完全一样。
区别:
\1. Fasttext提出的是句子特征,CBOW提出的是上 下文特征。
\2. Fasttext需要标注语料,是监督学习,CBOW不 需要标注语料,是无监督学习。
WordVec是进阶款的词向量,并通过构建深度学习分类完成分类。
深度学习分类的网络结构可以选择TextCNN、TextRNN或者BiLSTM。
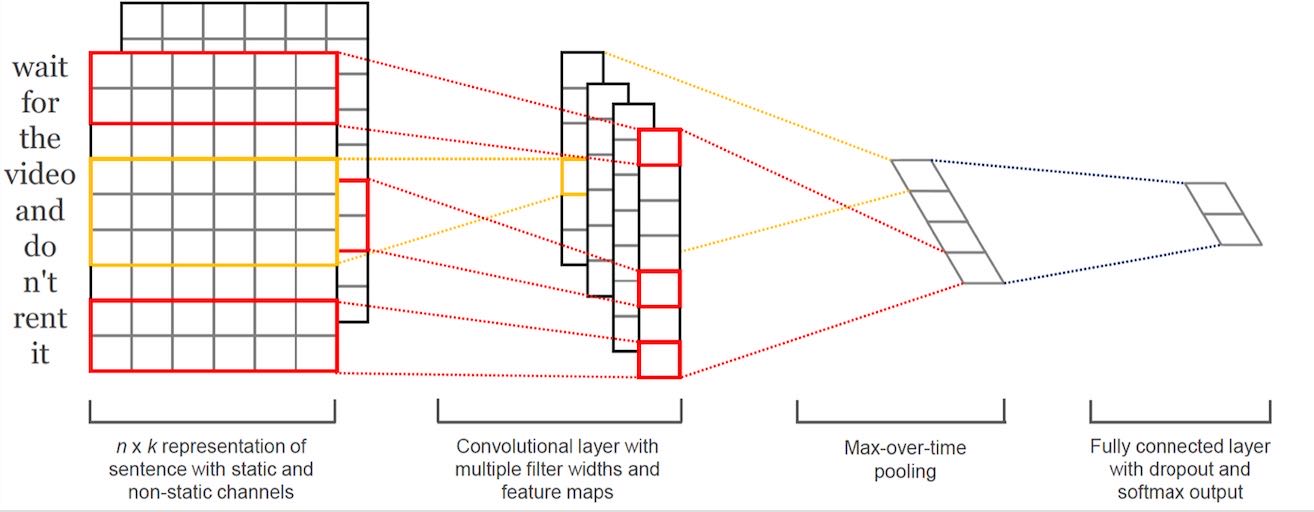
1.1 Embedding layer
输入是一个用预训练好的词向量(Word2Vector或者glove)方法得到的一个Embedding layer。每一个词向量都是通过无监督的方法训练得到的。
词向量拼接起来就得到一个Embedding layer,类似一张二维的图(矩阵)了,利用CNN处理图像的思想进行后续操作。主要说一下不同的地方
1.2卷积(convolution)
相比于一般CNN中的卷积核,这里的卷积核的宽度一般需要和词向量的维度一样,图上的维度是6 。卷积核的高度则是一个超参数可以设置,比如设置为2、3等如图。然后剩下的就是正常的卷积过程了。
1.3池化(pooling)
这里的池化操作是max-overtime-pooling,其实就是在对应的feature map求一个最大值。最后把得到的值做concate。
1.4 优化、正则化
池化层后面加上全连接层和SoftMax层做分类任务,同时防止过拟合,一般会添加L2和Dropout正则化方法。最后整体使用梯度法进行参数的更新模型的优化。
(1)使用预训练的word2vec 、 GloVe初始化效果会更好。一般不直接使用One-hot。
(2)卷积核的大小影响较大,一般取1~10,对于句子较长的文本,则应选择大一些。
(3)卷积核的数量也有较大的影响,一般取100~600 ,同时一般使用Dropout(0~0.5)。
(4)激活函数一般选用ReLU 和 tanh。
(5)池化使用1-max pooling。
(6)随着feature map数量增加,性能减少时,试着尝试大于0.5的Dropout。
(7)评估模型性能时,记得使用==交叉验证==。
预训练词向量方法 — fasttext, word2vec, glove, bert
如何使维度一致来训练模型 — 句子截取和填充
稠密模型,提取出128、256、784维的特征向量。
textCNN 使用卷积的感受也来代替n-gram的作用
两句子分词后词语的交集中词语数与并集中词语数之比。交比并
def sim_jaccard(s1, s2):
"""jaccard相似度"""
s1, s2 = set(s1), set(s2)
ret1 = s1.intersection(s2) # 交集
ret2 = s1.union(s2) # 并集
sim = 1.0 * len(ret1) / len(ret2)
return sim(1)使用词向量表示问句中的每一个单词;
(2)累加求平均词向量得句子的向量表示;
(3)最后计算两向量的余弦距离得相似度。
def sim_vecave(s1, s2):
"""词向量平均后计算余弦距离"""
# 1.分词
s1_list, s2_list = jieba.lcut(s1), jieba.lcut(s2)
# 2.词向量平均得句向量
v1 = np.array([voc[s] for s in s1_list if s in voc])
v2 = np.array([voc[s] for s in s2_list if s in voc])
v1, v2 = v1.mean(axis=0), v2.mean(axis=0)
# 3.计算cosine,并归一化为相似度
sim = cosine(v1, v2)
return sim(1)使用词向量表示问句中的每一个单词;
(2)使用词的idf值对词向量进行加权,按理来说应该使用词的tfidf值进行加权来体现此的重要性程度,由于问句所有词几乎都出现一次,所以使用idf和使用tfidf是等价的;
(3)累加求平均词向量得句子的向量表示;
(4)最后计算两向量的余弦距离得相似度。
def sim_vecidf(self, s1, s2):
"""词向量通过idf加权平均后计算余弦距离"""
v1, v2 = [], []
# 1. 词向量idf加权平均
for s in jieba.cut(s1):
idf_v = idf.get(s, 1)
if s in voc:
v1.append(1.0 * idf_v * voc[s])
v1 = np.array(v1).mean(axis=0)
for s in jieba.lcut(s2):
idf_v = idf.get(s, 1)
if s in voc:
v2.append(1.0 * idf_v * voc[s])
v2 = np.array(v2).mean(axis=0)
# 2. 计算cosine
sim = self.cosine(v1, v2)
return sim词袋模型的优势有:… (见下)
cicada实习的时候因为有人在用bert比如DPR在做,所以我主要是用一些机器学习方法在做,也是希望可以快速迭代测试某些方法和尝试的效果。
huawei实习和kaggle多模态:bm25,基于概率统计的模型,还是白盒模型,不像Embedding,也更容易调试。 像这种商品标题信息,更在意空间距离,而其实少一些语义距离,然而想bm25这种统计概率模型就更关注于物料的空间距离。像之前kaggle用的就是tfidf和bm25,效果已经做够好了,单模型甚至比bert要好些。
将自然语言文本的每个词作为一个特征。因此对应的特征向量即这些特征的组合。这种思路虽然朴素,但是很有效。基于这种思想的模型就是词袋模型(Bag of Words),也叫向量空间模型(Vector Space Model)。
在最近的NLP领域中,主要有两种方式:
特征维数等问题可以通过一些参数解决。maxfeatures,ngram
二. 何时词袋模型比词嵌入更具优势?
实际上,在某些情况下,词袋模型会表现地更好。在以下情况下,您更倾向使用词袋模型而不是词嵌入:
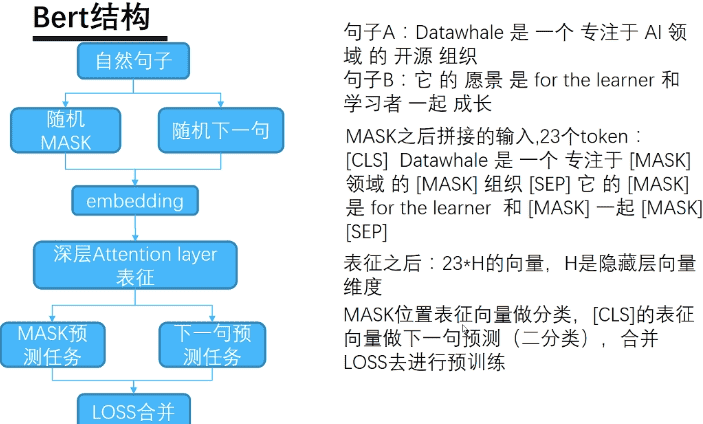
在论文原文中,作者提出了两个预训练任务:Masked LM 和 Next Sentence Prediction。
意义:BERT是一个无监督的NLP预训练模型,这个模型的最大意义是使得NLP任务可以向CV一样使用预训练模型,这极大的方便了一个新的任务开始,因为在NLP领域,海量数据的获取还是有难度的。
模型结构:主要有三部分构成:Embedding + Transformer Encoder + Loss优化
Transformer的编码部分:,每个block主要由 ①多头self-Attention、 ②标准化(Norm)、 ③残差连接、 ④Feed Fordawrd组成。
具体任务中:主要分为模型预训练和模型微调两个阶段。
预训练方式:设计了两个任务来预训练该模型。
Masked LM: 在BERT中, Masked LM(Masked language Model) 构建了语言模型, 这也是BERT的预训练中任务之一, 简单来说, 就是随机遮盖或替换一句话里面任意字或词, 然后让模型通过上下文的理解预测那一个被遮盖或替换的部分, 之后做loss的时候只计算被遮盖部分的ss
Next Sentence Predict(NSP): 首先我们拿到属于上下文的一对句子, 也就是两个句子, 之后我们要在这两段连续的句子里面加一些特殊token: [𝑐𝑙𝑠][cls]上一句话,[𝑠𝑒𝑝][sep]下一句话[𝑠𝑒𝑝][sep]。
优点:
缺点就是:
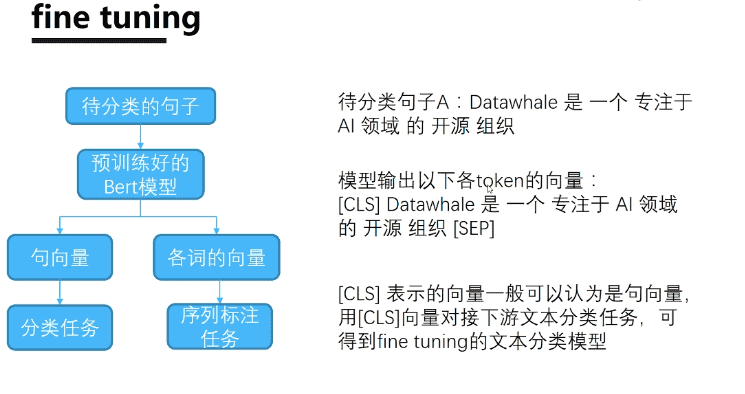
二、模型结构
其实概括一下,Bert主要有三部分构成:Embedding + Transformer Encoder + Loss优化
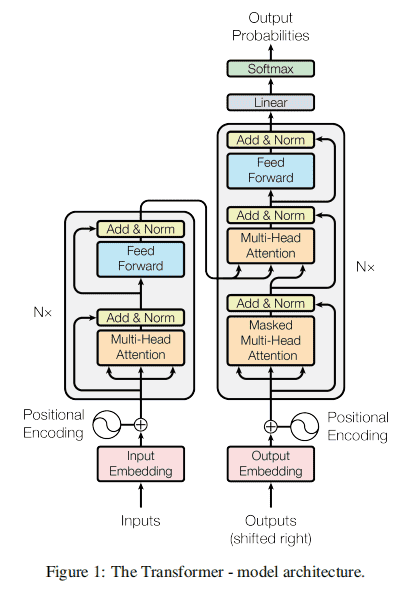
上图左侧为Transformer的编码部分,右侧为Transformer的解码部分。
左侧的编码部分包括输入,添加位置编码,以self-Attention、Add&Norm、Feed Fordward的block。下面就每个具体细节进行具体分析。
2. 位置编码
位置编码是用来捕获文本之间的时序关联性的,
当对NLP文本处理时,位置更近的文本一般相关性更大,所以将位置编码融入到数据中是很有必要的。
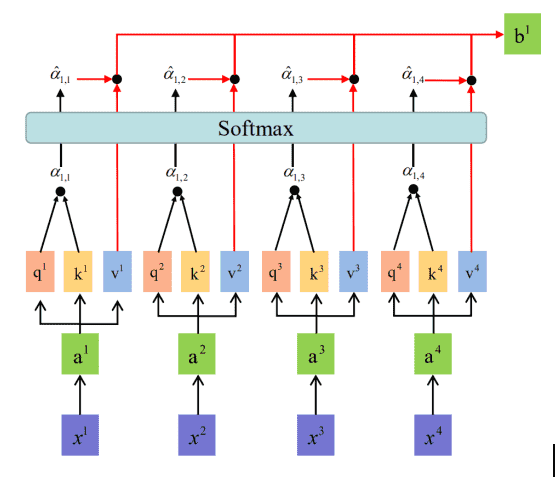
3. self-Attention
self-attention是BERT的重要思想,其与位置编码结合,解决了文本数据的时序相关性的问题
attention模型是经过训练,当不同信息传入时,自动的调整权重的一种结构。
4. 残差连接
残差连接是训练深层模型时惯用的方法,主要是为了避免模型较深时,在进行反向传播时,梯度消失等问题。具体实现时,当网络进行前向传播时,不仅仅时按照网络层数进行逐层传播,还会由当前层隔一层或多层向前传播,如下图所示:
5. 模型实现
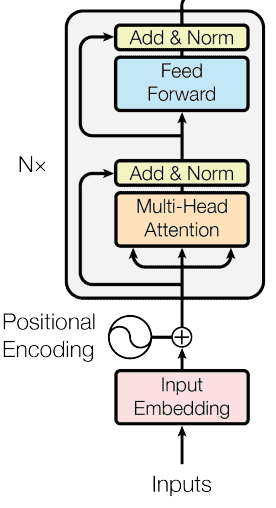
以上是BERT的整体结构,Input输入的是文本数据,经过Embedding加上位置向量Positional Encoding。Multi-Head Atention为多头的self-Attention,实际上就是将self-attention的Q、K、V均分成n份,分别进行计算。Add&Norm为残差计算和标准化;Feedward为全连接层,进行前向传播。其中𝑁𝑥Nx为基本单元的个数,是可以条调整的超参数。
6. Bert模型预训练策略
在预训练Bert模型时,论文提供了两种策略:
(1) Masked LM
在BERT中, Masked LM(Masked language Model)构建了语言模型, 这也是BERT的预训练中任务之一, 简单来说, 就是随机遮盖或替换一句话里面任意字或词, 然后让模型通过上下文的理解预测那一个被遮盖或替换的部分, 之后**做loss的时候只计算被遮盖部分的loss,
(2) Next Sentence Predict(NSP)
首先我们拿到属于上下文的一对句子, 也就是两个句子, 之后我们要在这两段连续的句子里面加一些特殊token:[𝑐𝑙𝑠][cls]上一句话,[𝑠𝑒𝑝][sep]下一句话[𝑠𝑒𝑝][sep]。
https://cloud.tencent.com/developer/article/1687276
BERT 模型的主要输入是文本中各个字/词(或者称为 token)的原始词向量,该向量既可以随机初始化,也可以利用 Word2Vector 等算法进行预训练以作为初始值;输出是文本中各个字/词融合了全文语义信息后的向量表示,如下图所示(为方便描述且与 BERT 模型的当前中文版本保持一致,统一以「字向量」作为输入)
Sentence-Transformer(sbert)官方文档
Sentence-Transformer的使用及fine-tune教程
从两种情况来介绍如何使用Sentence-Transformer:
pip install -U sentence-transformers
pip install -U transformersSentence-Transformer提供了非常多的预训练模型供我们使用,对于文本相似度(Semantic Textual Similarity)任务来说,比较好的模型有以下几个:
roberta-large-nli-stsb-mean-tokens - STSb performance: 86.39 roberta-base-nli-stsb-mean-tokens - STSb performance: 85.44 bert-large-nli-stsb-mean-tokens - STSb performance: 85.29 distilbert-base-nli-stsb-mean-tokens - STSb performance: 85.16
这里我就选择最好的模型做一下语义文本相似度任务
语义文本相似度任务指的是给定一个句子(query),在整个语料库中寻找和该句子语义上最相近的几个句子
用一个list来代表整个语料库,list中存的是str类型的句子
给定一个句子sentence,可以得到一个句子的向量表示embeddings
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('roberta-large-nli-stsb-mean-tokens')
sentences = ['Lack of saneness',
'Absence of sanity',
'A man is eating food.',
'A man is eating a piece of bread.',
'The girl is carrying a baby.',
'A man is riding a horse.',
'A woman is playing violin.',
'Two men pushed carts through the woods.',
'A man is riding a white horse on an enclosed ground.',
'A monkey is playing drums.',
'A cheetah is running behind its prey.']
sentence_embeddings = model.encode(sentences)
for sentence, embedding in zip(sentences, sentence_embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding)
print("")query = 'Nobody has sane thoughts' # A query sentence uses for searching semantic similarity score.
queries = [query]
query_embeddings = model.encode(queries)import scipy
print("Semantic Search Results")
number_top_matches = 3
for query, query_embedding in zip(queries, query_embeddings):
distances = scipy.spatial.distance.cdist([query_embedding], sentence_embeddings, "cosine")[0]
results = zip(range(len(distances)), distances)
results = sorted(results, key=lambda x: x[1])
print("Query:", query)
print("\nTop {} most similar sentences in corpus:".format(number_top_matches))
for idx, distance in results[0:number_top_matches]:
print(sentences[idx].strip(), "(Cosine Score: %.4f)" % (1-distance))distance表示两个句子的余弦距离,1 − distance 可以理解为两个句子的余弦分数(余弦相似度),分数越大表示两个句子的语义越相近
Fine-Tune仍然是STS任务,我使用的数据集是query词对,
负样本:不同类query
首先读取数据
以下是构建数据集的代码
from sentence_transformers import SentenceTransformer, SentencesDataset, InputExample, evaluation, losses
from torch.utils.data import DataLoader
train_size = int(len(Ko_list) * 0.8)
eval_size = len(Ko_list) - train_size
# Define your train examples.
train_data = []
for idx in range(train_size):
train_data.append(InputExample(texts=[Ko_list[idx], Cn_list[idx]], label=1.0))
train_data.append(InputExample(texts=[shuffle_Ko_list[idx], shuffle_Cn_list[idx]], label=0.0))
# Define your evaluation examples
sentences1 = Ko_list[train_size:]
sentences2 = Cn_list[train_size:]
sentences1.extend(list(shuffle_Ko_list[train_size:]))
sentences2.extend(list(shuffle_Cn_list[train_size:]))
scores = [1.0] * eval_size + [0.0] * eval_size
evaluator = evaluation.EmbeddingSimilarityEvaluator(sentences1, sentences2, scores)
# Define your train dataset, the dataloader and the train loss
train_dataset = SentencesDataset(train_data, model)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=32)
train_loss = losses.CosineSimilarityLoss(model)Sentence-Transformer在fine-tune的时候,数据必须保存到list中,list里是Sentence-Transformer库的作者自己定义的InputExample()对象
InputExample()对象需要传两个参数texts和label,其中,texts也是个list类型,里面保存了一个句子对,label必须为float类型,表示这个句子对的相似程度
([-1,1])比方说下面的示例代码
train_examples = [InputExample(texts=['My first sentence', 'My second sentence'], label=0.8), InputExample(texts=['Another pair', 'Unrelated sentence'], label=0.3)]
然后定义模型开始训练,
output_path#Define the model. Either from scratch of by loading a pre-trained model
model = SentenceTransformer('distiluse-base-multilingual-cased')
# Tune the model
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=1, warmup_steps=100, evaluator=evaluator, evaluation_steps=100, output_path='./Ko2CnModel')如果要加载模型做测试,使用如下代码即可
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('./Ko2CnModel')
# Sentences are encoded by calling model.encode()
emb1 = model.encode("터너를 이긴 푸들.")
emb2 = model.encode("战胜特纳的泰迪。")
cos_sim = util.pytorch_cos_sim(emb1, emb2)
print("Cosine-Similarity:", cos_sim)https://cloud.tencent.com/developer/article/1542897
模型轻量化
模型轻量化是业界一直在探索的一个课题,尤其是当你使用了BERT系列的预训练语言模型,inference速度始终是个绕不开的问题,而且训练平台可能还会对训练机器、速度有限制,训练时长也是一个难题。
目前业界上主要的轻量化方法如下:
蒸馏:将大模型蒸馏至小模型,思路是先训练好一个大模型,输入原始数据得到logits作为小模型的soft label,而原始数据的标签则为hard label,使用soft label和hard label训练小模型,旨在将大模型的能力教给小模型。
剪枝:不改变模型结构,减小模型的维度,以减小模型量级。
量化:将高精度的浮点数转化为低精度的浮点数,例如4-bit、8-bit等。
OP重建:合并底层操作,加速矩阵运算。
低秩分解:将原始的权重张量分解为多个张量,并对分解张量进行优化。
我们团队对这些轻量化方法都进行了尝试,简单总结如下:
蒸馏:可以很好地将大模型的能力教给小模型,将12层BERT蒸馏至2层BERT,可以达到非常接近的效果。但这种方法需要先训练出一个大模型。
剪枝:速度有非常显著的提升,结合蒸馏,可以达到很好的效果;即使不结合蒸馏,也能达到不错的效果。
量化:主要用于模型压缩,可以将大文件压缩成小文件存储,方便部署于移动端,但是在速度上无明显提升。
OP重建:有明显加速功能,但是操作较为复杂,需要修改底层C++代码。
低秩分解:基于PCA算法,有一倍多的加速作用,但是效果也下降了许多。
在这些方法中,剪枝显得非常简单又高效,如果你想快速得对BERT模型进行轻量化,不仅inference快,还希望训练快,模型文件小,效果基本维持,那么剪枝将是一个非常好的选择,本文将介绍如何为BERT系列模型剪枝,并附上代码,教你十分钟剪枝。