(l+r)//2。def binary_search(nums:List[int], target:int):
l, r = 0, len(nums)-1
while l <= r:
mid = (l+r)//2
if nums[mid] < target:
l = mid + 1
elif nums[mid] > target:
r = mid - 1
elif nums[mid] == target:
return l
return -1def left_bound(nums:List[int], target:int):
l, r = 0, len(nums)-1
while l <= r:
mid = (l+r)//2
if nums[mid] < target:
l = mid + 1
elif nums[mid] > target:
r = mid - 1
elif nums[mid] == target:
r = mid - 1
if l > len(nums)-1 or nums[l] != target:
return -1
return ldef right_bound(nums:List[int], target:int):
l, r = 0, len(nums)-1
while l <= r:
mid = (l+r)//2
if nums[mid] < target:
l = mid + 1
elif nums[mid] > target:
r = mid - 1
elif nums[mid] == target:
l = mid + 1
if r < 0 or nums[r] != target:
return -1
return rdp = [[0] * len(s2) for _ in range(len(s1))] # 注意:是先j后i
# 确定 base case
dp[0][0][...] = base case
# 确定 状态
for 状态1 in 状态1的取值:
for 状态2 in 状态2的取值:
# 确定 选择
# 确定 状态转移方程
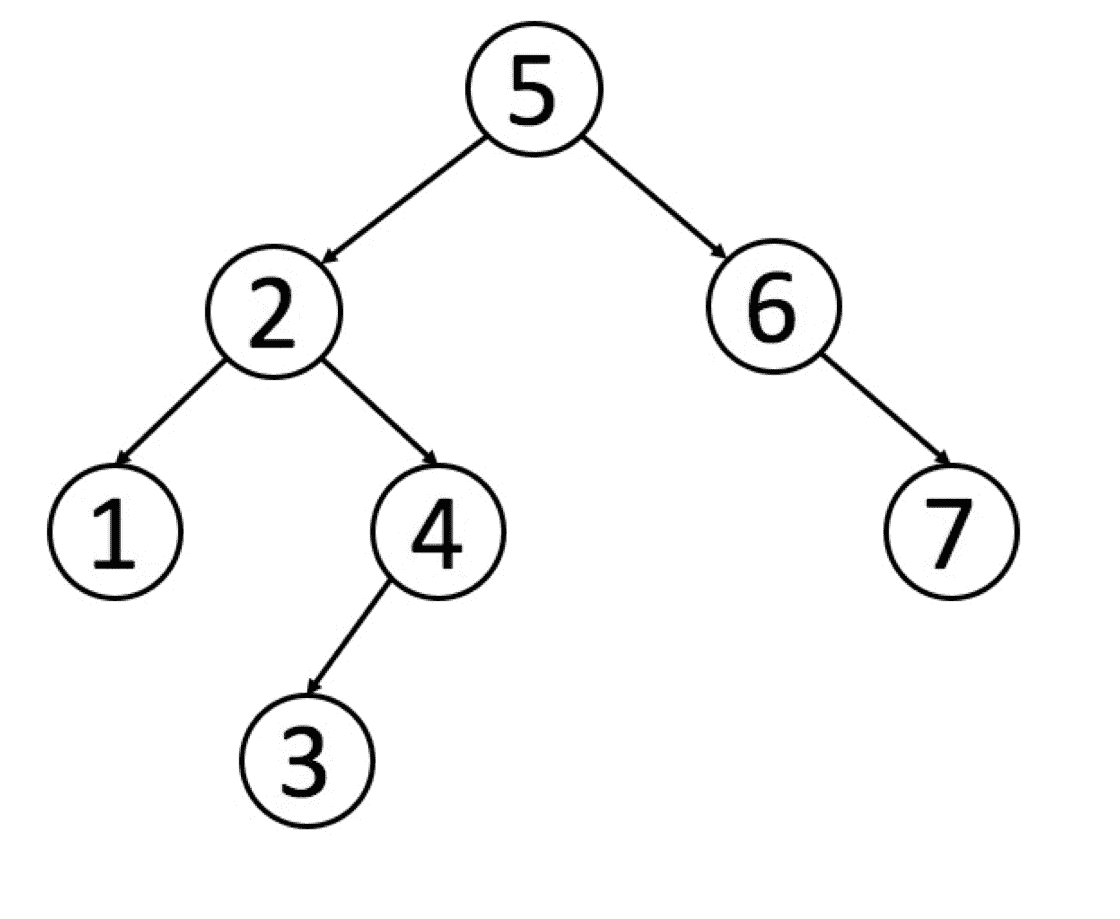
dp[状态1][状态2][...] = 求最值(选择1,选择2,...)class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
def traverse(root) :
if not root: return None
# 节点 需要做什么在这里做, 其他的交给框架
# 你的任务
# 前序遍历位置
traverse(root.left)
# 中序遍历位置
traverse(root.right)
# 后序遍历位置/* 基本的二叉树节点 */
class TreeNode {
int val;
TreeNode left, right;
}
void traverse(TreeNode root) {
// 前序遍历位置
traverse(root.left)
// 中序遍历位置
traverse(root.right)
// 后序遍历位置
}def binaryTreePaths(self, root: TreeNode) -> List[str]:
if not root: return []
ans = []
path = ''
def dfs(root, path):
if root:
# do sth
path+=str(root.val)
# 满足条件
if not(root.left or root.right):
ans.append(path)
# 不满足继续循环
else:
path += '->'
dfs(root.left, path)
dfs(root.right, path)
dfs(root,path)
return ans
class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
def BST(root:TreeNode, target:int):
if root.val == target:
# do something
if root.val > target:
BST(root.left, target)
if root.val < target:
BST(root.right, target)/* 基本的二叉树节点 */
class TreeNode {
int val;
TreeNode left, right;
}
void BST(TreeNode root, int target) {
if (root.val == target)
// 找到目标,做点什么
if (root.val < target)
BST(root.right, target);
if (root.val > target)
BST(root.left, target);
} class TreeNode:
def __init__(self, val, children):
self.val = val
self.children = chrildren
def traverse(root:TreeNode):
for child in root.children:
traverse(child)/* 基本的 N 叉树节点 */
class TreeNode {
int val;
TreeNode[] children;
}
void traverse(TreeNode root) {
for (TreeNode child : root.children)
traverse(child)
}visited 标记以防止重复访问。class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
def traverse(head):
p = head
while p:
# 迭代访问 p.val
p = p.next
def traverse(head):
# 递归访问 head.val
traverse(head.next)/* 基本的单链表节点 */
class ListNode {
int val;
ListNode next;
}
void traverse(ListNode head) {
for (ListNode p = head; p != null; p = p.next) {
// 迭代访问 p.val
}
}
void traverse(ListNode head) {
// 递归访问 head.val
traverse(head.next)
}def backtrack(选择列表, path):
if 满足结束条件:
result.add(path)
return
for 选择 in 选择列表:
path.append(选择)
backtrack(选择列表, path)
path.pop()
result = []
path = []
backtrack(选择列表, path)
return resultdef DFS(选择列表, path):
if 满足结束条件:
result.add(path)
return
visited.add(start)
for 选择 in 选择列表:
path.append(选择)
backtrack(选择列表, path)
path.pop()
visited.remove(start)
visited = set()
result = []
path = []
DFS(选择列表, path)
return resultdef dfs(root, targetSum):
if not root:
return # 注意 return
path.append(root.val) # 添加路径
targetSum -= root.val
if not root.left and not root.right and targetSum == 0: # 如果满足条件
res.append(path[:])
dfs(root.left, targetSum)
dfs(root.right, targetSum)
path.pop() # 注意要 去掉路径
res = []
path = []
dfs(root,targetSum)
return resdef BFS(start, target):
q = []
visited = {}
q.append(start) # 队列queue
visited.add(start) # 像二叉树一样的结构,没有子节点到父节点的指针,不会走回头路,就不需要visited
step = 0
while q:
for _ in range(len(queue)):
cur = q.pop(0) # Notice is 0
if cur is target:
return step
for x in cur.adj(): # 将 cur 的相邻节点加⼊队列
if x not in visited:
q.append(x)
visited.add(x)
step += 1 # 遍历完一层后step++
// 计算从起点 start 到终点 target 的最近距离
int BFS(Node start, Node target) {
Queue<Node> q; // 核⼼数据结构
Set<Node> visited; // 避免⾛回头路
q.offer(start); // 将起点加⼊队列
visited.add(start);
int step = 0; // 记录扩散的步数
while (q not empty) {
int sz = q.size();
/* 将当前队列中的所有节点向四周扩散 */
for (int i = 0; i < sz; i++) {
Node cur = q.poll();
/* 划重点:这⾥判断是否到达终点 */
if (cur is target)
return step;
/* 将 cur 的相邻节点加⼊队列 */
for (Node x : cur.adj())
if (x not in visited) {
q.offer(x);
visited.add(x);
}
}
/* 划重点:更新步数在这⾥ */
step++;
}
}slow = fast = head
while fast and fast.next:
slow = slow.next
fast = fast.next.next
if fast == slow:
return True基本原理:使用滑动窗口的方式将枚举的时间复杂度从 O(N2) 减少至 O(N)。
为什么是 O(N) 呢?这是因为在枚举的过程每一步中,「左指针」会向右移动一个位置(也就是题目中的 b),而「右指针」会向左移动若干个位置,这个与数组的元素有关,但我们知道它一共会移动的位置数为 O(N),均摊下来,每次也向左移动一个位置,因此时间复杂度为 O(N)。
参考链接:https://leetcode-cn.com/problems/3sum/solution/san-shu-zhi-he-by-leetcode-solution/
出题形式:当我们需要枚举数组中的两个元素时,如果我们发现随着第一个元素的递增,第二个元素是递减的,那么就可以使用双指针的方法。
算法框架:
def slidingWindow(s:str, t:str):
need = set(c)
window = set()
left, right = 0, 0
valid = 0 # 注意
while right < len(s):
# 增大窗口
c = s[right]
window.add(s[right])
right += 1
print("window:", left, right)
while ...: # window needs shrink
# 缩小窗口
d = s[left]
window.remove(s[left])
left += 1基本原理:
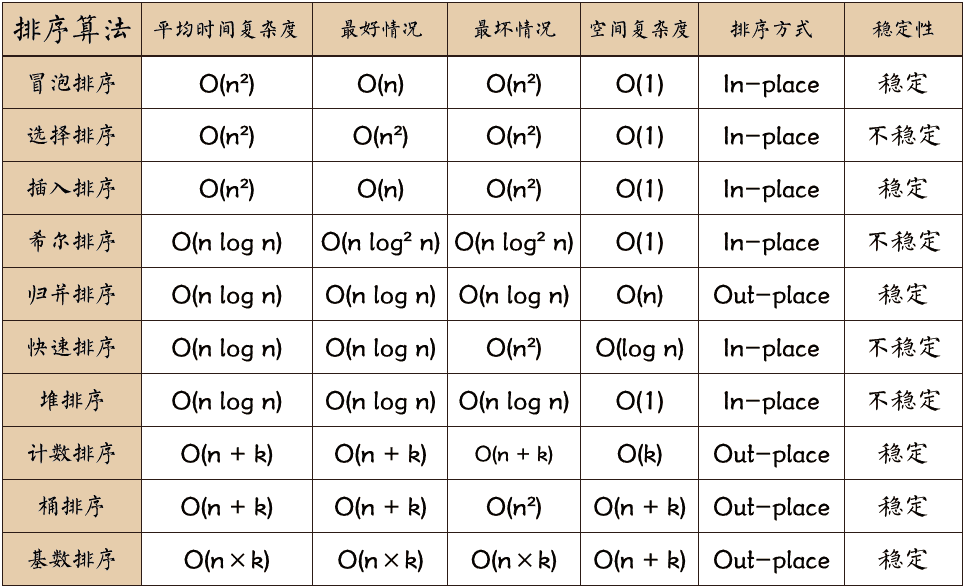
出题形式:需要重点掌握快速排序、归并排序、插入排序和冒泡排序。
def bubbleSort(nums):
for i in range(len(nums)):
# Last i elements are already in place
for j in range(len(nums)-i-1):
if nums[j] > nums[j+1]:
nums[j], nums[j+1] = nums[j+1], nums[j]class Solution:
def sortArray(self, nums: List[int]) -> List[int]:
for ind in range(1,len(nums)):
i = ind
while i > 0 and nums[i] < nums[i-1]:
nums[i], nums[i-1] = nums[i-1], nums[i]
i -= 1
return nums# 使用heapq返回topk个数示例
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
counter = collections.Counter(nums)
h = []
for key, val in counter.items():
heapq.heappush(h, (val, key))
if len(h) > k:
heapq.heappop(h)
return [x[1] for x in h]heapq库使用参考链接:https://blog.csdn.net/brucewong0516/article/details/79042839
heappush(heap,n)数据堆入
heappop(heap)将数组堆中的最小元素弹出
heapify(heap) 将heap属性强制应用到任意一个列表
heapify 函数将使用任意列表作为参数,并且尽可能少的移位操作,,将其转化为合法的堆。如果没有建立堆,那么在使用heappush和heappop前应该使用该函数。
heapreplace(heap,n)弹出最小的元素被n替代
nlargest(n,iter)、nsmallest(n,iter)
heapq中剩下的两个函数nlargest(n.iter)和nsmallest(n.iter)分别用来寻找任何可迭代的对象iter中第n大或者第n小的元素。可以通过使用排序(sorted函数)和分片进行完成。
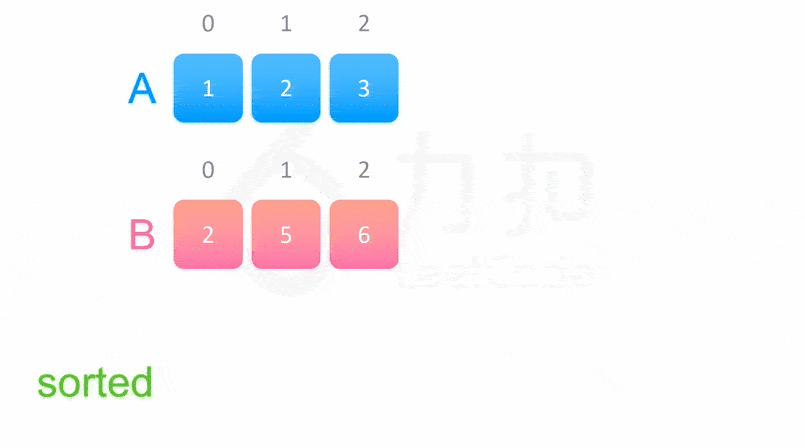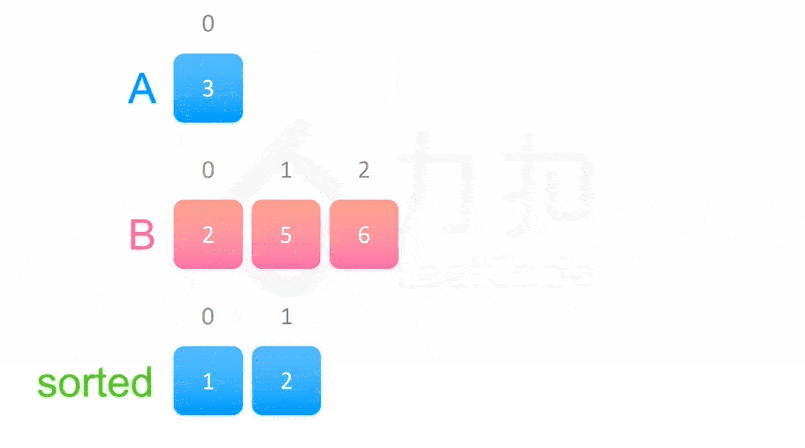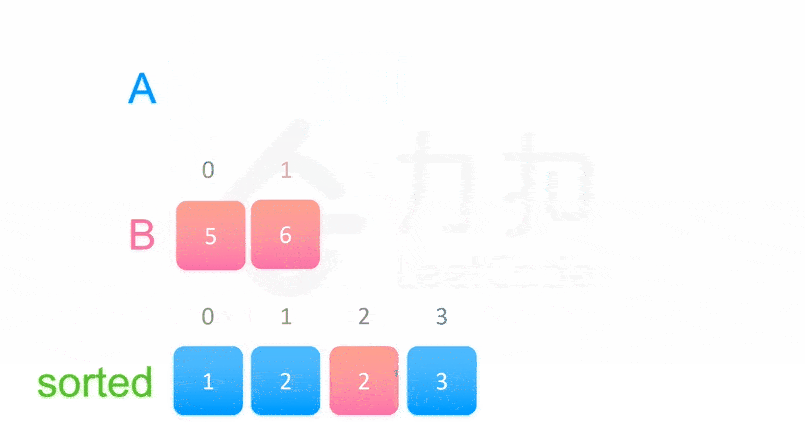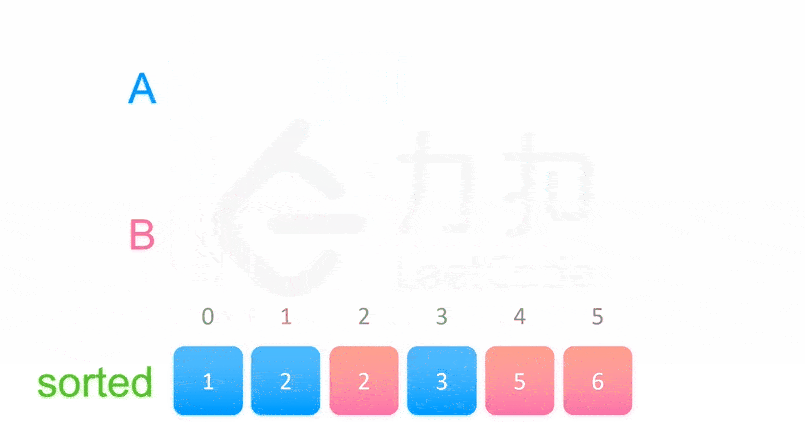
class Solution:
def merge_sort(self, nums, l, r):
if l == r:
return
mid = (l + r) // 2
self.merge_sort(nums, l, mid)
self.merge_sort(nums, mid + 1, r)
# 两个有序列表的归并
tmp = []
i, j = l, mid + 1
while i <= mid or j <= r:
if i > mid or (j <= r and nums[j] < nums[i]):
tmp.append(nums[j])
j += 1
else:
tmp.append(nums[i])
i += 1
nums[l: r + 1] = tmp
def sortArray(self, nums: List[int]) -> List[int]:
self.merge_sort(nums, 0, len(nums) - 1)
return nums算法解释:定义
mergeSort(nums, l, r)函数表示对 nums 数组里 [l,r] 的部分进行排序,整个函数流程如下:
- 递归调用函数
mergeSort(nums, l, mid)对 nums 数组里 [l,mid] 部分进行排序。- 递归调用函数
mergeSort(nums, mid + 1, r)对 nums 数组里 [mid+1,r] 部分进行排序。- 此时 nums 数组里 [l,mid] 和 [mid+1,r] 两个区间已经有序,我们对两个有序区间线性归并即可使 nums 数组里[l,r] 的部分有序。
- 线性归并的过程并不难理解,由于两个区间均有序,所以我们维护两个指针 i 和 j 表示当前考虑到 [l,mid] 里的第 i个位置和 [mid+1,r] 的第 j个位置。
- 如果
nums[i] <= nums[j],那么我们就将nums[i] 放入临时数组 tmp 中并让 i += 1 ,即指针往后移。 否则我们就将 nums[j] 放入临时数组 tmp 中并让 j += 1 。- 如果有一个指针已经移到了区间的末尾,那么就把另一个区间里的数按顺序加入 tmp 数组中即可。
- 这样能保证我们每次都是让两个区间中较小的数加入临时数组里,那么整个归并过程结束后 [l,r] 即为有序的。
- 函数递归调用的入口为
mergeSort(nums, 0, nums.length - 1),递归结束当且仅当l >= r。时间复杂度:O(nlogn)。由于归并排序每次都将当前待排序的序列折半成两个子序列递归调用,然后再合并两个有序的子序列,而每次合并两个有序的子序列需要 O(n) 的时间复杂度,合并次数为log(n)次,所以我们可以列出归并排序运行时间 T(n) 的递归表达式:T(n) = 2T(2/n) + O(n)。
空间复杂度:O(n)。我们需要额外 O(n) 空间的 tmp 数组,且归并排序递归调用的层数最深为nlogn,所以我们还需要额外的 O(logn) 的栈空间,所需的空间复杂度即为O(n + logn) = O(n).
class Solution:
def sortArray(self, nums: List[int]) -> List[int]:
def partition(nums, left_bound, right_bound):
# 随机算法加上这两步
# pivot = random.randint(left_bound, right_bound)
# nums[pivot], nums[right_bound] = nums[right_bound], nums[pivot]
pivot = nums[right_bound]
l,r = left_bound, right_bound - 1
while l <= r:
while l <= r and nums[l] <= pivot:
l += 1
while l <= r and nums[r] > pivot:
r -= 1
if l < r:
nums[l], nums[r] = nums[r], nums[l]
# 注意要把轴放在中间, 因为最后一次循环一定是走的l++,即当前l和r指向的是大值,互换l和锚点
nums[l], nums[right_bound] = nums[right_bound], nums[l]
return l
def quick_sort(nums, left_bound, right_bound):
if left_bound>=right_bound:
return
mid = partition(nums, left_bound, right_bound)
quick_sort(nums, left_bound, mid - 1)
quick_sort(nums, mid + 1, right_bound) # 注意是mid+1
quick_sort(nums, 0, len(nums)-1)
return nums最坏情况:当划分产生的两个子问题分别包含 n-1 和 0 个元素时,最坏情况发生。划分操作的时间复杂度为Θ(𝑛),𝑇(0)=O(1),这时算法运行时间的递归式为 𝑇(𝑛) = 𝑇(𝑛 − 1) + 𝑇(0) + O(𝑛) = 𝑇(𝑛 − 1) + O(𝑛),解为𝑇(𝑛) = O(𝑛2)T(n) = O(n2)。
最好情况:当划分产生的两个子问题分别包含⌊𝑛/2⌋和⌈𝑛/2⌉−1个元素时,最好情况发生。算法运行时间递归式为𝑇(𝑛) = 2𝑇(𝑛/2) + O(𝑛),解为𝑇(𝑛) = O(𝑛lg𝑛)。
时间复杂度:平均情况下快速排序的时间复杂度是O(nlogn),最坏情况是O(n2),但通过随机算法可以避免最坏情况。
空间复杂度:快排的空间复杂度O(logn)。因为快排的实现是递归调用的, 而且每次函数调用中只使用了常数的空间,因此空间复杂度等于递归深度O(logn)。