题目详情及资料搜集
赛题详情
https://tianchi.aliyun.com/competition/entrance/531810/introduction

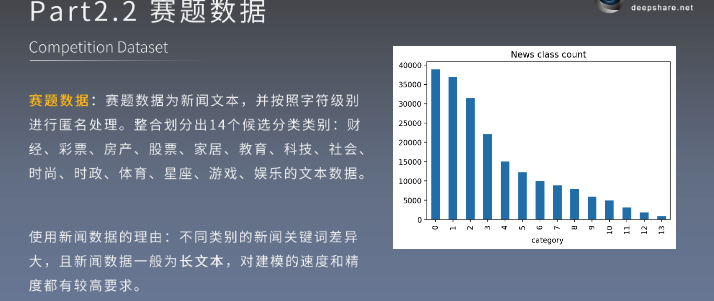
14分类任务
新闻数据特点: 关键词差异大, 长文本

匿名处理了

匿名数据 + 长文本 + 类别不均衡(匿名数据需要从头训练词向量)


兼顾召回和排序, 考虑样本不均衡
资料相关
【随堂更新】Baseline文件+PPT课件+相关学习资料
Baseline代码:
链接:https://pan.baidu.com/s/1MZdm0qVUFxInMm2RVByRkg
提取码:w8zs
第一次直播PPT:
链接:https://pan.baidu.com/s/1ri3pnONIWosSbTmPduZnOg
提取码:3y4g
专题一 比赛概览总结及问题
收集:https://shimo.im/docs/XjgPqPPXtqXTQPGh
第二次直播代码文件:
链接:https://pan.baidu.com/s/1BH6aK_oMfgAA6_VsX_Ca0w
提取码:upcq
第二次直播PPT:
链接:https://pan.baidu.com/s/1-SiyrxX4TGMb2zZjHmkV9g
提取码:af5u
阿水-kaggle流程脑图分享
链接:https://pan.baidu.com/s/1t_bp2jEDlnlIQe7Qk-YJ7A
提取码:fhwp
第三次直播代码文件:
链接:https://pan.baidu.com/s/1hdymNFDnjtQYaZymcwQ9Hg
提取码:sfsz
第三次直播PPT:
链接:https://pan.baidu.com/s/1tE6DmYLKYWEDva4GwzuTRQ
提取码:vdec
第四次直播代码文件:
链接:https://pan.baidu.com/s/1DxYVBWRW9p9vwlZ6BESC_Q
提取码:30le
第四次直播PPT:
链接:https://pan.baidu.com/s/17GUgr7vNxYeoQIVuMQh8Hw
提取码:a7xd
第五次直播PPT:
链接:https://pan.baidu.com/s/12otriJ5yDyb7d3fmXypO2g
提取码:5tyi
第六次直播PPT:
链接:https://pan.baidu.com/s/1H1iYzkEkmuXWLd7CX62tbg
提取码:r5s7
专题一 比赛概览 总结及问题收集
官方文档永远是最好的学习资料!!!
官方文档永远是最好的学习资料!!!
官方文档永远是最好的学习资料!!!
🍰工具篇:
-
以pycharm为例:
-
https://www.jetbrains.com/help/pycharm/configuring-remote-interpreters-via-virtual-boxes.html
🍫python库篇:
-
以pandas为例:
-
https://pandas.pydata.org/docs/
-
scikit-learning是Python最通用的机器学习库:
-
官网:https://scikit-learn.org/stable/index.html
-
十分钟入门:https://scikit-learn.org/stable/getting_started.html
-
入门教程:https://scikit-learn.org/stable/tutorial/index.html
-
用户指南:https://scikit-learn.org/stable/user_guide.html#
-
专业术语表:https://scikit-learn.org/stable/glossary.html
-
API文档:https://scikit-learn.org/stable/modules/classes.htm
性能查看
nvidia-smi
比赛收益
文本分类的任务是将给定的文本划分到事先规定的文本类别。
-
赛题难度:
- 匿名数据 + 长文本 + 类别不均衡。
-
解题思路:
- 思路1:TF-IDF + 机器学习分类器
直接使用TF-IDF对文本提取特征,并使用分类器进行分类。在分类器的选择上,可以使用SVM、LR、或者XGBoost。
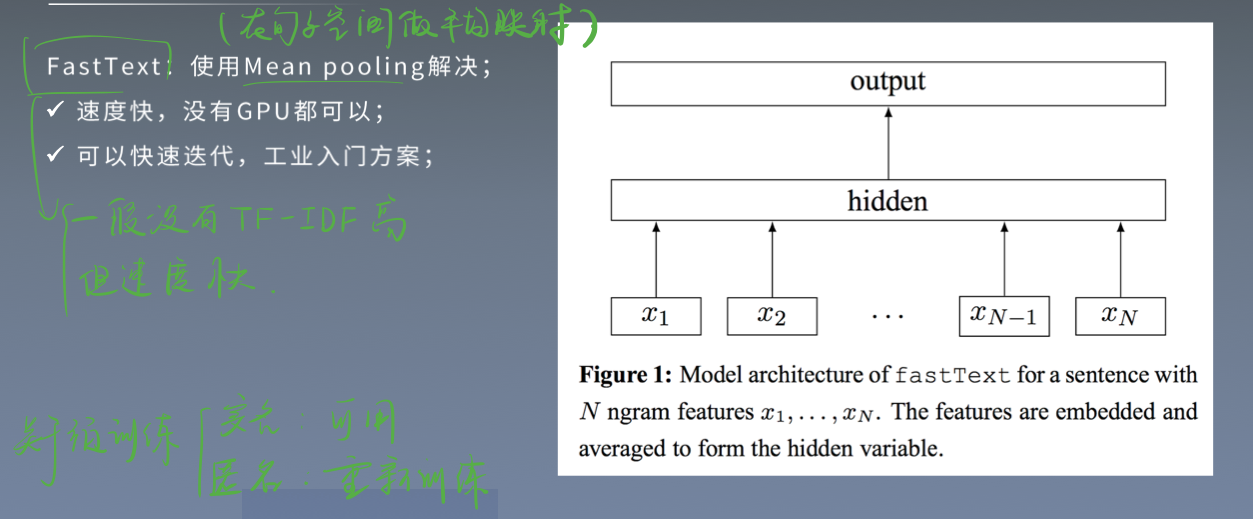
- 思路2:FastText
FastText是入门款的词向量,利用Facebook提供的FastText工具,可以快速构建出分类器。
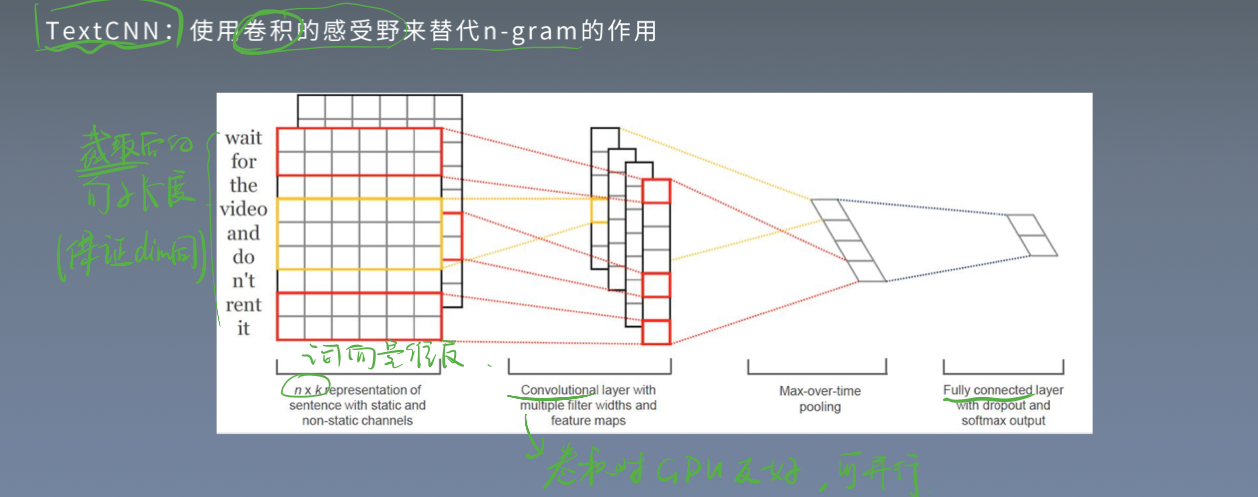
- 思路3:WordVec + 深度学习分类器
WordVec是进阶款的词向量,并通过构建深度学习分类完成分类。深度学习分类的网络结构可以选择TextCNN、TextRNN或者BiLSTM。
- 思路4:Bert词向量
Bert是高配款的词向量,具有强大的建模学习能力。








模型思路
思路 + baseline1 - 0.91?
TF-IDF TfidfVectorizer()
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术,常用于挖掘文章中的关键词,而且算法简单高效,常被工业用于最开始的文本数据清洗。
1
tfidf = TfidfVectorizer(ngram_range=(1, 4), max_features=5000).fit(train_df['text'].iloc[:].values)
ngram_range # 统计多少个词之间的的特征
max_features # 转化为向量特征长度
train_tfidf # Transform 后转化为 样本量*特征维度的稀疏矩阵(200000*4000)
3种机器学习方法
1
2
3
4
clf = RidgeClassifier()
clf = LogisticRegression()
clf = LGBMClassifier() # LightGBM 有集成学习思想, 效果比较好
clf.fit(train_tfidf, train_df['label'].iloc[:].values)
程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import RidgeClassifier, LogisticRegression
from lightgbm import LGBMClassifier
import pandas as pd
!pwd
!ls ../input -lh
# train_df = pd.read_csv('../input/train_set.csv', sep='\t', nrows=4000)
# test_df = pd.read_csv('../input/test_a.csv', sep='\t', nrows=1000)
train_df = pd.read_csv('../input/train_set.csv', sep='\t', nrows=150000)
test_df = pd.read_csv('../input/test_a.csv', sep='\t', nrows=None)
# !head ../input/train_set.csv -n 2
# best 4000 features ngram_range参数, 多少个词之间的的特征
tfidf = TfidfVectorizer(ngram_range=(1, 4), max_features=5000).fit(train_df['text'].iloc[:].values)
train_tfidf = tfidf.transform(train_df['text'].iloc[:].values)
test_tfidf = tfidf.transform(test_df['text'].iloc[:].values)
# clf = RidgeClassifier()
# clf = LogisticRegression()
clf = LGBMClassifier()
clf.fit(train_tfidf, train_df['label'].iloc[:].values)
df = pd.DataFrame()
df['label'] = clf.predict(test_tfidf)
df.to_csv('submit_2.csv', index=None)
赛题思路



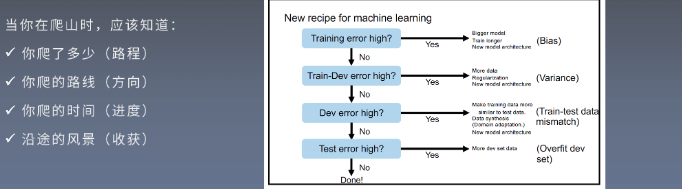





10000训练样本
Baseline2
NLP基础 - 笔记在notibality
- 非结构化数据不需要很多EDA, 相反在结构化数据中很需要
- 预处理方式
- 句子截取和填充, 使维度一致来训练模型
预训练词向量方法
fasttext, word2vec, glove, bert
分类模型:
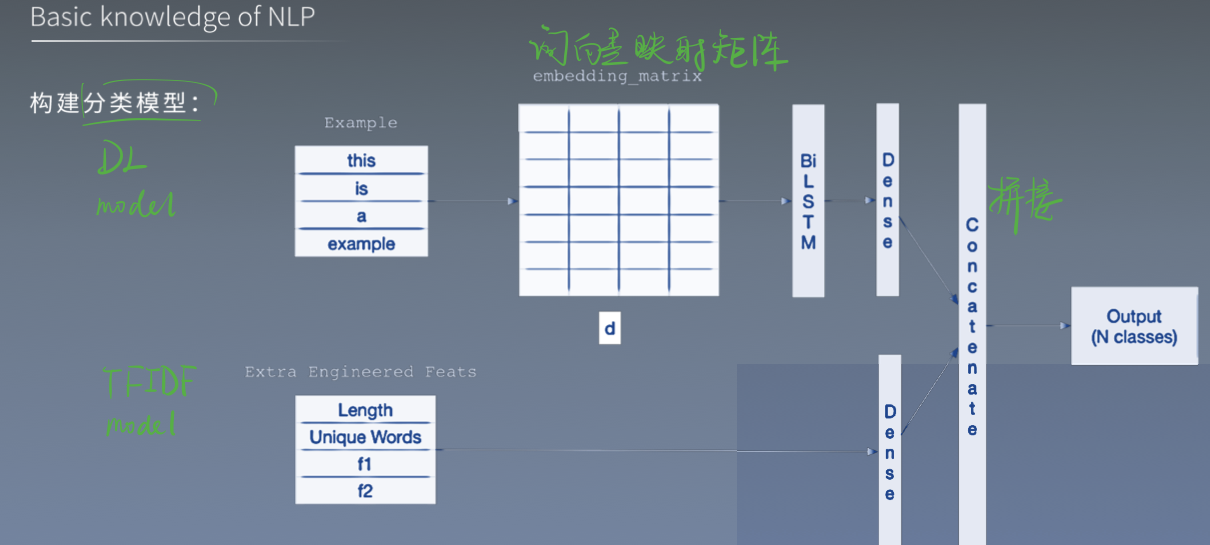
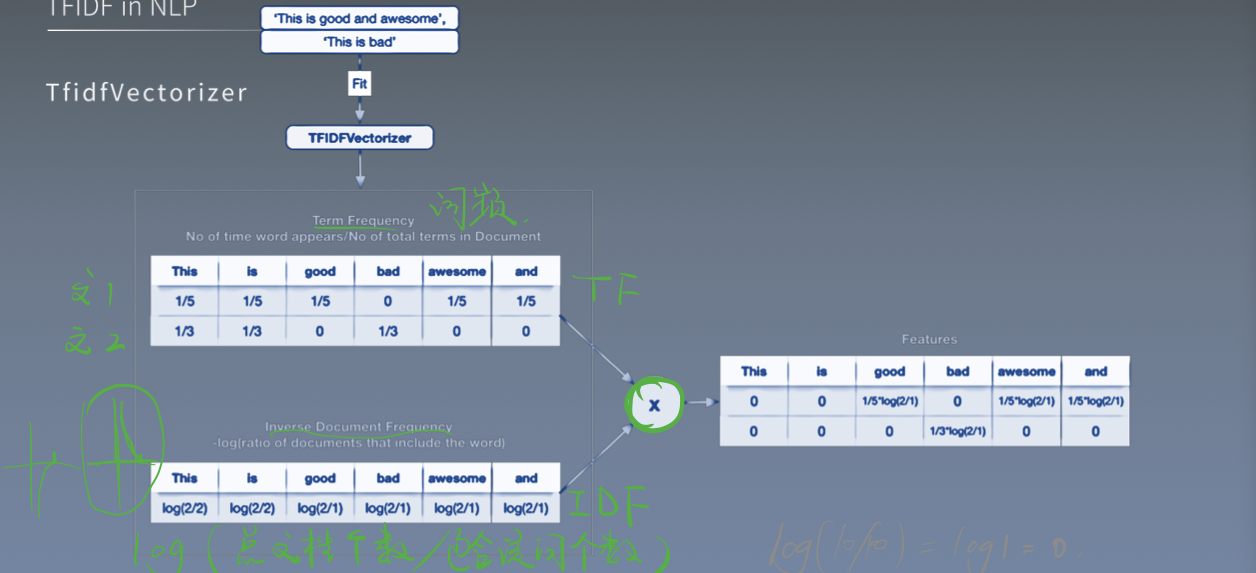
TF-IDF:
- N-gram , 是一种语言模型, 利用滑窗思想统计频率
- Countvectorizer, 将文本编码并统计, 统计词的数量(对应CV中特征的数量)
- 模型和公式:
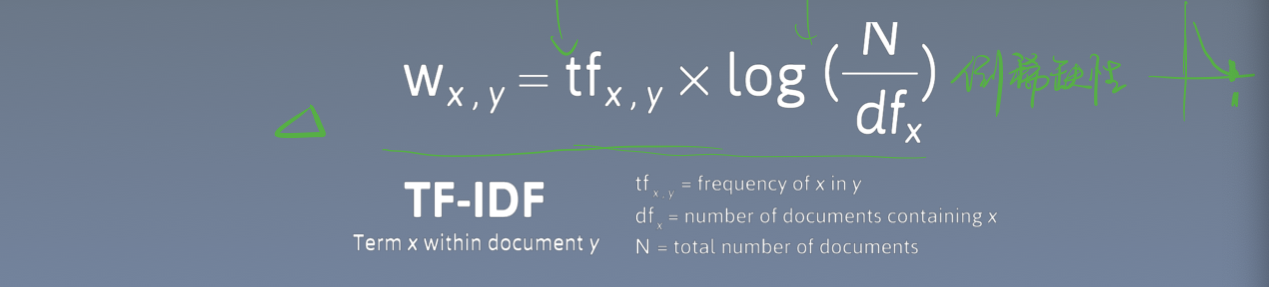
词向量
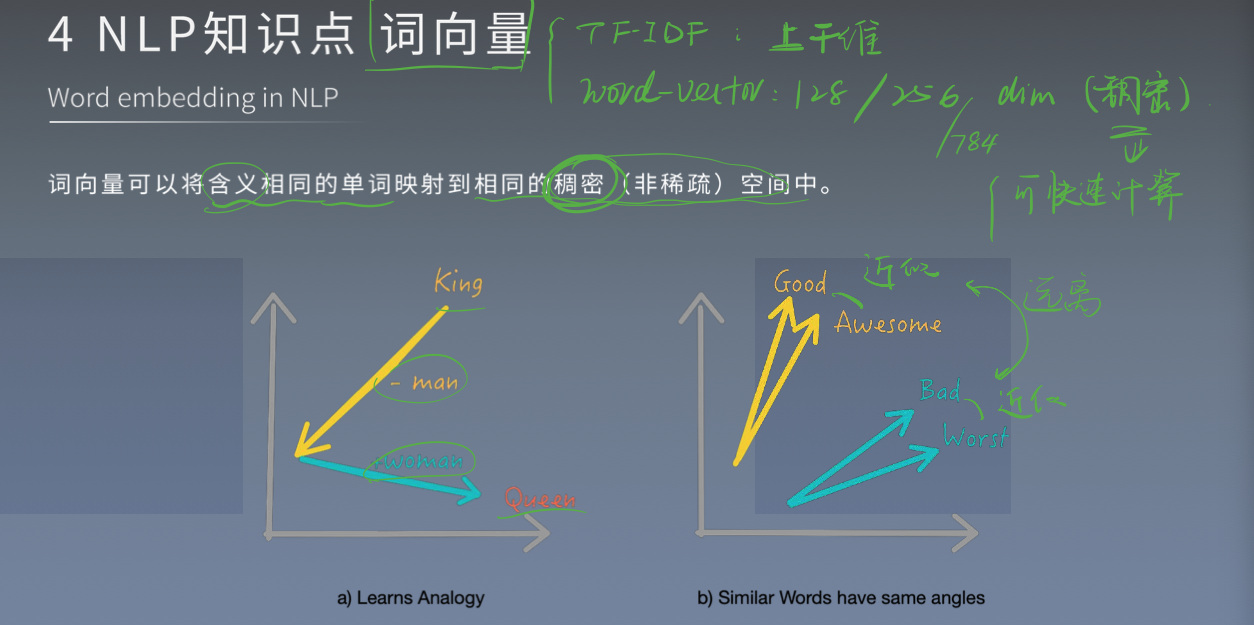
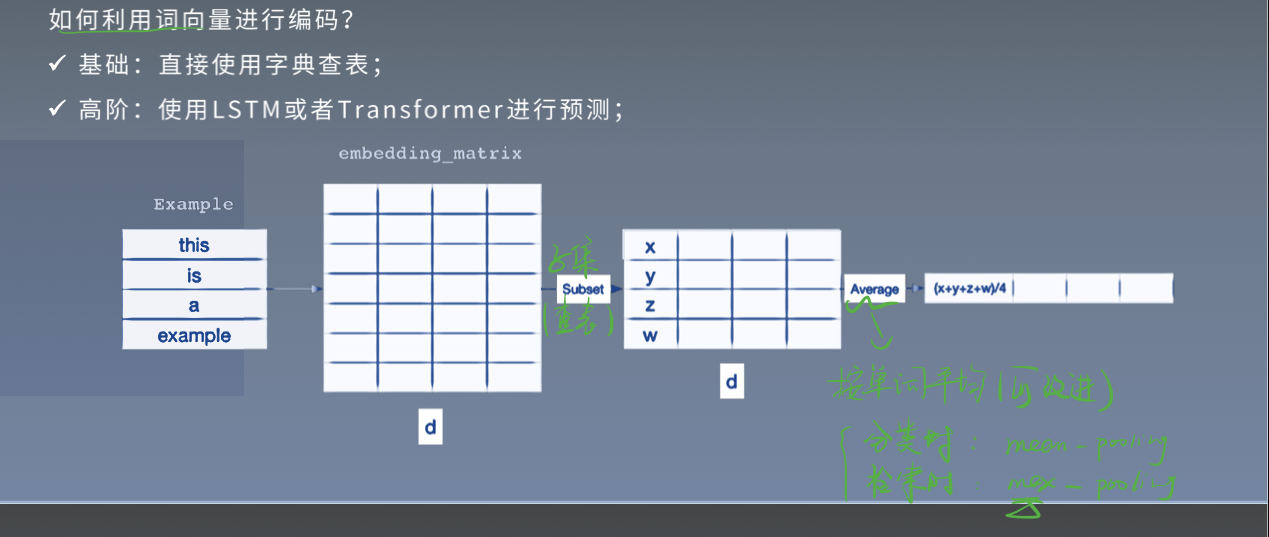
fastText
TextCNN
统计最多的字符数
1
2
3
4
5
6
# 拼接训练集文本和测试集文本,分词,找到最大的word
all_lines = ' '.join(train_df['text']) + ' ' + ' '.join(test_df['text'])
all_words = np.array(all_lines.split()).astype(int)
all_words.max()
# 输出7579, 说明总共包含7550个字符
加入5折交叉验证并输出最佳的预测
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# max_features, ngram_range 3 就够了
tfidf = TfidfVectorizer(ngram_range=(1, 3), max_features=10000).fit(train_df['text'].iloc[:].values)
train_tfidf = tfidf.transform(train_df['text'].iloc[:].values)
test_tfidf = tfidf.transform(test_df['text'].iloc[:].values)
# 5折交叉验证
skf = StratifiedKFold(n_splits=5, random_state=7)
test_pred = np.zeros((test_tfidf.shape[0], 14), dtype=np.float32)
for idx, (train_index, valid_index) in enumerate(skf.split(train_tfidf, train_df['label'].values)):
x_train_, x_valid_ = train_tfidf[train_index], train_tfidf[valid_index]
y_train_, y_valid_ = train_df['label'].values[train_index], train_df['label'].values[valid_index]
clf = LGBMClassifier()
clf.fit(x_train_, y_train_)
val_pred = clf.predict(x_valid_)
print(f1_score(y_valid_, val_pred, average='macro'))
test_pred += clf.predict_proba(test_tfidf)
df = pd.DataFrame()
df['label'] = test_pred.argmax(1)
df.to_csv('submit.csv', index=None)
Baseline3 竞赛流程与pipline - baseline强化
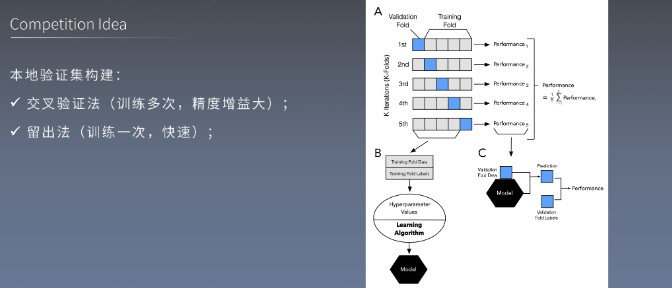
任务名称:模型训练与交叉验证
任务详解:
- 对理解3中数据划分方法优缺点;
- 学习使用sklearn中的数据划分方法;
竞赛流程
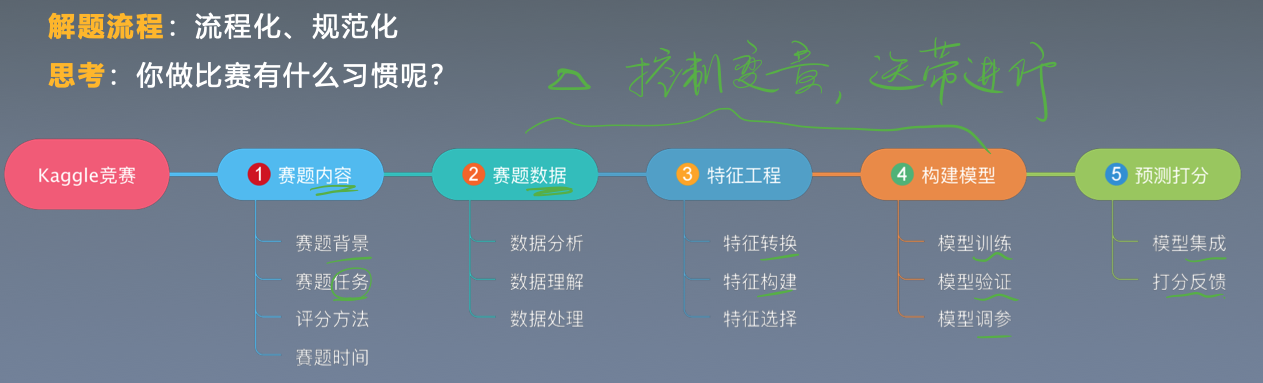

- 赛题类型和不同评估方式
- 字段分布分析
- 数据分析
- 特征工程
- 机器学习模型
- 模型集成方法
- 模型训练验证
**伪标签方法, 概率值等**- 缓解过拟合方法
- 了解模型上限
- 数据划分方法
- 文本数据扩增方法
- 分布一致性(CV, LB)
数据划分方式
主要用SKF
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# hold-out
from sklearn.model_selection import train_test_split
# K折交叉验证
from sklearn.model_selection import KFold
from sklearn.model_selection import RepeatedKFold
# K折分布保持交叉验证, 好
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import RepeatedStratifiedKFold
# 时间序列划分方法
from sklearn.model_selection import TimeSeriesSplit
# booststrap 采样
from sklearn.utils import resample
fasttext代码
对抗验证
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from sklearn.feature_extraction.text import TfidfVectorizer
train_df = pd.read_csv('../input/train_set.csv', sep='\t', nrows=5000)
test_df = pd.read_csv('../input/test_a.csv', sep='\t', nrows=5000)
tfidf = TfidfVectorizer(ngram_range=(1, 2), max_features=500).fit(train_df['text'].iloc[:].values)
train_tfidf = tfidf.transform(train_df['text'].iloc[:].values)
test_tfidf = tfidf.transform(test_df['text'].iloc[:].values)
# 拼接训练的tfidf和测试的tfidf
train_test = np.vstack([train_tfidf.toarray(), test_tfidf.toarray()])
# 标签为 1 和 0
lgb_data = lgb.Dataset(train_test, label=np.array([1]*5000+[0]*5000))
params = {}
params['max_bin'] = 10
params['learning_rate'] = 0.01
params['boosting_type'] = 'gbdt'
params['metric'] = 'auc'
result = lgb.cv(params, lgb_data, num_boost_round=100, nfold=3, verbose_eval=20)
pd.DataFrame(result)
不加bert上限 0.96
加bert上限 0.98左右
加伪标签
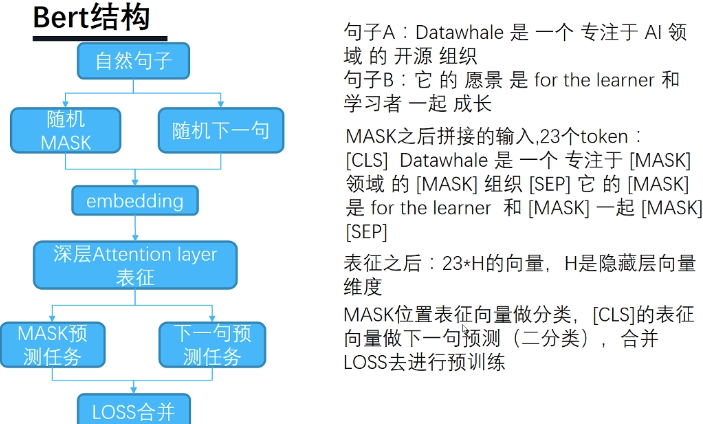
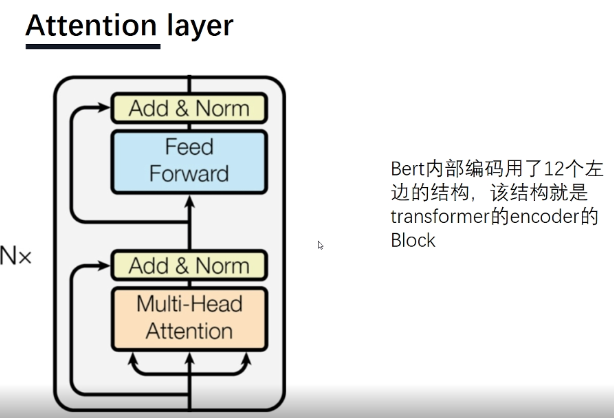
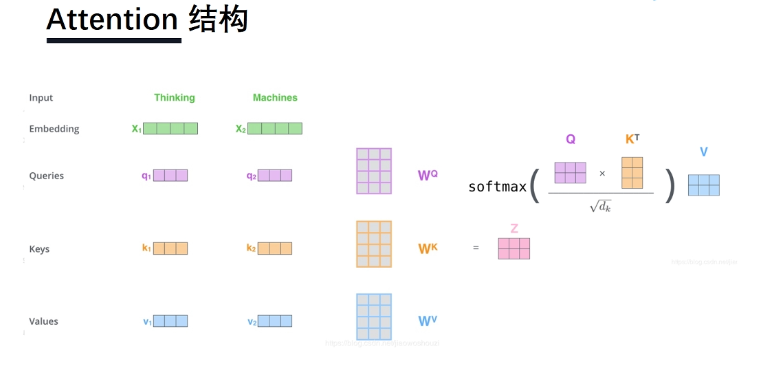
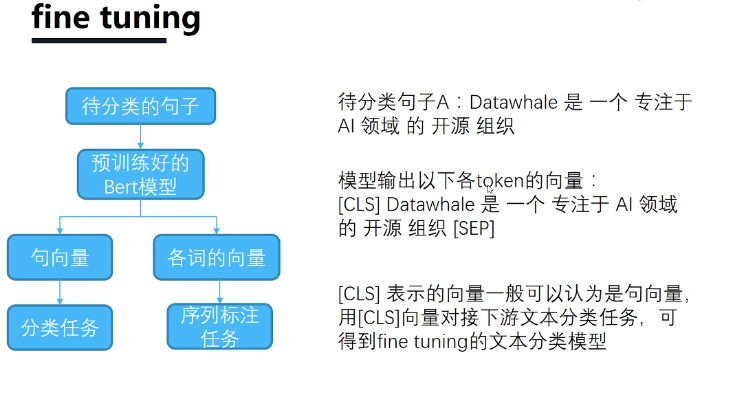
bert预训练模型讲解