赛题一 — 广告CTR预估
2.1.赛题理解
本次ctr预估题目非常传统,给定前7天内每条曝光的点击行为,预测将来某一天内曝光的点击率,评价指标AUC。数据集划分如下:
初赛阶段:训练集1-7天,A榜测试集第8天,B榜测试集第9天。
决赛阶段:训练集1-7天,A榜测试集第8天,B榜测试集第10天。
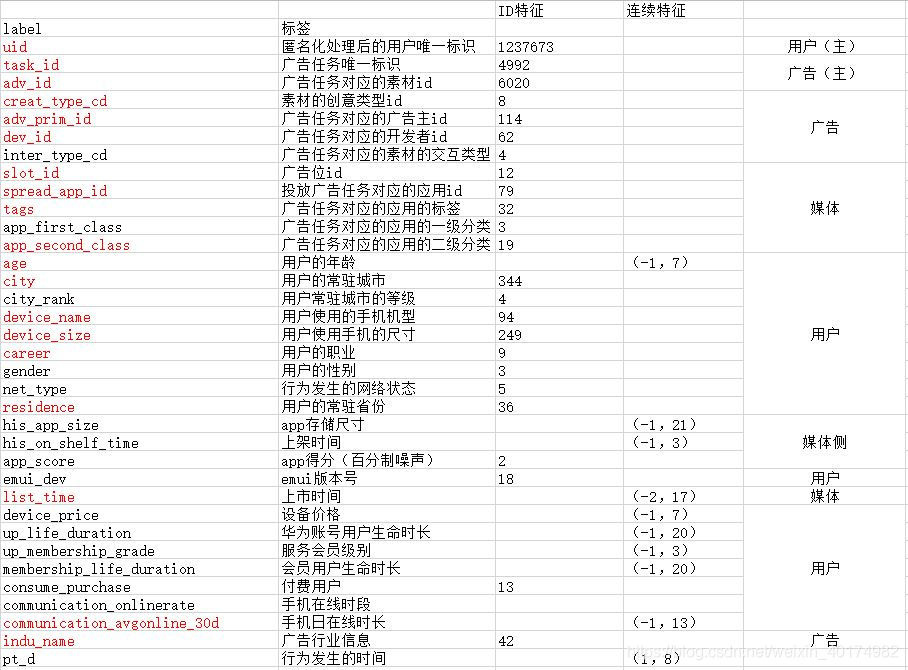
具体的特征可以看一下官网的描述,我们这里稍微统计了一下,将特征根据内容划分为用户、广告、媒体三方面特征,也可根据数据类型划分为ID特征和连续特征。
其中,关注的重点在于用户特征和ID特征。
2.2.特征工程
我们使用的特征工程非常的常规,以至于大家看完可能都会说一句:就这?包含四个特征:曝光特征、交叉特征、ctr特征、embedding特征:
曝光特征:统计所有ID类特征在8天内的曝光次数(即count特征)
交叉特征:统计用户ID与所有广告侧ID、广告ID与所有用户侧ID的类别交叉,如某个用户ID曝光过多少不同的广告ID(即nunique特征)
CTR特征:统计所有ID类特征前所有天的历史点击率
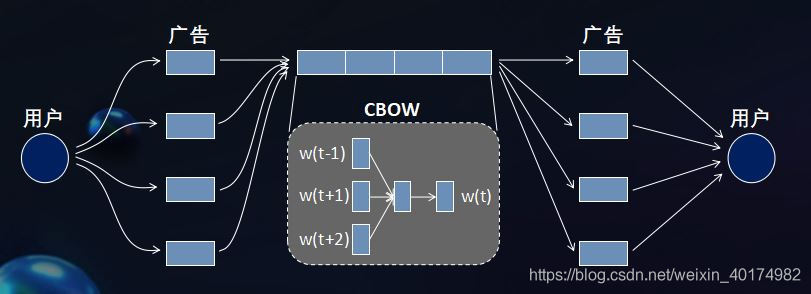
embedding特征🚩:构建广告曝光序列,训练word2vector得到广告表征,平均广告表征得到用户表征
对于这些特征,还可以采取用滑窗的方式来统计,效果不一定更好,不过会有一定差异性。
在B榜阶段,由于测试集是第9天或者第10天,与前7天的训练集隔了一到两天,会带来很明显的gap。这里我们将A榜的数据也放进去一起统计特征,就可以显著提升效果。这里的A榜数据只用于辅助做特征,并不参与训练。我们也试过将之前A榜的预测结果二值化然后当成训练数据来用,结果就会带来非常严重的过拟合。
我们的方案经过优化之后,占用内存不到20G,目前看来应该是最轻量级的方案。
2.3.算法实现
我们使用lightgbm作为模型,在实际训练的时候给予时间上越靠近测试集的样本给予更大的权重。具体来说,第7天的样本权重是1,第2天样本的权重就是2/7。
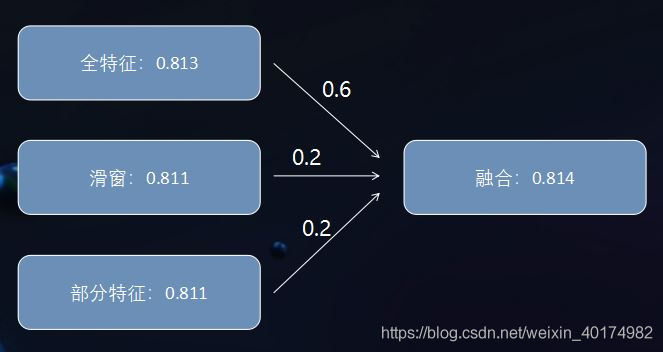
我们通过滑窗和去除冗余特征构造差异性模型来进行融合,在初赛A榜阶段一直使用单模,B榜阶段双模,决赛阶段三模。下图是我们决赛B榜的分数,其实我们单模就已经到了0.8137,刚好比第二的分数高了一个千。
赛题二 — 搜索相关性预测
对于Web数据的搜索引擎,排序是其核心问题。提升排序的准确度能够极大提升用户的搜索体验。在本次大赛中,主办方提供用于排序模型构建的数据,参赛选手基于给定的数据构建排序模型。希望通过本次大赛挖掘搜索引擎排序算法的人才,推动搜索引擎排序算法的发展。
评价指标:Expected Reciprocal Rank (ERR)
排序是信息检索的核心技术:给定一个Query,系统能够基于文档和Query的相关性,将候选的文档做排序,展现给用户。本次比赛提供的数据集包含两部分:训练集和测试集。其中训练集包含相关度标签、queryid、文档id和各类特征数据,选手基于该数据集训练排序模型。测试集包含queryid、文档id和各类特征数据,选手基于测试集提供预测后的相关度得分。
训练集中的相关度标签为离散值,分为5档,数字越大代表文档和Query越相关。相关度标签度和相关度评级关系如下:
| 4 | Perfect |
|---|---|
| 3 | Excellent |
| 2 | Good |
| 1 | Fair |
| 0 | Bad |
本次比赛的特征数为362个,这362个特征是在特征筛选过程中,基于特征重要性保留下来的。特征分为如下几大类:
Query
提供query的统计指标,如词个数、核心词个数等。
文档
包含文档、URL的一些统计信息。如正文长度、标题长度、URL长度等。
文本匹配
占比较大的一类特征,代表了Query和文档的匹配程度。这些特征或者是统计类型或者是得分(如BM25得分)。统计类的特征如Query词在文档中出现的比例。文本匹配特征会基于文档位置(正文、标题、URL、锚文本)的不同,产生多个匹配特征。同时也提供了紧密度特征用于表示文档和Query文本距离的远近。
网络图
这些指标通过在整个web链接图上的连接关系来表示网页的质量、流行度,比如PageRank指标。
时间特征
包含的文档发布时间等特征。
搜索意图
Query搜索意图的特征,包含体育、娱乐、时政、科技、寻址等类别。比如“寻址”这个特征代表了该query希望能够直接检索到特定网站的意图高低。
文档结构分类
基于文档的结构类型对文档做分类。特征包括索引页、新闻页、视频页、论坛页、首页等。
站点分类
基于所覆盖的主题对文档所属网站做分类,站点分类特征包括如体育、视频、音乐、新闻等。
文档内容分类
基于文档的内容类型对文档做分类。特征包括财经、宠物、动漫、房产等。从文档的标题、Anchor、正文内容、keyword等四个部分提供了内容分类的识别结果。
排序模型的样本是重要资产,为保证安全,初赛阶段不公开query信息。数据集中的query使用编码来表示。
数据说明
数据概况
比赛数据选取了生产系统中若干个query和文档,随机拆分为训练集和测试集。训练集和测试集的文件格式一致,不包含行头,列之间通过’\t’字符分割。
训练集字段说明
每一行都是一个query-文档对,各列的描述如下:
\1. 第1列:query和文档的相关度标记值,值越高,代表越相关
\2. 第2列:query id,数字类型,唯一标识一个query
\3. 第3列:文档ID, 数字类型,唯一标识一个文档
\4. 第4到365列:362个特征值,特征描述见赛事简介
数据集中索引地址和特征类别的对应关系如下。数据集中索引位置3到200的字段类型为NUMERICAL,索引位置201到364的字段类型为CATEGORY。
| 索引 | 特征类别 |
|---|---|
| [3,5] | Query |
| 6 | 文本匹配 |
| 7 | 时间 |
| 8 | 文档 |
| [9,10] | 网络图 |
| [11,36] | 文档 |
| 37 | 网络图 |
| 38 | 文档 |
| [39,46] | 文本匹配 |
| 47 | 文档 |
| [48,58] | 文本匹配 |
| 59 | 时间 |
| [60,61] | 文本匹配 |
| [62,67] | 文档 |
| 68 | 网络图 |
| [69,77] | 文档 |
| 78 | 时间 |
| [79,155] | 文本匹配 |
| [156,200] | 搜索意图 |
| [201,220] | 文档 |
| [221,232] | 页面结构分类 |
| [233,244] | 站点分类 |
| [245,274] | 基于标题的内容分类 |
| [275,304] | 基于正文内容的内容分类 |
| [305,334] | 基于Anchor的内容分类 |
| [335,364] | 基于keyword的内容分类 |
测试集字段说明
两份测试集的字段格式是一致的。每一行都是一个query-文档对,各列的描述如下:
\1. 第1列:query id,数字类型,唯一标识一个query
\2. 第2列:文档ID, 数字类型,唯一标识一个文档
\3. 第3到364列:362个特征值,特征描述见赛事简介