HSI数据
Indian Pines
Indian Pine数据
yIndian Pine 是由 AVIRIS 传感器在印第安纳州拍摄的。这个数据的大小是145*145,有224个波段,其中有效波段200个。这个数据一共有16个农作物类别。


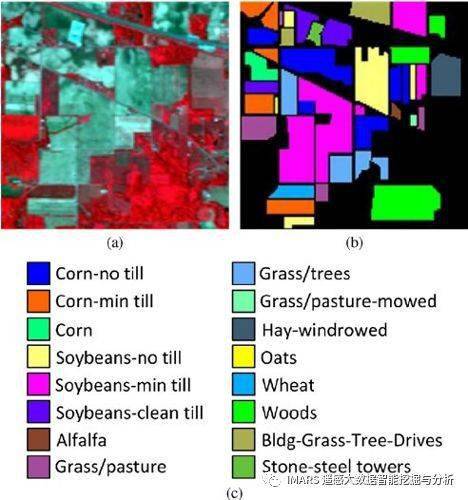


10249像素
| # | Class | Samples |
|---|---|---|
| 1 | Alfalfa | 46 |
| 2 | Corn-notill | 1428 |
| 3 | Corn-mintill | 830 |
| 4 | Corn | 237 |
| 5 | Grass-pasture | 483 |
| 6 | Grass-trees | 730 |
| 7 | Grass-pasture-mowed | 28 |
| 8 | Hay-windrowed | 478 |
| 9 | Oats | 20 |
| 10 | Soybean-notill | 972 |
| 11 | Soybean-mintill | 2455 |
| 12 | Soybean-clean | 593 |
| 13 | Wheat | 205 |
| 14 | Woods | 1265 |
| 15 | Buildings-Grass-Trees-Drives | 386 |
| 16 | Stone-Steel-Towers | 93 |
Pavia University
Pavia University 和 Pavia Center 数据是由ROSIS传感器获取的,常被用于高光谱图像分类。传感器一共有115个波段,经过处理后,Pavia University数据有103个波段;Pavia Center 数据有102个波段。两幅影像都有9个地物类别,这两幅影像的类别不完全一致。其中,Pavia University的大小为610×340,Pavia Center的大小是1096*715,详细信息如下图所示。
.jpg)
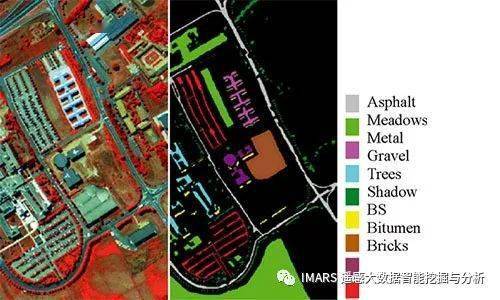

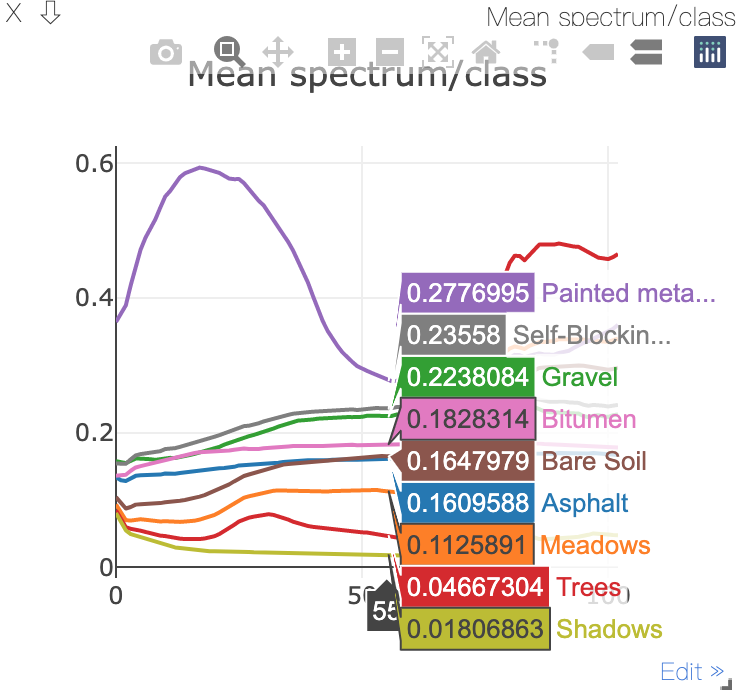

42776像素, 145*145*200=21025
| # | Class | Samples |
|---|---|---|
| 1 | Asphalt | 6631 |
| 2 | Meadows | 18649 |
| 3 | Gravel | 2099 |
| 4 | Trees | 3064 |
| 5 | Painted metal sheets | 1345 |
| 6 | Bare Soil | 5029 |
| 7 | Bitumen | 1330 |
| 8 | Self-Blocking Bricks | 3682 |
| 9 | Shadows | 947 |
Salinas Valley数据
Salinas 是由 AVIRIS 传感器拍摄,拍摄地点是加州 Salinas Valley。这个数据的空间分辨率是3.7米,大小是512*217。原始数据是224个波段,去除水汽吸收严重的波段后,还剩下204个波段。这个数据包含了16个农作物类别

Houston数据
Houston数据是由ITRES CASI-1500传感器获取的,由2013 IEEE GRSS数据融合大赛提供。数据大小为349*1905,包含光谱范围从364nm到1046nm的144个波段。地物覆盖被标注为如下图所示的15个类别。
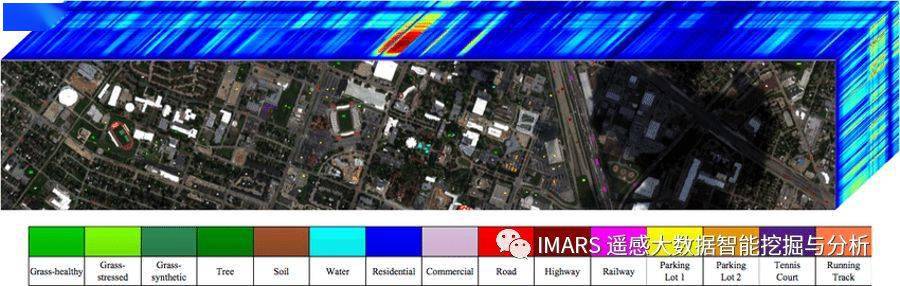


DFC2018 Houston数据
DFC2018 Houston 是2018年IEEE GRSS Data Fusion 比赛所用的数据集。这个数据是由 University of Houston Dr. Saurabh Prasad 的实验室制作公开的。这个数据是个多传感器数据,包含了48个波段的高光谱数据(1米),3波段的LiDAR数据(0.5米),以及超高分辨率影像(0.05米)。这个数据包含了20类地物。使用这个数据前请联系 Dr. Saurabh Prasad.
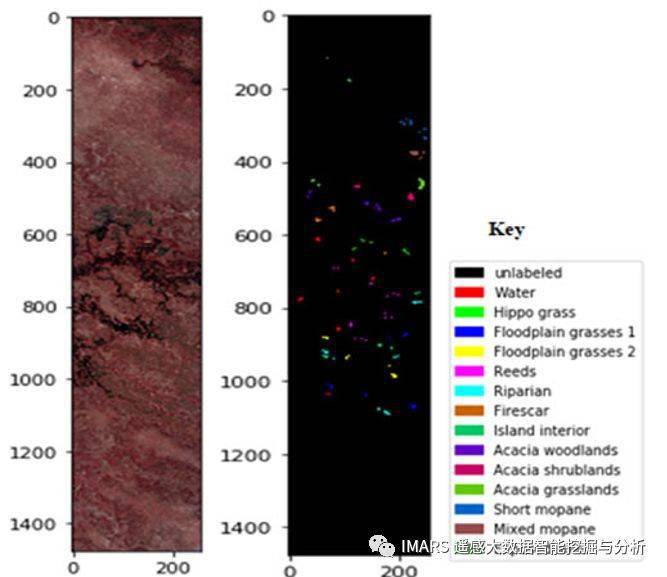
航空高光谱影像 Chikusei
这个航空高光谱数据是由Headwall Hyperspec-VNIR-C传感器于日本筑西市(Chikusei)拍摄的,拍摄时间是2014年7月29日。这个数据包含了128个波段,范围是343 – 1018 纳米,大小是2517*2335,空间分辨率是2.5米。一共有19类地物,包含了城市与农村地区。这个数据是由东京大学 Dr. Naoto Yokoya 与 Prof. Akira Iwasaki 制作公开的。

KSC数据集
KSC数据由 AVIRIS 传感器在佛罗里达州肯尼迪太空中心于1996年3月23日拍摄。这个数据包含了224个波段,经过水汽噪声去除后还剩下176个波段,空间分辨率是18米,一共有13个类别。
下载页面:
http://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes

Botswana数据
该数据集源自美国宇航局EO-1卫星于2001-2004年在Botswana获得的一系列数据。EO-1上的传感器在242个波段获得了30米像素分辨率的数据,覆盖波段为400-2500nm并以10nm为间隔。去除了噪声波段后,其余145个波段作为候选特征包括:[10-55,82-97,102-119,134-164,187-220]。数据包括来自14个已确定的类别.
下载页面:
http://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes
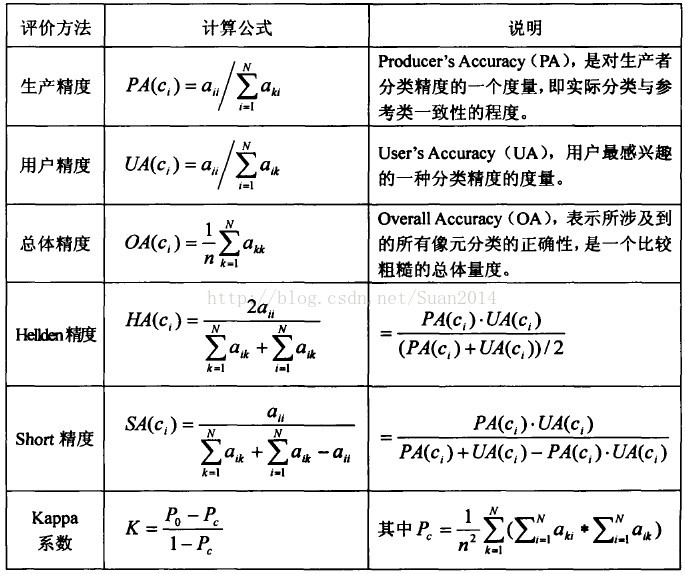
评价指标
总体精度是模型在所有测试集上预测正确的与总体数量之间的比值,平均精度是每一类预测正确的与每一类总体数量之间的比值,最终再取每一类的精度的平均值。
混淆矩阵

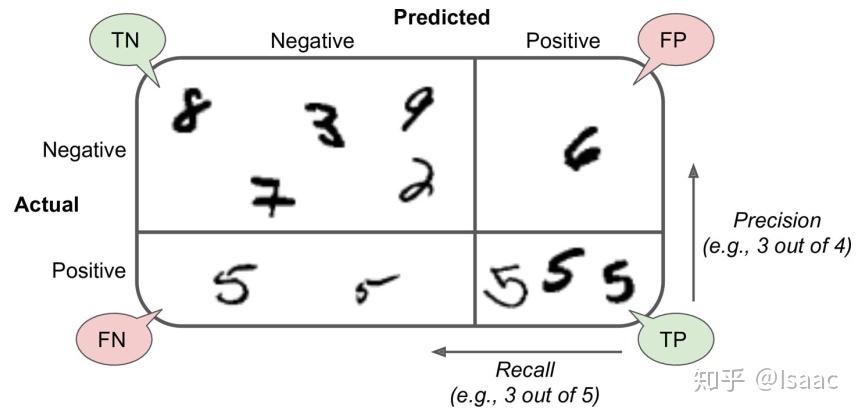
混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。
| Predicted as Positive(预测-正例) | Predicted as Negative(预测-反例) | |
|---|---|---|
| Labeled as Positive (真实-正例) | True Positive(TP-真正例) | False Negative(FN-假反例) |
| Labeled as Negative (真实-反例) | False Positive(FP-假正例) | True Negative(TN-真反例) |
TP:真正,被模型分类正确的正样本 【预测为1 实际为1】
FN:假负,被模型分类错误的正样本 【预测为0 实际为1】
FP:假正,被模型分类错误的负样本 【预测为1 实际为0】
TN:真负,被模型分类正确的负样本 【预测为0 实际为0】
计算评价指标
Precision查准率、精确率:(针对预测结果)
分类正确的正样本个数占分类器分成的所有正样本个数的比例

Recall查全率、召回率:(针对原来样本)
分类正确的正样本个数占正样本个数的比例

F1值:
F1度量的一般形式是:
度量了查全率对查准率的相对重要性
时退化为标准的F1
时查全率有更大影响
时查准率有更大影响
F1是基于查全率和查准率的调和平均定义的如下:
 *or*
*or* 
TPR:真正例率

FPR:假正例率

ROC曲线:
根据学习器的预测结果对样例进行排序,按此顺序逐个把正例进行预测,每次计算出真正例率、假正例率,并以真正例率为纵轴,假正例率为横轴,即得到ROC曲线
总体分类精度(Overall Accuracy):
分类正确的样本个数占所有样本个数的比例
 或
或 
Kappa系数:

- - - - - - - - - - - - - - - - - - - - - - – - - – - - - - - - - - - - - - - - – - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
(二) 例: 单位/像素(pixel)
| class | 水体 | 林地 | 耕地 | 未利用地 | 居民地 | 总计 |
|---|---|---|---|---|---|---|
| 水体 | 25792 | 0 | 0 | 2 | 44 | 25838 |
| 林地 | 80 | 16825 | 297 | 684 | 1324 | 19210 |
| 耕地 | 519 | 60 | 27424 | 38 | 11542 | 39583 |
| 未利用地 | 31 | 0 | 0 | 9638 | 487 | 10156 |
| 居民地 | 323 | 0 | 49 | 133 | 30551 | 31056 |
| 总计 | 26745 | 16885 | 27770 | 10495 | 43948 | 125843 |
| 林地 | Predicted as Positive | Predicted as Negative |
|---|---|---|
| Labeled as Positive | 16825(TP) | 2385(FN) |
| Labeled as Negative | 60(FP) | 93405(TN) |
林地-精确率P:
P = (16825)/(16825+60)= 0.9964
林地-召回率R:
R = (16825)/(16825+2385)= 0.8758
林地-F1值:

总体精度: 正确分类的像元总和除以总像元数。被正确分类的像元数目沿着混淆矩阵的对角线(红色字体)分布,总像元数等于所有真实参考源的像元总数 (蓝色字体)
OA = (110230/125843)=87.5933%
Kappa系数:通过把所有真实参考的像元总数(N)乘以混淆矩阵对角线(Xii)的和,再减去各类中真实参考像元数与该类中被分类像元总数之积之后,再除以像元总数的平方减去各类中真实参考像元总数与该类中被分类像元总数之积对所有类别求和的结果。
K = 0.8396
- - - - - - - - - - - - - - - - - - - - - - – - - – - - - - - - - - - - - - - - – - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
自己算一下
Confusion matrix :
[[ 6227 0 26 3 0 0 83 86 6] —> 6431 (全部测试集)
[ 1376 15298 6 307 0 1462 0 0 0] —> 18449
[ 93 0 1773 0 0 0 0 33 0] —>
[ 37 4 4 2816 2 0 0 1 0]
[ 0 0 0 0 1145 0 0 0 0]
[ 0 84 0 2 0 4729 0 14 0]
[ 21 0 0 0 0 0 1109 0 0]
[ 14 0 12 1 0 11 0 3442 2]
[ 0 0 0 1 0 0 0 0 746]]—
Accuracy : 90.992%
F1 scores : Asphalt: 0.877 Meadows: 0.904 Gravel: 0.953 Trees: 0.940 Painted metal sheets: 0.999 Bare Soil: 0.857 Bitumen: 0.955 Self-Blocking Bricks: 0.975
Shadows: 0.994
Kappa: 0.883
| 类别\预测 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 总数 | P | F1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 6227 | 0 | 26 | 3 | 0 | 0 | 83 | 86 | 6 | 6431 | 0.96827865 | 0.877104021 |
| 2 | ==1376== | 15298 | 6 | 307 | 0 | ==1462== | 0 | 0 | 0 | 18449 | ||
| 3 | 93 | 0 | 1773 | 0 | 0 | 0 | 0 | 33 | 0 | 1899 | ||
| 4 | 37 | 4 | 4 | 2816 | 2 | 0 | 0 | 1 | 0 | 2864 | ||
| 5 | 0 | 0 | 0 | 0 | 1145 | 0 | 0 | 0 | 0 | 1145 | ||
| 6 | 0 | 84 | 0 | 2 | 0 | 4729 | 0 | 14 | 0 | 4829 | ||
| 7 | 21 | 0 | 0 | 0 | 0 | 0 | 1109 | 0 | 0 | 1130 | ||
| 8 | 14 | 0 | 12 | 1 | 0 | 11 | 0 | 3442 | 2 | 3482 | ||
| 9 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 746 | 747 | ||
| R | 0.801622039 | 40976 |
Accuracy: 37285/40976 = 0.909922882
Overall Accuracy
数据预处理方法积累
dictionary.setdefault()
Python dictionary method setdefault() is similar to get(), but will set dict[key]=default if key is not already in dict.
注意, 只有当没有这个键值的时候才会被设置
数据集划分
1
X_train,X_test, y_train, y_test = sklearn.model_selection.train_test_split(train_data,train_target,test_size=0.4, random_state=0,stratify=y_train)
arrays:可以是列表、numpy数组、scipy稀疏矩阵或pandas的数据框
test_size:可以为浮点、整数或None,默认为None
①若为浮点时,表示测试集占总样本的百分比
②若为整数时,表示测试样本样本数
③若为None时,test size自动设置成0.25
train_size:可以为浮点、整数或None,默认为None
①若为浮点时,表示训练集占总样本的百分比
②若为整数时,表示训练样本的样本数
③若为None时,train_size自动被设置成0.75
random_state:可以为整数、RandomState实例或None,默认为None
①若为None时,每次生成的数据都是随机,可能不一样
②若为整数时,每次生成的数据都相同
stratify:可以为类似数组或None
①若为None时,划分出来的测试集或训练集中,其类标签的比例也是随机的
②若不为None时,划分出来的测试集或训练集中,其类标签的比例同输入的数组中类标签的比例相同,可以用于处理不均衡的数据集
npy文件存储与读取
import numpy as np
# .npy文件是numpy专用的二进制文件
arr = np.array([[1, 2], [3, 4]])
# 保存.npy文件
np.save("../data/arr.npy", arr)
print("save .npy done")
# 读取.npy文件
np.load("../data/arr.npy")
print(arr)
print("load .npy done")
虚拟样本增强
A. Changing Radiation-Based Virtual Samples
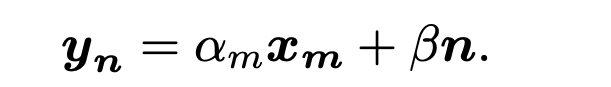
xB. Mixture-Based Virtual Samples
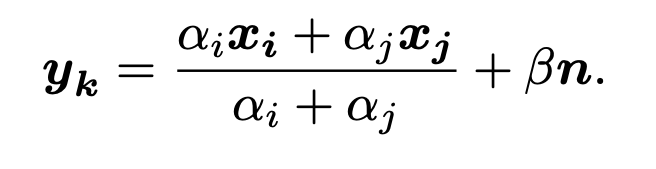
关于0label处理
找到了边缘标签错误的原因了:

如果center_pixel,则左上的测试集不会被预测,都会被预测为0.
理解:
应该是在训练的时候不对0label进行训练,但是预测的时候对0label进行预测看其最像哪一类 . 这样就不会影响准确率
待验证:
HSC源码作者:
我们在模型定义中使用的类别数量是实际类别数量加上一个(包括未定义的数据)。实际上,在监督训练过程中,训练数据中不包含未定义的数据,而定义模型的预测过程中包含了未定义的类别。
因此混淆矩阵包含一行所有零向量(实际上目标不包含未定义的类别),而预测包含实际类别数+1。
In my opinion,at main.py line 170 N_CLASSES = len(LABEL_VALUES) which include the undefined label . at model.py line 33 n_classes = kwargs[‘n_classes’] so our model try to learn actual classes+ 1categories. Take PU data as an example,the target is in [1,9],but the prediction is in [0,9].That why the confusion matrix looks like that. But ,in the get_model function we set
weights[torch.LongTensor(kwargs['ignored_labels'])] = 0. which pass to ‘criterion’ and it will not have influence on loss.
在我看来,main.py的第170行N_CLASSES = len(LABEL_VALUES),其中包括未定义的标签。在model.py的第33行n个class = kwargs[‘n classes’]中,我们的模型尝试学习实际的类+ 1个category。(类似预测未知样本????)以PU数据为例,目标在[1,9],而预测在[0,9]。这就是为什么混淆矩阵是这样的。但是,在get模型函数中我们设置了weights[torch.LongTensor(kwargs['ignored_labels'])] = 0。通过“criterion”,不会对损失产生影响。
正则化方法
Min-Max 归一化
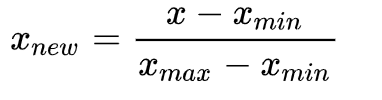
网络方法积累
网格搜索法(SVM_grid)
1
2
3
clf = sklearn.svm.SVC(class_weight=class_weight)
clf = sklearn.model_selection.GridSearchCV(clf, SVM_GRID_PARAMS, verbose=5, n_jobs=4) # Grid search function
clf.fit(X_train, y_train)
nn.conv3d()
1
class torch.nn.Conv3d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
1
2
3
4
5
6
7
8
in_channels(int) – 输入信号的通道,就是输入中每帧图像的通道数
out_channels(int) – 卷积产生的通道,就是输出中每帧图像的通道数
kernel_size(int or tuple) - 过滤器的尺寸,假设为(a,b,c),表示的是过滤器每次处理 a 帧图像,该图像的大小是b x c。
stride(int or tuple, optional) - 卷积步长,形状是三维的,假设为(x,y,z),表示的是三维上的步长是x,在行方向上步长是y,在列方向上步长是z。
padding(int or tuple, optional) - 输入的每一条边补充0的层数,形状是三维的,假设是(l,m,n),表示的是在输入的三维方向前后分别padding l 个全零二维矩阵,在输入的行方向上下分别padding m 个全零行向量,在输入的列方向左右分别padding n 个全零列向量。
dilation(int or tuple, optional) – 卷积核元素之间的间距,这个看看空洞卷积就okay了
groups(int, optional) – 从输入通道到输出通道的阻塞连接数;没用到,没细看
bias(bool, optional) - 如果bias=True,添加偏置;没用到,没细看
注意:
- kernel_size(int or tuple) - 过滤器的尺寸,假设为(a,b,c)中, a为通道数, 即深度. 同理stride, padding等等也是
- torch的输入x的形状是: [batch, 通道数, 光谱维数(深度), 宽度, 高度]

3D卷积核多通道卷积有什么区别呢?
多通道卷积不同的通道上的卷积核的参数是不同的,而3D卷积则由于卷积核本身是3D的,所以这个由于“深度”造成的看似不同通道上3D卷积用的就是同一个卷积,权重共享嘛。
总之,多了一个深度通道,这个深度可能是视频上的连续帧,也可能是立体图像中的不同切片。
x.view() 更改维度
注意:
要加上前面的一维
正则化方法
nn.LocalResponseNorm()-Local Response Normalization
在由几个输入平面组成的输入信号上应用本地响应归一化,其中通道占据第二维。跨通道应用标准化。 \(b_{c} = a_{c}\left(k + \frac{\alpha}{n} \sum_{c'=\max(0, c-n/2)}^{\min(N-1,c+n/2)}a_{c'}^2\right)^{-\beta}\)
网络层函数
keras - model.compile()
model.compile()方法用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准
1
2
3
model.compile(optimizer = 优化器,
loss = 损失函数,
metrics = ["准确率”])
其中:
optimizer可以是字符串形式给出的优化器名字,也可以是函数形式,使用函数形式可以设置学习率、动量和超参数例如:“sgd” 或者 tf.optimizers.SGD(lr = 学习率,
decay = 学习率衰减率,
momentum = 动量参数)
“adagrad” 或者 tf.keras.optimizers.Adagrad(lr = 学习率,
decay = 学习率衰减率)
”adadelta” 或者 tf.keras.optimizers.Adadelta(lr = 学习率,
decay = 学习率衰减率)
“adam” 或者 tf.keras.optimizers.Adam(lr = 学习率,
decay = 学习率衰减率)
loss可以是字符串形式给出的损失函数的名字,也可以是函数形式例如:”mse” 或者 tf.keras.losses.MeanSquaredError()
“sparse_categorical_crossentropy” 或者 tf.keras.losses.SparseCatagoricalCrossentropy(from_logits = False)
损失函数经常需要使用softmax函数来将输出转化为概率分布的形式,在这里from_logits代表是否将输出转为概率分布的形式,为False时表示转换为概率分布,为True时表示不转换,直接输出
Metrics标注网络评价指标例如:
“accuracy” : y_ 和 y 都是数值,如y_ = [1] y = [1] #y_为真实值,y为预测值
“sparse_accuracy“:y_和y都是以独热码 和概率分布表示,如y_ = [0, 1, 0], y = [0.256, 0.695, 0.048]
“sparse_categorical_accuracy” :y_是以数值形式给出,y是以 独热码给出,如y_ = [1], y = [0.256 0.695, 0.048]
keras - model.fit()
1
fit( x, y, batch_size=32, epochs=10, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0)
- x:输入数据。如果模型只有一个输入,那么x的类型是numpy array,如果模型有多个输入,那么x的类型应当为list,list的元素是对应于各个输入的numpy array
- y:标签,numpy array
- batch_size:整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步。
- epochs:整数,训练终止时的epoch值,训练将在达到该epoch值时停止,当没有设置initial_epoch时,它就是训练的总轮数,否则训练的总轮数为epochs - inital_epoch
- verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
- callbacks:list,其中的元素是keras.callbacks.Callback的对象。这个list中的回调函数将会在训练过程中的适当时机被调用,参考回调函数
- validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。注意,validation_split的划分在shuffle之前,因此如果你的数据本身是有序的,需要先手工打乱再指定validation_split,否则可能会出现验证集样本不均匀。
- validation_data:形式为(X,y)的tuple,是指定的验证集。此参数将覆盖validation_spilt。
- shuffle:布尔值或字符串,一般为布尔值,表示是否在训练过程中随机打乱输入样本的顺序。若为字符串“batch”,则是用来处理HDF5数据的特殊情况,它将在batch内部将数据打乱。
- class_weight:字典,将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练)
- sample_weight:权值的numpy array,用于在训练时调整损失函数(仅用于训练)。可以传递一个1D的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加了sample_weight_mode=’temporal’。
- initial_epoch: 从该参数指定的epoch开始训练,在继续之前的训练时有用。
fit函数返回一个History的对象,其History.history属性记录了损失函数和其他指标的数值随epoch变化的情况,如果有验证集的话,也包含了验证集的这些指标变化情况
自定义层 - pytorch.nn.Module()
几个必须:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Linear(nn.Module): # 必须继承nn.Module
def __init__(self, in_features, out_features):
super(Linear, self).__init__() # 必须调用nn.Module的构造函数,等价于nn.Module.__init__(self)
# 在构造函数__init__中必须自己定义可学习的参数,并封装成Parameter, 如此处的w和b
self.w = nn.Parameter(t.randn(in_features, out_features))
self.b = nn.Parameter(t.randn(out_features))
def forward(self, x):
x = x.mm(self.w) # x.@(self.w)
return x + self.b.expand_as(x)
layer = Linear(4,3)
input = t.randn(2,4)
output = layer(input) # 调用layer(input)即可得到input对应的结果。它等价于`layers.__call__(input)`,在`__call__`函数中,主要调用的是 `layer.forward(x)`
output
nn.Parameter
Build Parameter matrix like weight or bias
parameter是一种特殊的Tensor,但其默认需要求导(requires_grad = True),感兴趣的读者可以通过nn.Parameter??,查看Parameter类的源代码。
forward() - 前项传播函数
实现前项传播过程, 构建所有层, 输入是一个或多个tensor, 最终返回结果
无需写反向传播函数,nn.Module能够利用autograd自动实现反向传播,这点比Function简单许多。
使用时,直观上可将layer看成数学概念中的函数,调用layer(input)即可得到input对应的结果。它等价于layers.__call__(input),在__call__函数中,主要调用的是 layer.forward(x),另外还对钩子做了一些处理。所以在实际使用中应尽量使用layer(x)而不是使用layer.forward(x),关于钩子技术将在下文讲解。
named_parameters()
Module中的可学习参数可以通过named_parameters()或者parameters()返回迭代器,前者会给每个parameter都附上名字,使其更具有辨识度。
Module
可见利用Module实现的全连接层,比利用Function实现的更为简单,因其不再需要写反向传播函数。
这些自定义layer对输入形状都有假设:输入的不是单个数据,而是一个batch, 则必须调用tensor.unsqueeze(0) 或 tensor[None]将数据伪装成batch_size=1的batch
子Module
Module能够自动检测到自己的Parameter,并将其作为学习参数。除了parameter之外,Module还包含子Module,主Module能够递归查找子Module中的parameter。下面再来看看稍微复杂一点的网络,多层感知机。
构造函数__init__中,可利用前面自定义的Linear层(module),作为当前module对象的一个子module,它的可学习参数,也会成为当前module的可学习参数。
Sequential ???
1
return nn.Sequential(*layers)
权重初始化方法
1
2
3
4
5
6
7
8
@staticmethod
def weight_init(m):
if isinstance(m, nn.Linear) or isinstance(m, nn.Conv3d):
init.kaiming_uniform_(m.weight)
init.zeros_(m.bias)
# 网络权重初始化方式
self.apply(self.weight_init) # ???
并行模块拼接方式— torch.cat()
1
2
3
4
5
def forward(self, x):
# Inception module
x_3x3 = self.conv_3x3(x)
x_1x1 = self.conv_1x1(x)
x = torch.cat([x_3x3, x_1x1], dim=1) # 两个并行模块的拼接方式